Text-to-image Architecture
1. PixArt-
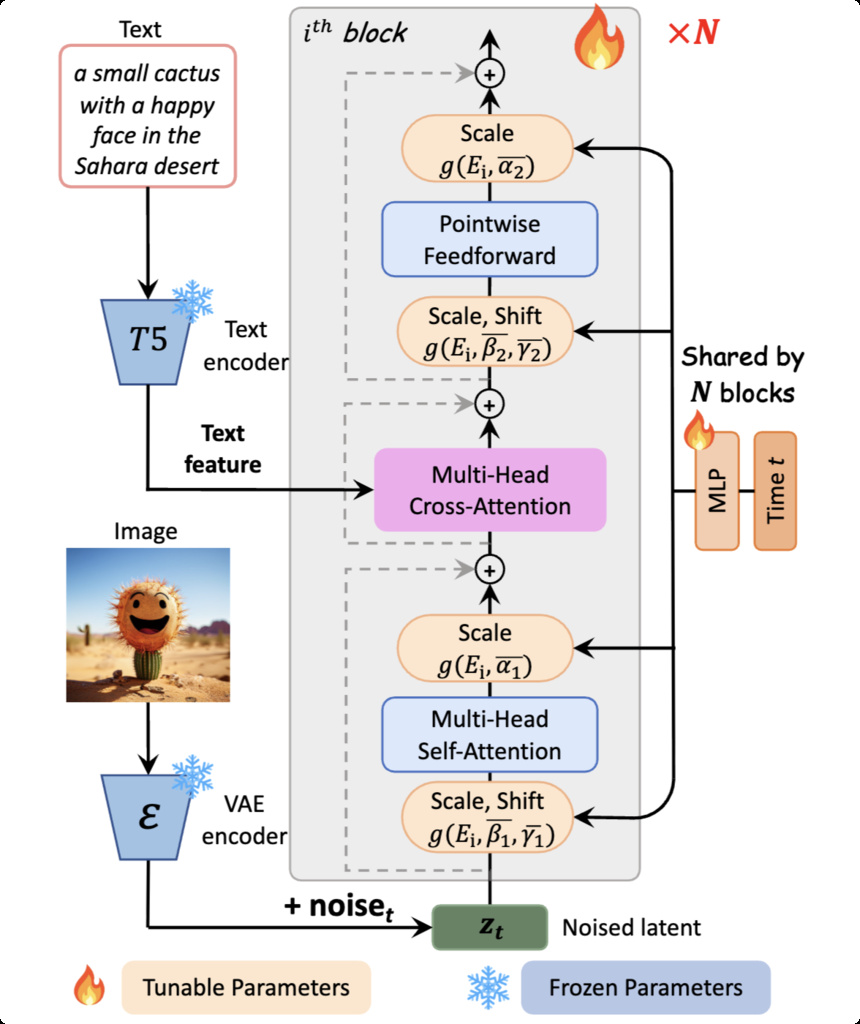
PixArt- variant augments DiT with a cross-attention mechanism inserted between the self-attention and feed-forward layers. This design allows for a more direct fusion of visual and textual features, improving alignment between generated images and conditioning prompts.
PixArt- also introduces a refined normalization strategy using a single shared Adaptive LayerNorm (AdaLN) configuration. Rather than maintaining separate adaptive normalization parameters in each block, as in the original DiT, a single global set of scale and shift parameters is derived from the timestep embedding and shared across layers. This reduces redundancy and overall parameter count while preserving flexibility through lightweight, per-block embeddings.
2. MMDiT

Unlike PixArt-, where text conditioning is injected via cross-attention into an image-only backbone, MMDiT maintains two parallel token streams—one for text and one for image features—throughout the network. Each stream has its own normalization, modulation, and feed-forward layers, but they share a common attention mechanism that enables full bidirectional communication between modalities.
During attention computation, queries, keys, and values are drawn from both text and image tokens, allowing each modality to attend to the other. Each stream retains its own AdaLN parameters, modulated by timestep and modality embeddings to ensure consistent diffusion conditioning across domains.
This design allows MMDiT to capture cross-modal dependencies more explicitly than single-stream architectures, albeit with higher memory consumption and computational cost.
