Spatial Reasoning
| Benchmark and Dataset | Description | Number | Source | Illustration |
| MINDCUBE (yin2025spatial) | MINDCUBE evaluates how well VLMs can build spatial mental models1 from limited views, and proposes a "map-then-reason" approach that improves VLM performance through the generation and utilization of internal structured spatial representations. | 21,154 questions across 3,268 images | ArkitScenes, DL3DV10K, WildRGB-D |
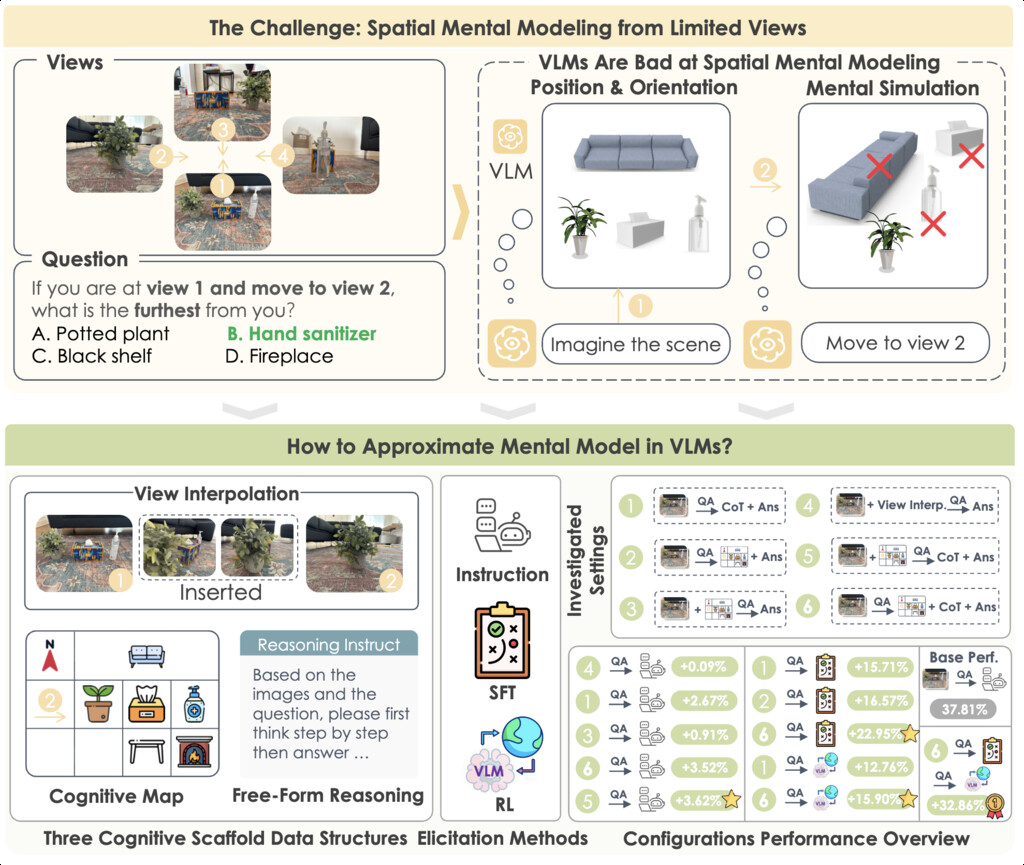 |
| SPAR (zhang2025flatland) | Spatial Perception And Reasoning (SPAR) dataset is sourced from 4,500 scenes and comprises 33 spatial tasks spanning single-view, multi-view, and video settings. | SPAR-7M: over 7 million QA pairs across 33 diverse spatial tasks, generated from 4,500+ richly annotated 3D indoor scenes SPAR-Bench: 7,207 manually verified QA pairs |
ScanNet, ScanNet++, Matterport3D, Structured3D |
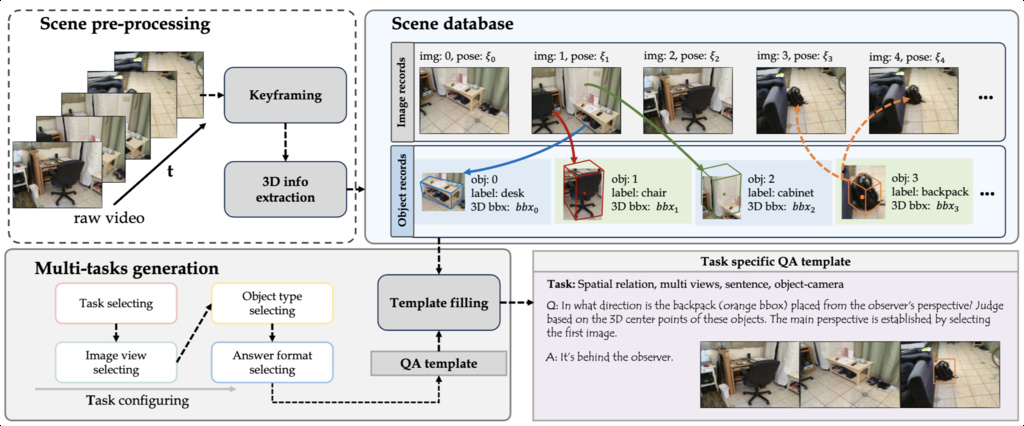 |
| EASI (cai2025holistic) | Six Fundamental Capabilities: Metric Measurement (MM); Mental Reconstruction (MR); Spatial Relations (SR); Perspective-taking (PT); Deformation and Assembly (DA); Comprehensive Reasoning (CR) | assembled from eight benchmark datasets, approximately 31K images, 4.5K videos, and 24K QA in total. | eight benchmark datasets |
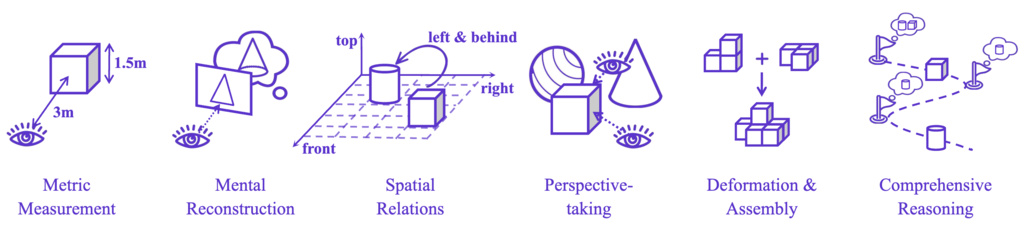 |
