On-Policy Distillation
There are two main type of distillation: off-policy and on-policy. Off-policy distillation trains a student model on fixed data (typically the teacher’s precomputed logits or text completions), while on-policy distillation involves the teacher providing feedback to the student’s own outputs.
1. Off-policy vs. on-policy distillation
The core idea of on-policy distillation is to sample trajectories from the student model and use a high-performing teacher to grade each token of each trajectory.
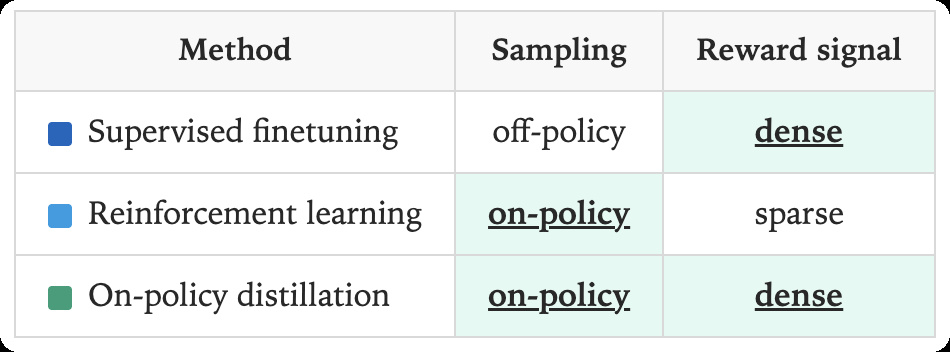
On-policy distillation's advantage is twofold. First, as the student model improves, its generations create progressively higher-quality training data, forming a positive feedback loop. Second, this “context alignment” forces the student to learn from the same types of errors and successes it will encounter during inference, rather than from completions generated only by the teacher.
Generalised Knowledge Distillation (GKD) unifies these approaches under a common framework by supporting a range of loss functions that enable training on both static teacher data and trajectories generated by the student.
where is the supervised distillation (SD) that leverages off-policy generations from the teacher and is the on-policy distillation (OD) using student generations and feedback from the teacher's logits.
2. Universal Logit Distillation (ULD)
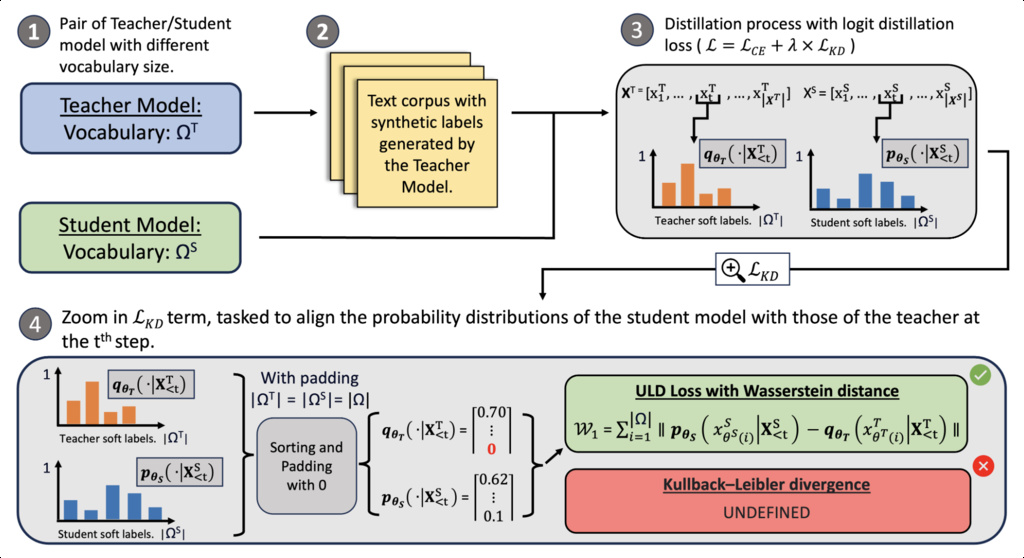
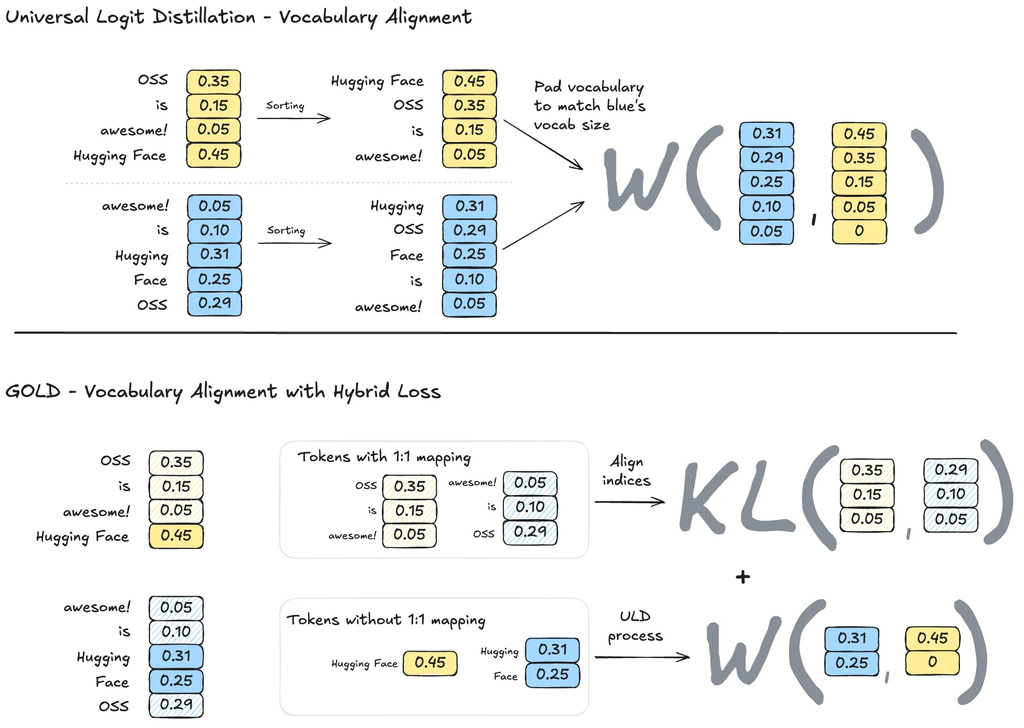
ULD showed that using distillation between models with different tokenizers introduces two key challenges:
- Sequence misalignment: tokenizers split text differently.