3. DiT-Air
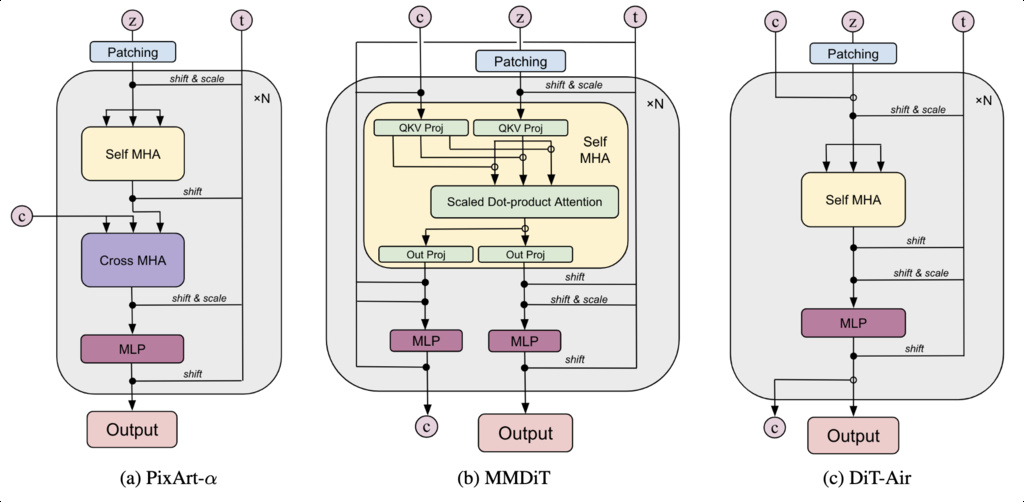
DiT-Air is a hybrid architecture that bridges the gap between DiT and MMDiT, combining the simplicity of a single-stream Transformer with the expressive multimodal interactions of dual-stream designs.
Unlike MMDiT, which maintains separate streams for text and image tokens that communicate through shared attention, DiT-Air operates on a unified token sequence where both modalities coexist within a single stream. It retains the AdaLN mechanism from DiT, ensuring that temporal and conditioning information are consistently integrated throughout the network.
4. U-ViT
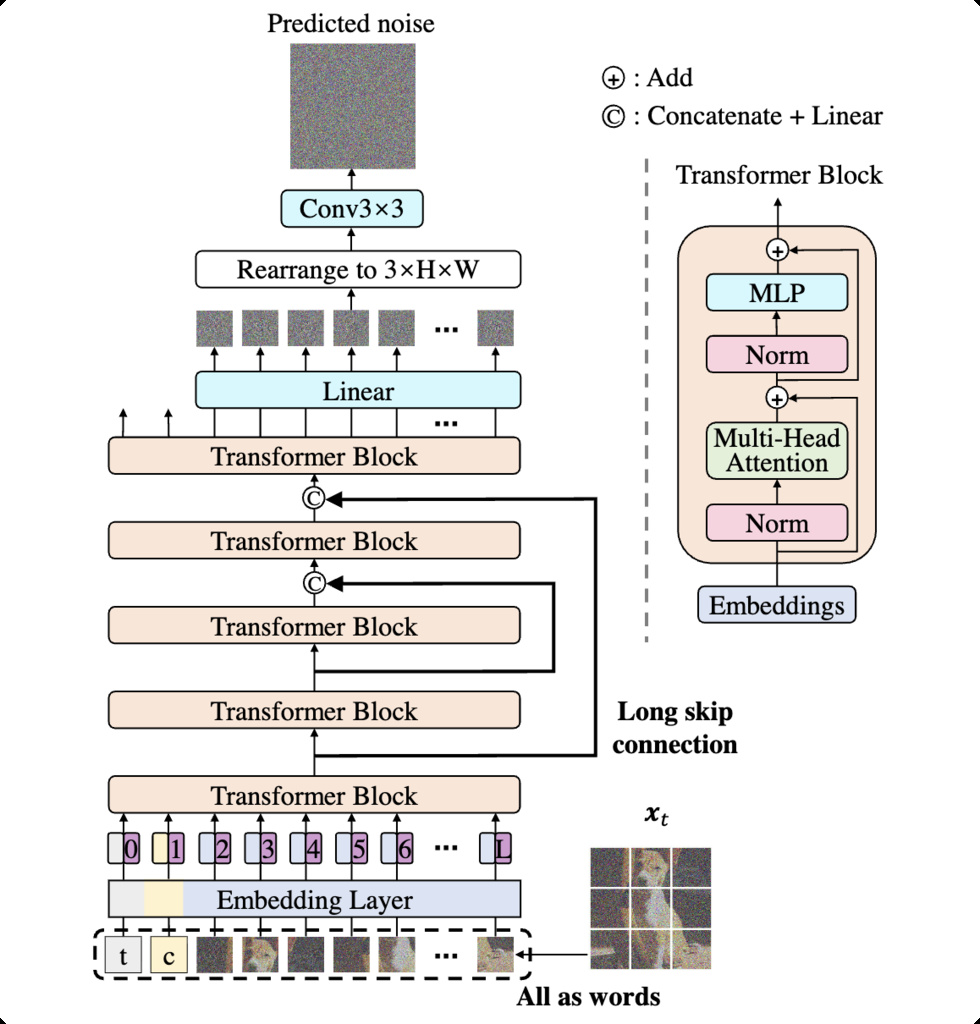
The U-shaped Vision Transformer (U-ViT) adopts a topology reminiscent of the classic U-Net architecture but is implemented entirely with Transformer blocks. Its encoder and decoder stacks are connected through long skip connections, allowing low-level spatial features from shallow layers to be concatenated and projected into deeper layers for improved reconstruction quality.