| VSTemporalI-Bench (fan2025vlm) | VLMs that incorporates 3D Reconstructive instruction tuning using videos | Training data: Over 200,000 general question-answer pairs for spatial reasoning from monocular video. VSTI-Bench: approximately 138,600 QA pairs. |
ScanNet, ScanNet++, ARKitScenes |
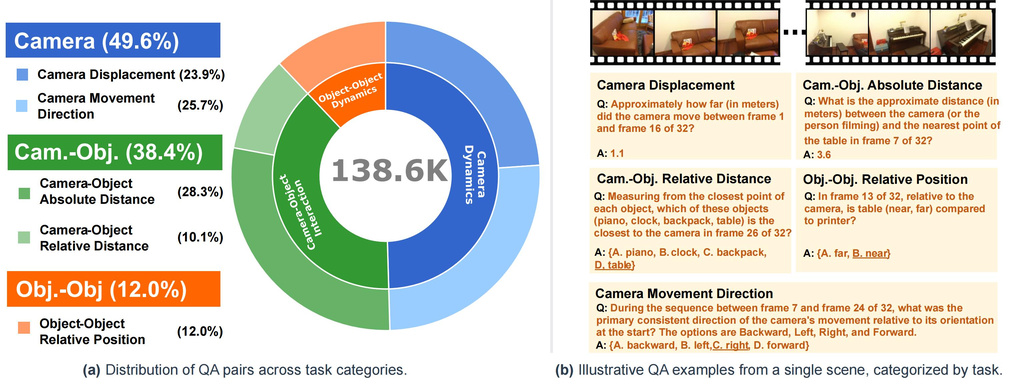 |
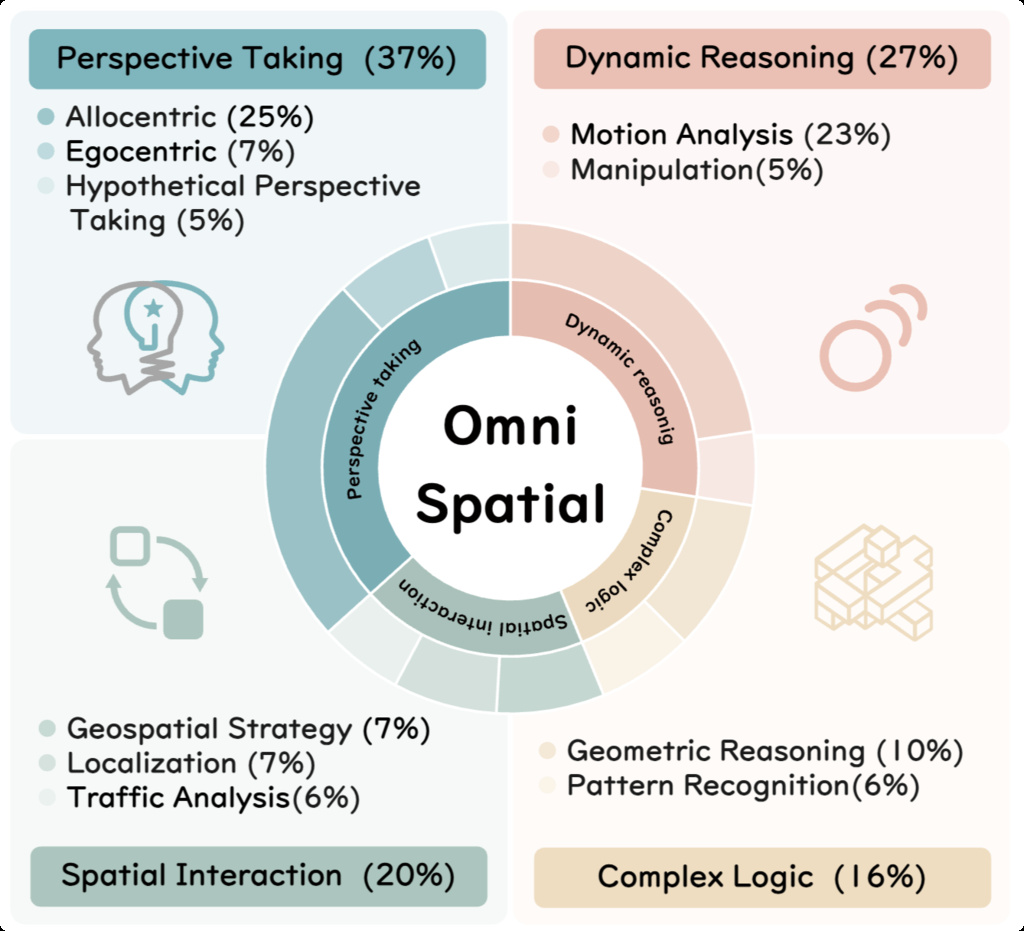
| OmniSpatial (jia2025omnispatial) | OmniSpatial covers four major categories: dynamic reasoning, complex spatial logic, spatial interaction, and perspective-taking, with 50 fine-grained subcategories | over 8.4K question-answer pairs | Internet |
 |
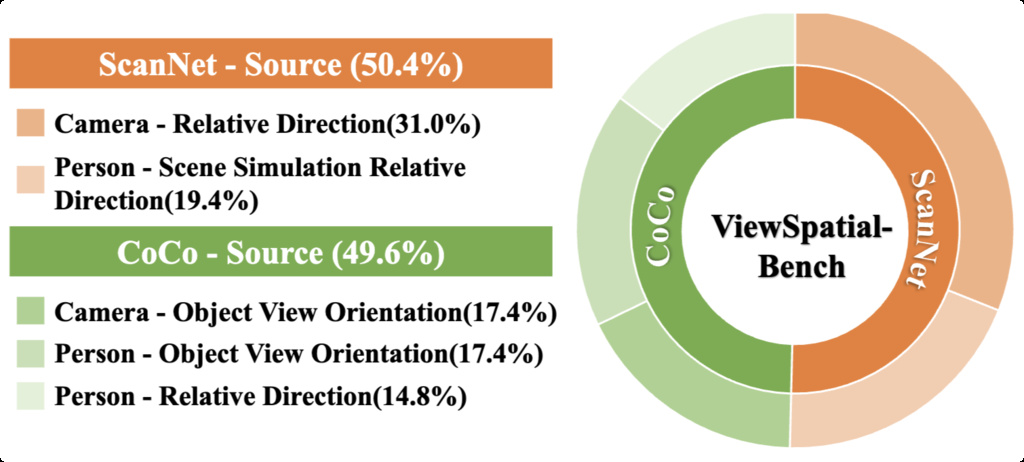
| ViewSpatial-Bench (li2025viewspatial) | Multi-viewpoint spatial localization recognition evaluation across five distinct task types, supported by an automated 3D annotation pipeline that generates precise directional labels. | 5,712 question-answer pairs across 1,000+ 3D scenes | MS-CoCo, ScanNet |
 |
| VSI-Bench (yang2025thinking) |
How models see, remember, and recall spaces  |
5130 question-answer pairs derived from 288 real videos | ScanNet, ScanNet++, ARKitScenes |
 |
| OST-Bench (lin2025ost) | Evaluating the online spatio-temporal reasoning capabilities of MLLMs. | test: 1.4k scenes and 10k question-answer pairs train: 7k scenes and 50k question-answer pairs |
ScanNet, Matterport3D, ARKitScenes |
 |
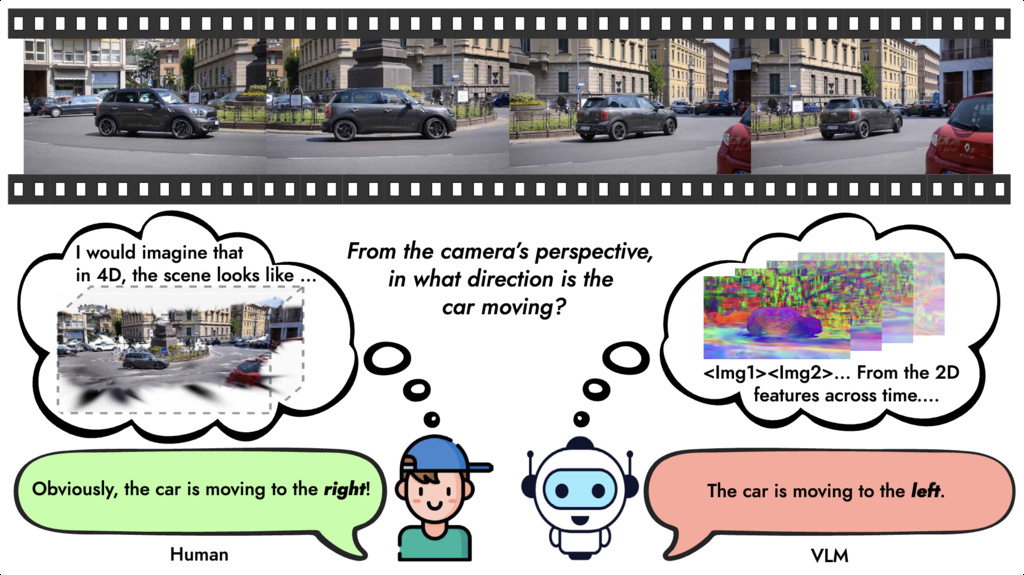