- Vocabulary misalignment: the same token string receives different IDs.
ULD handles these issues by truncating sequences to the minimum length and by sorting and padding the smaller softmax vector to align vocabularies.
ULD lifts the tokenizer restriction but remains limited to offline setups. Next, we introduce our core contribution, General On-Policy Logit Distillation (GOLD), which extends ULD into the on-policy setting with improved alignment techniques.
3. General On-Policy Logit Distillation (GOLD)
3.1. Sequence Alignment
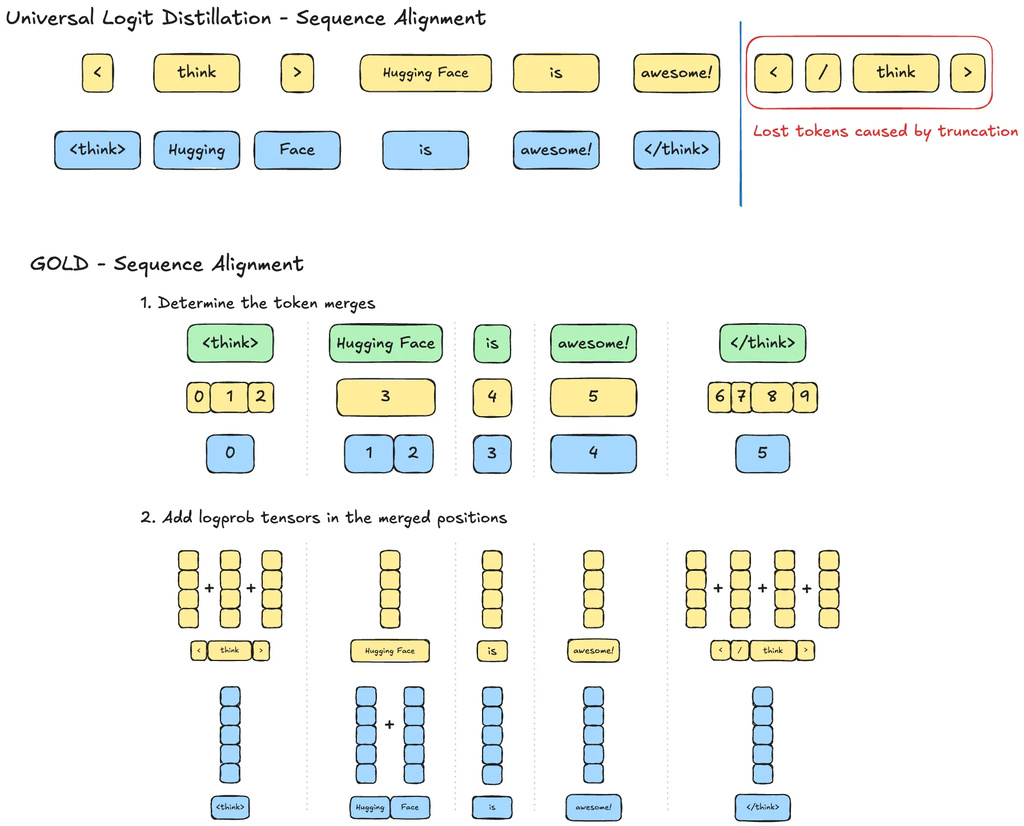
The first limitation we address is ULD’s sequence alignment, which simply truncates sequences to the minimum tokenized length. This simple approach causes two problems:
It leads to information loss at the end of the text. It can misalign tokens, causing the distillation of tokens with different semantic meanings at the same sequence index. This alignment error worsens as tokenization differences increase because a single mismatch at the start of a sequence can propagate and create a cascading semantic error throughout the text.
Instead of truncating, our method identifies the token merges required to equalise the sequence lengths for both tokenizers. We then merge the logits at the corresponding positions by summing their log probabilities. This sum, which represents the log of the joint probability for the merged tokens, is then passed through a softmax.
We perform the token merge through summing the log probabilities to leverage the autoregressive nature of LLM sampling. Following the example in Figure 3, we want to merge “Hugging” and “ Face” into one token for the sequence in blue. Using the conditional probabilities and the product rule2, we can merge the probabilities and guarantee sequence alignment regardless of tokenizer discrepancies in the sequence dimension.
3.2. Vocabulary Alignment
Our second extension improves the alignment in the vocabulary dimension by replacing the sorting operation with an operation that leverages a potential one-to-one mapping between the tokenizers. ULD assumes that we cannot map any token between tokenizers, so it performs a sorting operation in the softmax dimension after padding the logits to have the same size. The assumption behind this process is that the softmax distribution is the same, or at least similar, under a different permutation of token IDs.
We find this assumption to be reasonable, but we can exploit tokens present in both vocabularies with a different ID to avoid relying on sorting when there’s a direct mapping.