Like DiT-Air, U-ViT operates on a unified token sequence, where visual and conditioning tokens are processed jointly through self-attention. However, it removes adaptive normalization mechanisms altogether—there is no AdaLN or per-layer modulation. Instead, conditioning information such as timestep and text embeddings is directly concatenated to the input token sequence, allowing the Transformer to reason jointly over image patches, time tokens, and text tokens within a single attention space.
This design makes U-ViT conceptually simple and elegant, combining the global context modeling of Transformers with the hierarchical structure of encoder-decoder architectures.
5. PRX
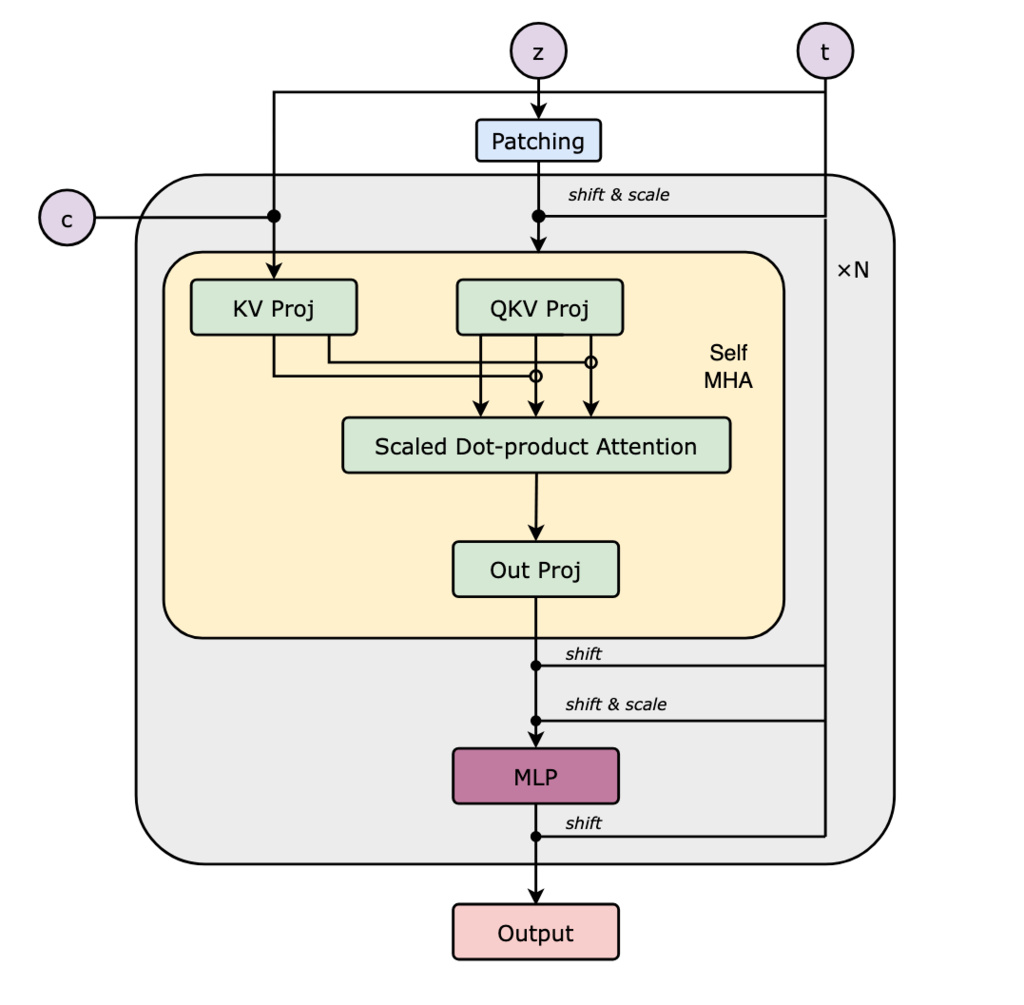
PRX (Photoroom eXperimental) is a hybrid design that combines features of both single-stream and dual-stream Transformers. PRX receives both image and text tokens as inputs but is designed to output only image tokens, focusing computation on the generative pathway.
Each PRX block receives text tokens directly from the text encoder, similar to PixArt-α. However, unlike typical cross-attention or dual-stream setups, PRX processes image and text tokens independently before concatenating them for the self-attention operation. Attention is then computed only for the image tokens, reducing both computational and memory cost.
This design is closely related to the self-attention DiT shallow-fusion baseline introduced in Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis. By avoiding explicit text-token updates, PRX performs a single attention operation (rather than two, as in standard DiTs) and maintains a smaller attention matrix than MMDiT, where cross-modal attention scales with the product of text and image token counts.
Motivated by the observation that text tokens remain static across diffusion timesteps, PRX omits timestep modulation for the text stream. Since text tokens are unmodified, they can be projected once at inference time and cached, eliminating redundant computation at each step and substantially accelerating generation.