| VLM4D (zhou2025vlm4d) | Evaluate the spatiotemporal reasoning capabilities | 1000 videos paired with over 1800 question-answer pairs | exo-centric videos: DAVIS, YouTube-VOS ego-centric videos: Ego4D; synthetic videos: Cosmos |
 |
| STARE (li2025unfolding) | Spatial Transformations and Reasoning Evaluation | around 4k | Objectron, HM3D |
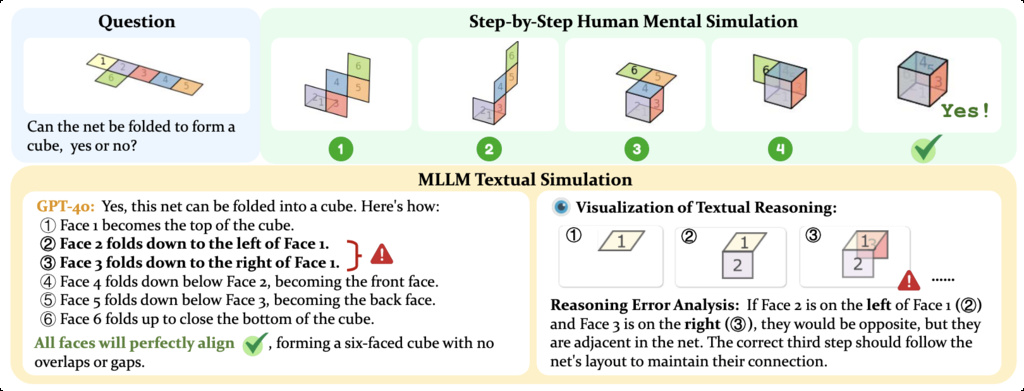 |
| Spatial-SSRL-81k (liu2025spatial) | A self-supervised RL paradigm that derives verifiable signals directly from ordinary RGB or RGB-D images | 81,053 QA | raw RGB images from COCO and RGB-D images from DIODE and MegaDepth |
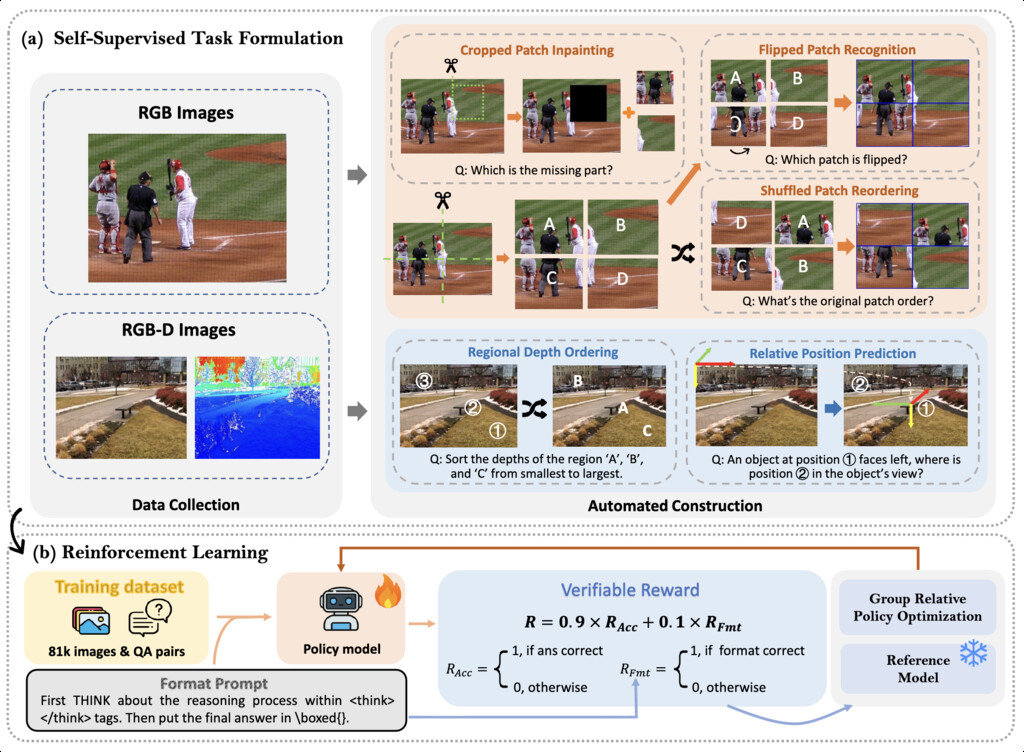 |
| SpatialViz-Bench (wang2025spatialviz) | A benchmark for spatial visualization with 12 tasks across 4 sub-abilities (Mental Rotation, representing and rotating two-dimensional and three-dimensional objects in space mentally while maintaining object features; 2) Mental Folding, folding two-dimensional patterns into three-dimensional objects or unfold three-dimensional objects into two-dimensional representations; 3) Visual Penetration, imagining the internal structure of objects based on external features; 4) Mental Animation) | 1,180 programmatically generated problems | synthetic data |
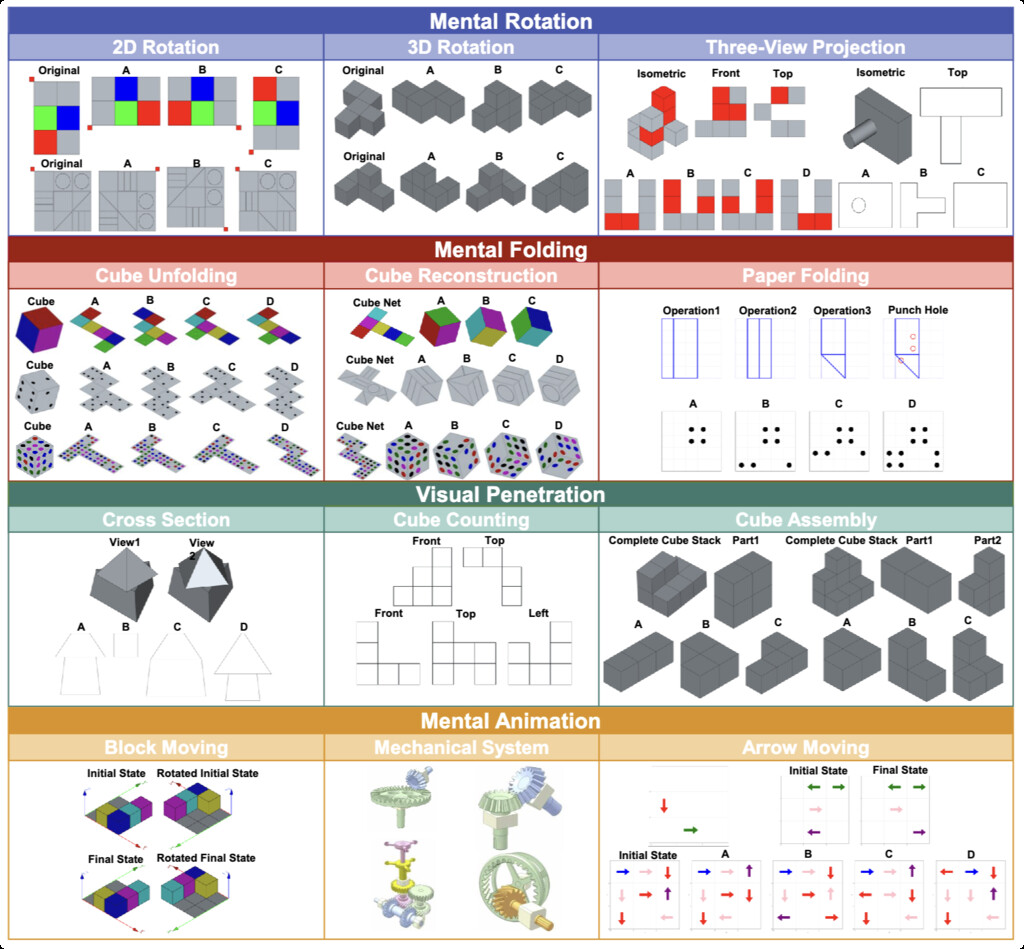 |
| MMSI-Bench (yang2025mmsi) | Multi-image spatial reasoning | 1,000 multiple choice questions | manually collect |
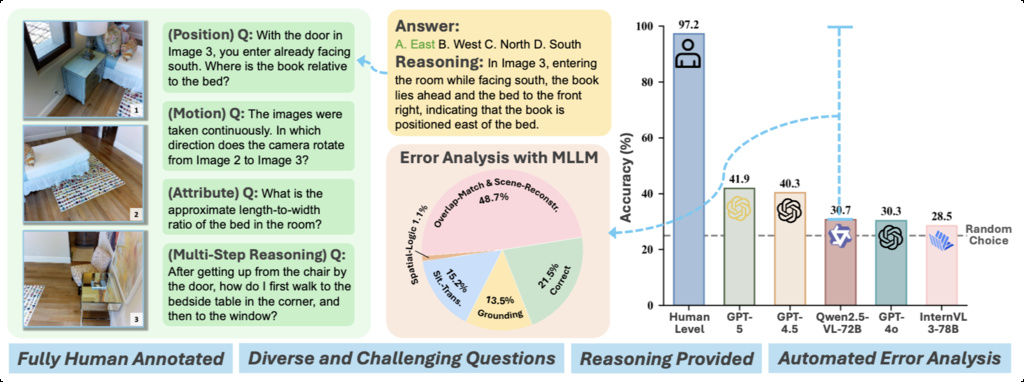 |
| LEGO-Puzzles (tang2025lego) | A scalable benchmark designed to evaluate both spatial understanding and sequential reasoning in MLLMs through LEGO-based tasks. | 1,100 carefully curated VQA samples spanning 11 distinct tasks | Internet |
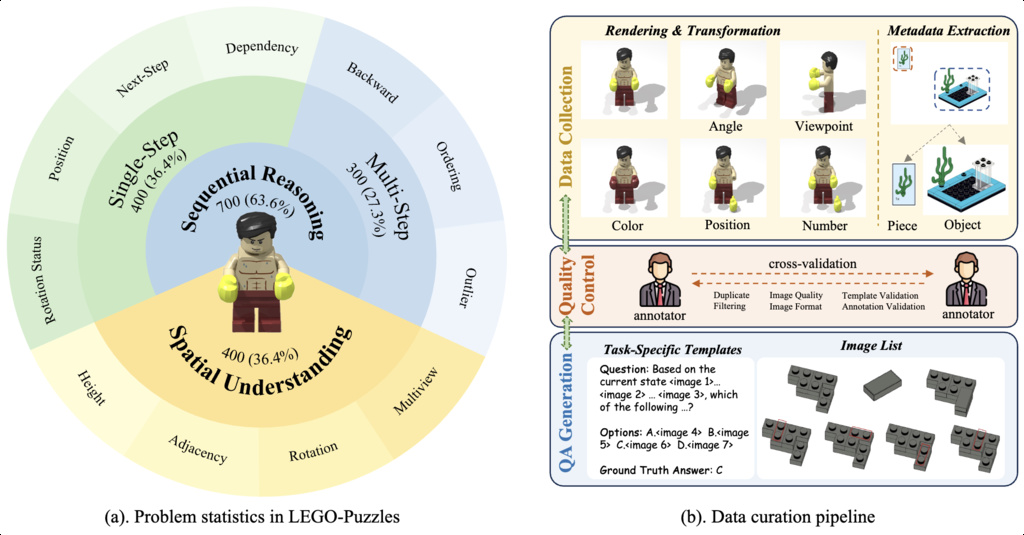 |
| ERQA (team2025gemini) | Embodied Reasoning Question Answering (ERQA) benchmark focuses specifically on capabilities likely required by an embodied agent interacting with the physical world. | 400 multiple choice VQA | OXE, UMI, MECCANO, HoloAssist, and EGTEA Gaze+ |
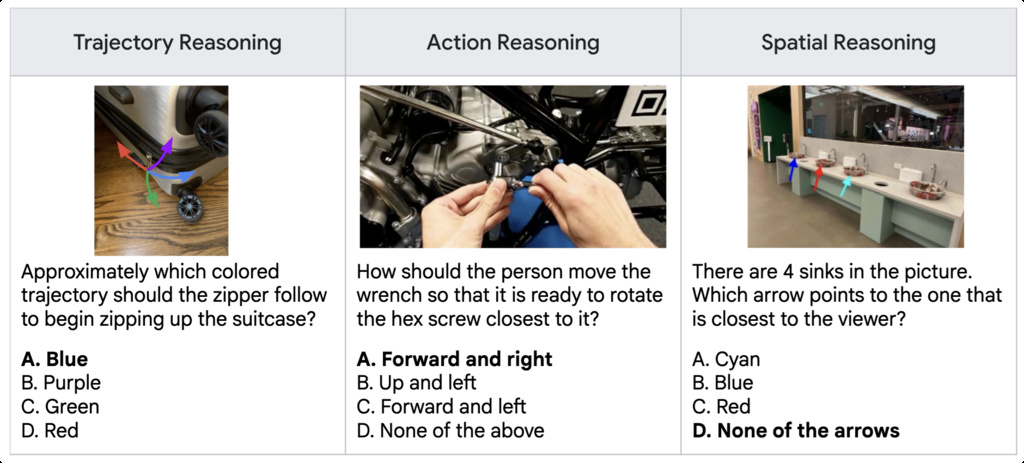 |
| MultiSPA (xu2025multi) | Equip MLLMs with robust multi-frame spatial understanding by integrating depth perception, visual correspondence, and dynamic perception | 27 million samples spanning diverse 3D and 4D scenes | Aria Digital Twin (ADT), Panoptic Studio (PStudio), TAPVid3D, ScanNet |
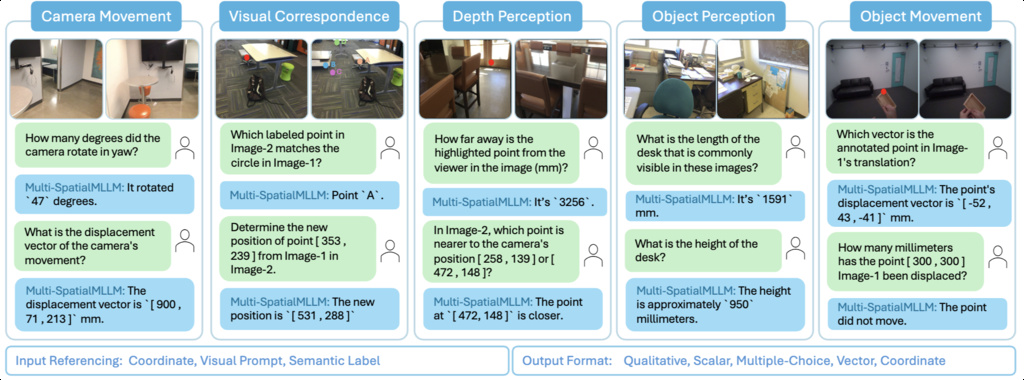 |
| SITE (wang2025site) | Spatial Intelligence Thorough Evaluation | 8068 multi-choice VQA | 31 computer vision datasets |
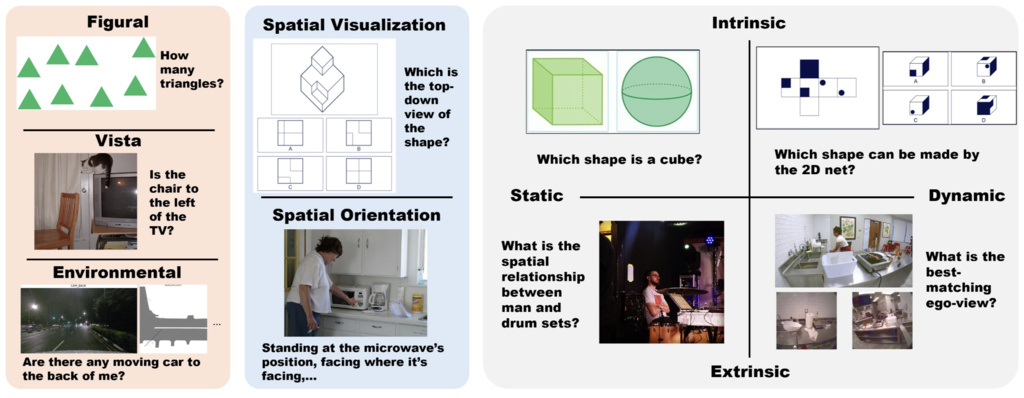 |
| 3DSRBench (ma20253dsrbench) | A Comprehensive 3D Spatial Reasoning Benchmark | 2,772 visual question-answer pairs | MS-COCO, HSSD |
 |
| SpatialEval (wang2024is) | Spatial-Map,Maze-Nav, Spatial-Grid, and Spatial-Real | Text-only (TQA): 4640 Vision-only (VQA): 4640 Vision-Text (VTQA): 4640 | synthetic, Densely Captioned Images (DCI) |
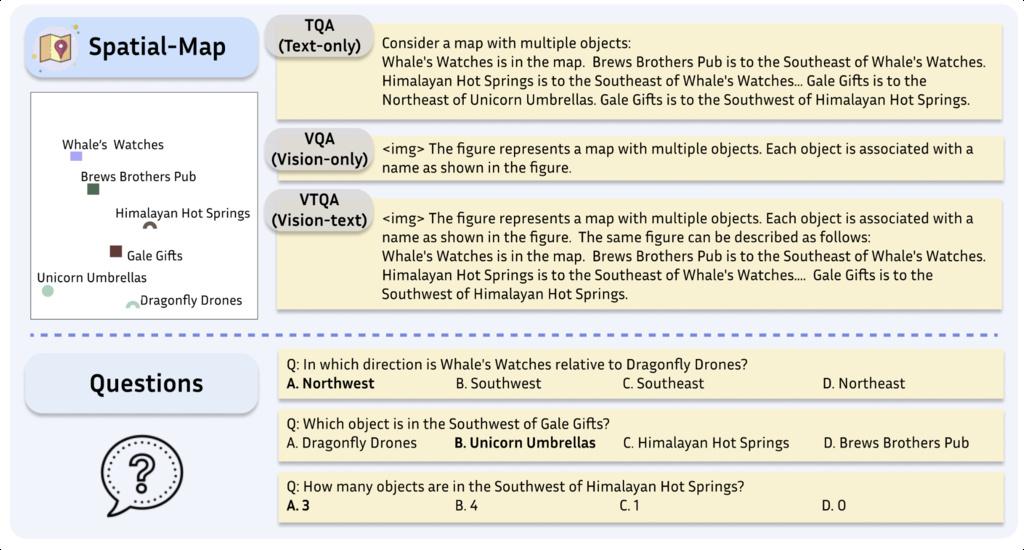 |
| DSI-Bench (zhang2025dsi) | Dynamic Spatial Intelligence | nearly 1,000 dynamic videos and over 1,700 manually annotated questions | Kinetics-700, the synthetic motion-control dataset, LLaVA-178K, additional online sources. |
 |
| VST (yang2025visual) | Visual Spatial Tuning | VST-Perception (VST-P): 4.1 M samples across 19 different tasks; VST-Reasoning (VST-R): 135K samples | open-source datasets |
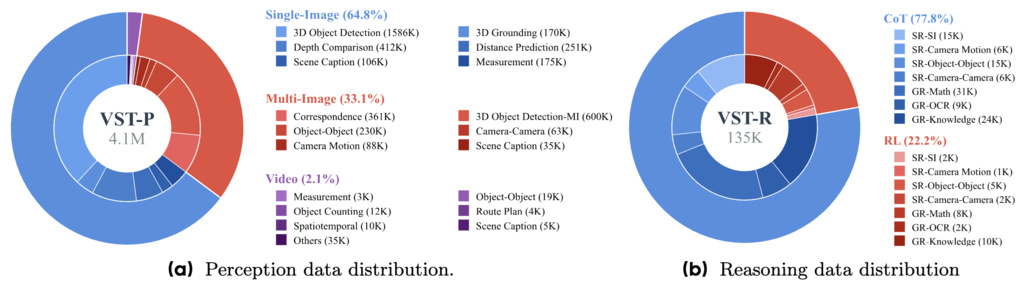 |
| SAT (ray2025sat) | A simulated spatial aptitude training dataset comprising both static and dynamic spatial reasoning | 175K question-answer (QA) pairs and 20K scenes | ProcTHOR-10K |
 |
| CoVT (qin2025chain) | Enables VLMs to reason not only in words but also through continuous visual tokens | 774.6k | LLaVA-OneVision, TallyQA and ADE20K-Depth |
 |
| MSMU (chen2025sd) | Massive Spatial Measuring and Understanding (MSMU) dataset with precise spatial annotations | 700K QA pairs, 2.5M physical numerical annotations, and 10K chain-of-thought augmented samples | ScanNet, ScanNet++ |
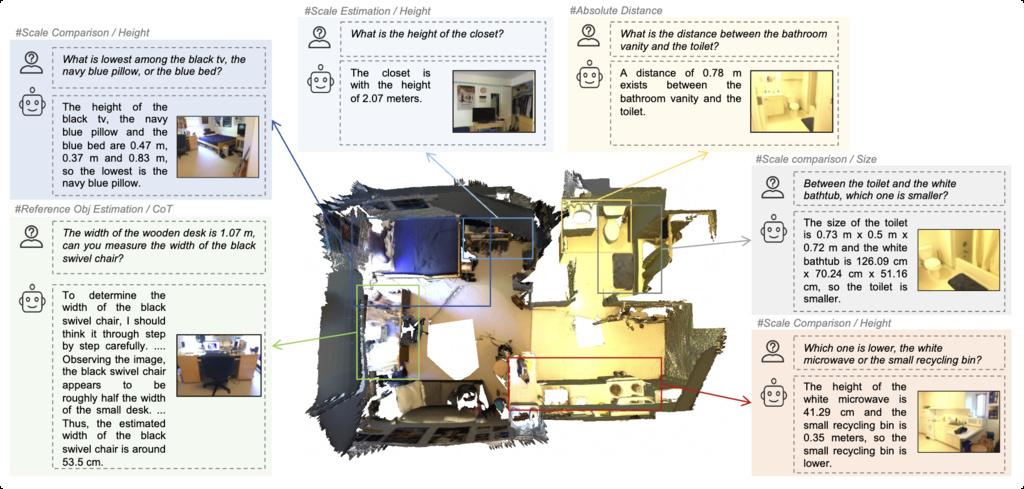 |
| What'sUp (kamath2023what) | Contains sets of photographs varying only the spatial relations of objects, keeping their identity fixed | 4,138 | COCO,GQA |
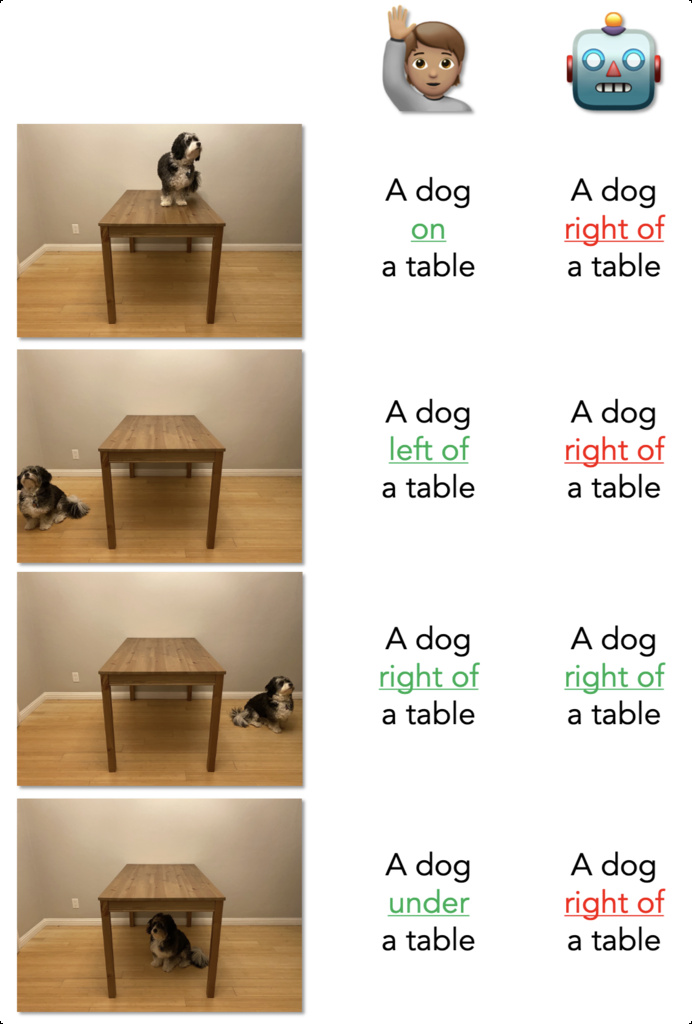 |
| RoboSpatial (song2025robospatial) | A large-scale dataset for spatial understanding in robotics | 1M images, 5k 3D scans, and 3M annotated spatial relationships | Matterport3D, ScanNet, 3RScan, HOPE, GraspNet-1B |
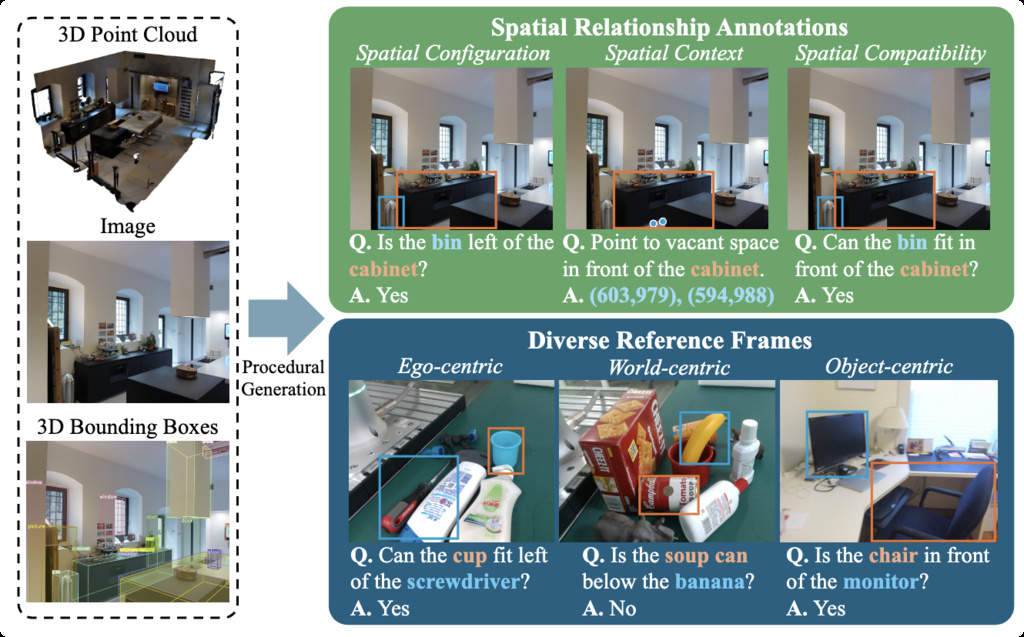 |
| Spatial-MM (shiri2024empirical) | Benchmark for spatial understanding and reasoning capabilities | Spatial-Obj: 2,000 multiple-choice questions; Spatial-CoT: 310 spatial-aware multi-hop QA pairs | Internet |
 |
| Super-CLEVR-3D (wang20233d) | 3D-aware VQA, which focuses on challenging questions that require a compositional reasoning over the 3D structure of visual scenes | 30k images | Super-CLEVR |
 |
| SpatialQA (cai2024spatialbot) | Multi-level depth related questions spanning various scenarios and embodiment tasks | 852,869 | Bunny 695k, Open X-Embodiment |
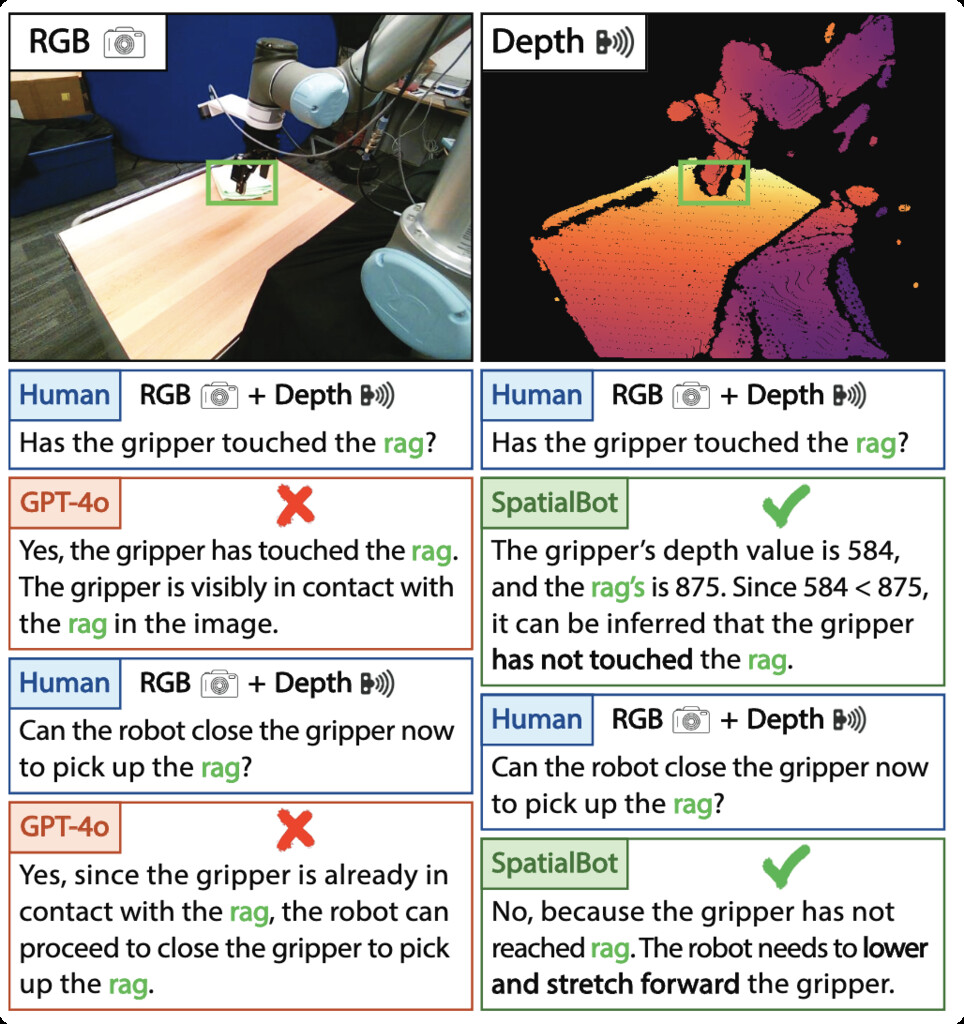 |
| SURDS (guo2024surds) | Benchmarking Spatial Understanding and Reasoning in Driving Scenarios | 41,080 vision–question–answer training instances and 9,250 evaluation samples | nuScenes |
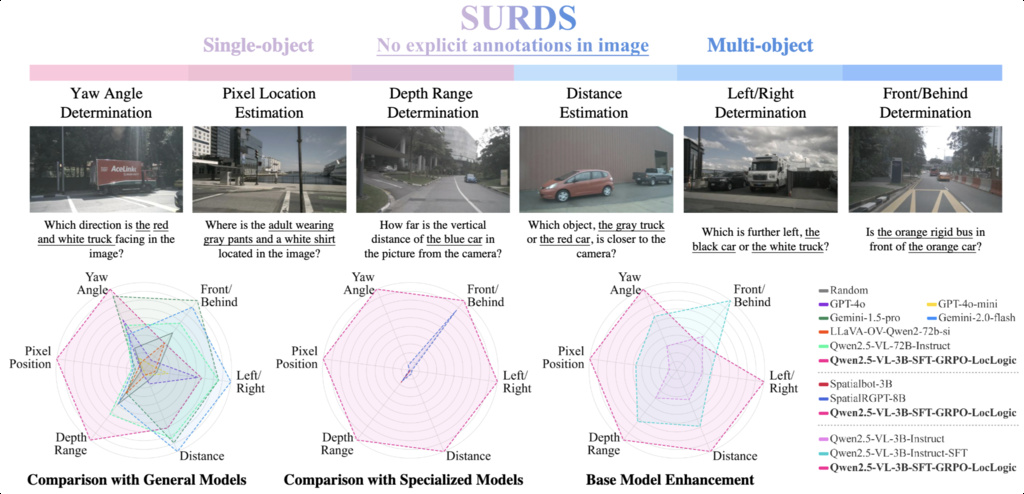 |
| Open3D-VQA (zhang2025open3d) | Evaluating MLLMs' ability to reason about complex spatial relationships from an aerial perspective | 73k QA pairs spanning 7 general spatial reasoning tasks | synthetic data |
 |
| RefSpatial (zhou2025roborefer) | Spatial referring | 2.5M high-quality examples with 20M QA pairs (2 prior), covering 31 spatial relations (vs. 15 prior) and supporting complex reasoning processes (up to 5 steps | OpenImages, CA-1M, Infinigen |
 |
| SSR-COT (liu2025ssr) | A million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations | 1.2M | LLaVA-CoT, Visual-CoT, VoCoT, SpatialQA |
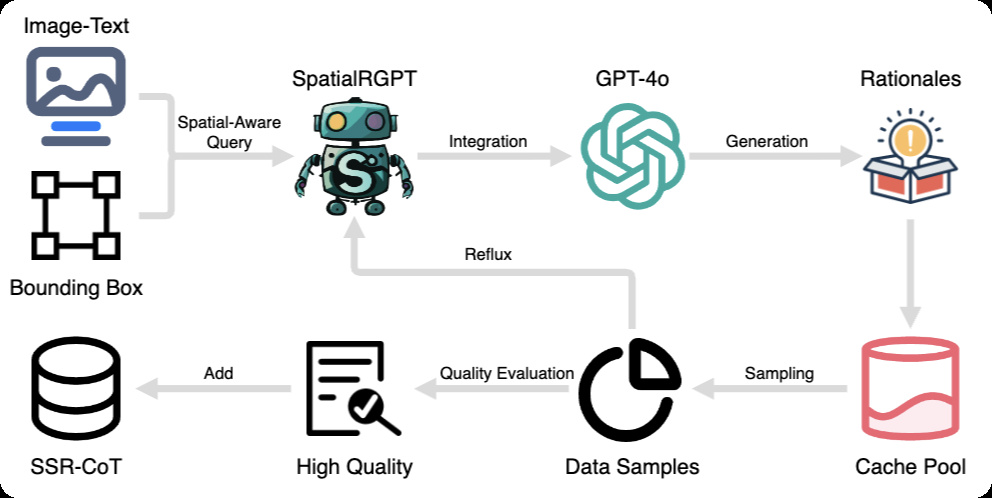 |
| SpaceR-91k (ouyang2025spacer) | A tailored spatial reasoning dataset built upon the 3D indoor scene reconstruction dataset ScanNet | 91k questions spanning diverse spatial reasoning scenarios with verifiable answers | ScanNet |
 |
| MulSeT (zhang2025why) | Multi-view Spatial Understanding Tasks | 38.2k question-answer pairs spanning more than 5,000 unique 3D scenes | AI2THOR |
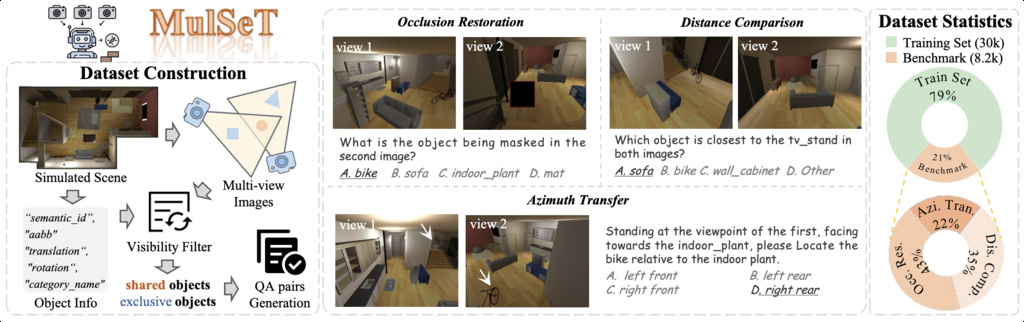 |
| Spartun3D (zhang2024spartun3d) | Incorporates various situated spatial reasoning tasks | 10k situated captions and 123k QA pairs. | 3RScan |
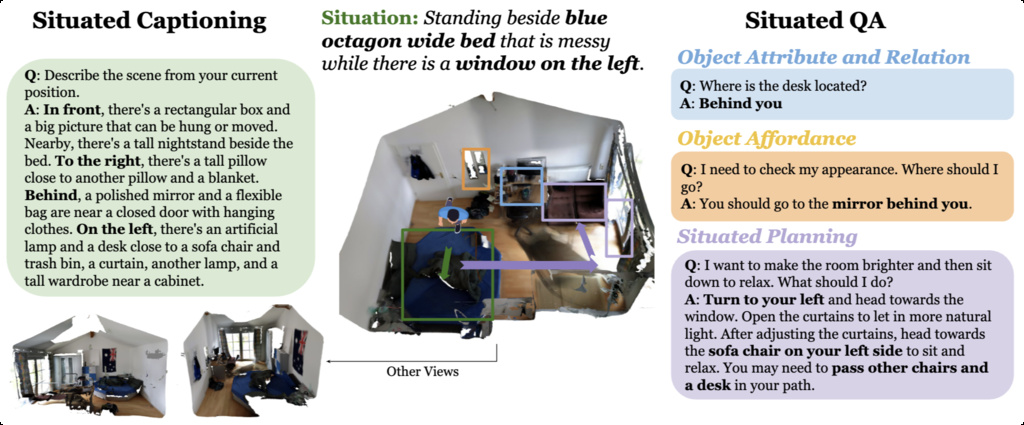 |
| MSQA (linghu2024multi) | 3D situated reasoning | 251K situated QA pairs | ScanNet, 3RScan, ARKitScenes |
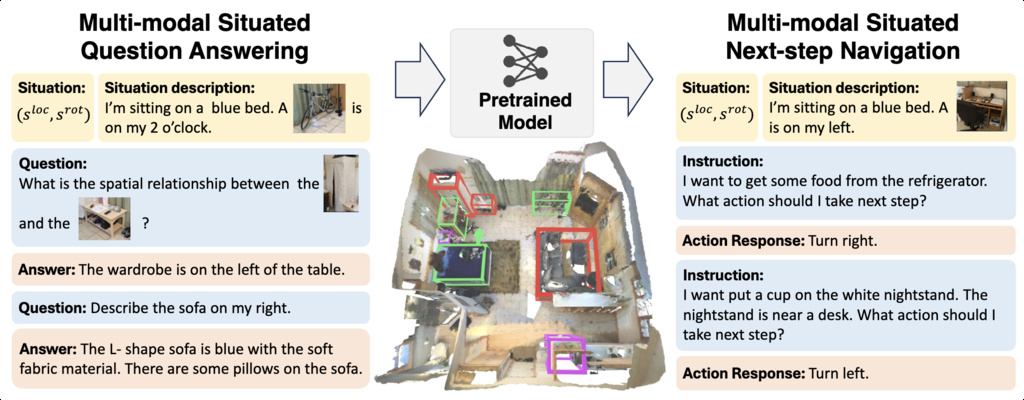 |
| SQA3D (ma2022sqa3d) | Situated Question Answering in 3D Scenes | 33.4k diverse reasoning questions | ScanNet |
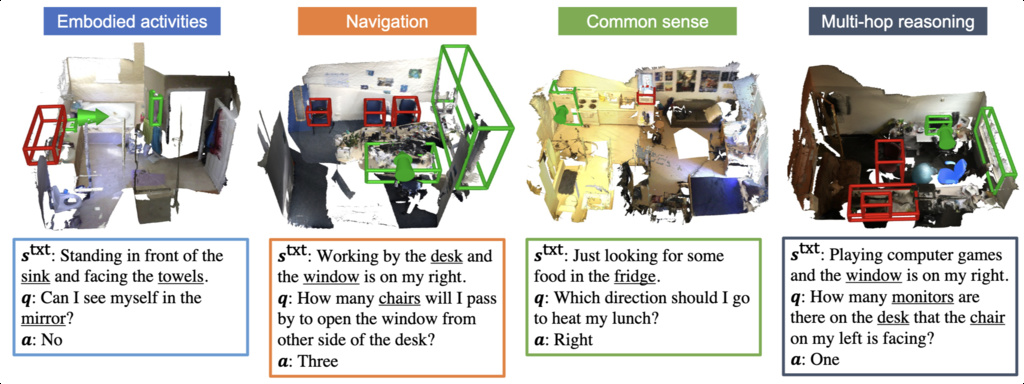 |
| VQASynth (i2024vqasynth) | Compose multimodal datasets | - | Internet |
 |
| AS-V2 (wang2024all) | High-quality ReC dataset | 127k | COCO |
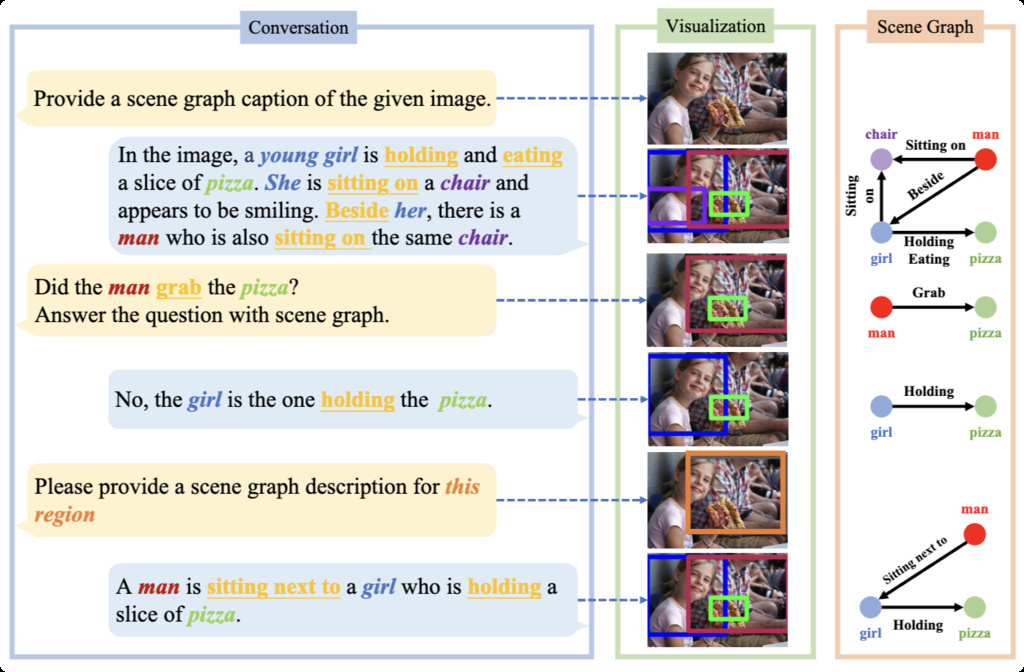 |
| OSD (cheng2024spatialrgpt) | Open Spatial Dataset | 8.7M spatial concepts grounded in 5M unique regions from 1M images | OpenImages |
 |
| Proximity-110K (li2024proximity) | Proximity Question Answering | 559,952 Q-A pairs related to object depth information and 429,925 Q-A pairs focusing on object proximity relationships | Visual Genome, COCO |
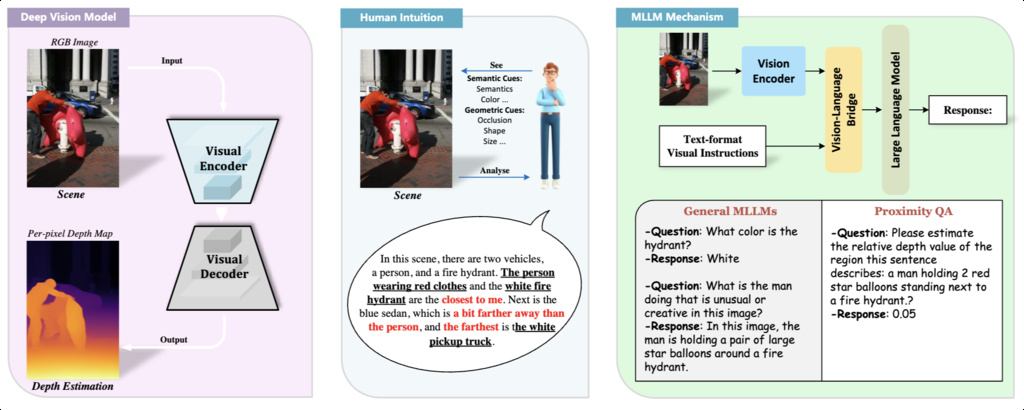 |
| TopViewRS (li2024topviewrs) | Top-View Reasoning in Space | 11,384 multiple-choice questions | Matterport3D |
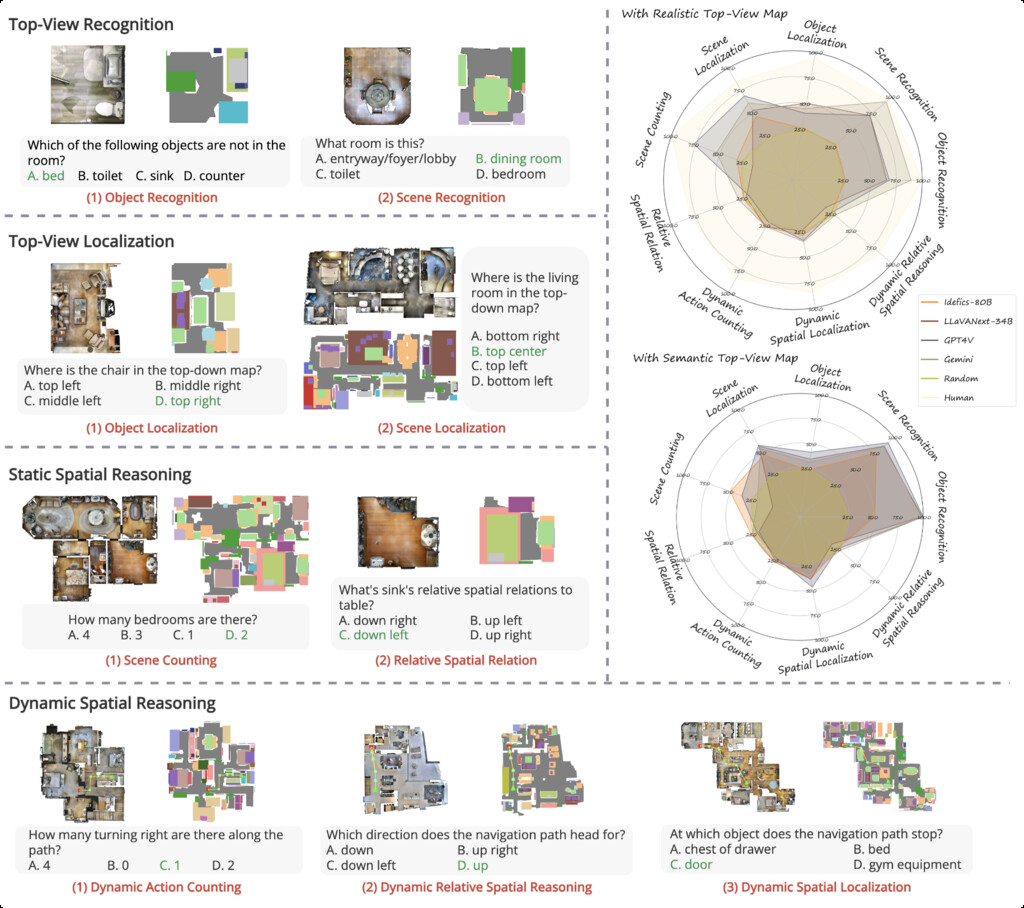 |
| EmbSpatial-Bench (du2024embspatial) | Evaluating embodied spatial understanding of LVLMs. | 3,640 | MP3D, AI2-THOR, ScanNet |
 |
| SpaCE-10 (gong2025space) | Compositional spatial evaluations | 5k+ QA pairs in 811 indoor scenes | SCN, 3RS, ARK, SCN++ |
 |
| Ego3D-Bench (gholami2025spatial) | Evaluate the spatial reasoning abilities of VLMs using ego-centric, multi-view outdoor data | over 8,600 QA pairs | manually collect |
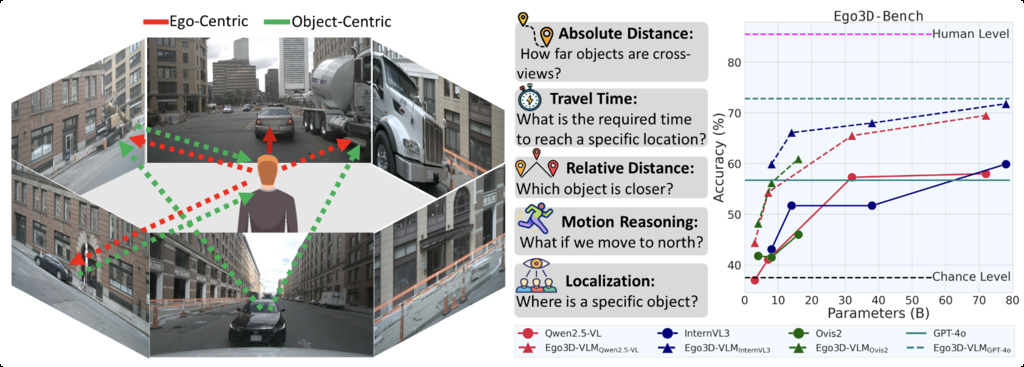 |
| SpatialScore | Comprehensive and diverse multimodal spatial understanding benchmark | 28K samples spanning 8 categories | MMVP, RealWorldQA, SpatialSense, SpatialBench, QSpatialBench, CV-Bench, VSR, 3DSRBench, VSI-Bench, BLINK, MMIU |
 |
| All-Angles Bench (yeh2025seeing) | Multi-view scene reasoning | 2,132 question–answer pairs | Exo4D, EgoHumans |
 |
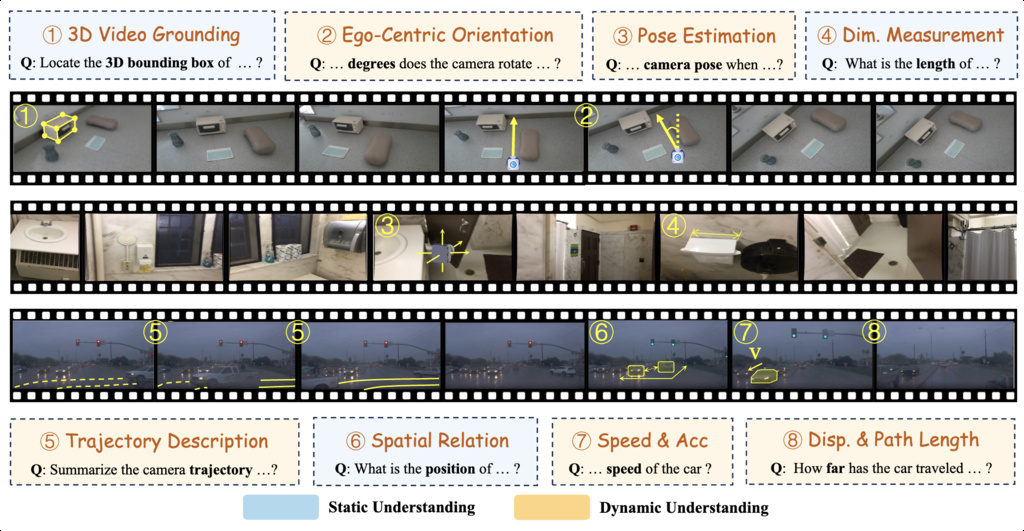
| STI-Bench (li2025sti) | Evaluate models' Spatial-Temporal Intelligence | 2,060 | Waymo, ScanNet, Omni6DPose |
 |
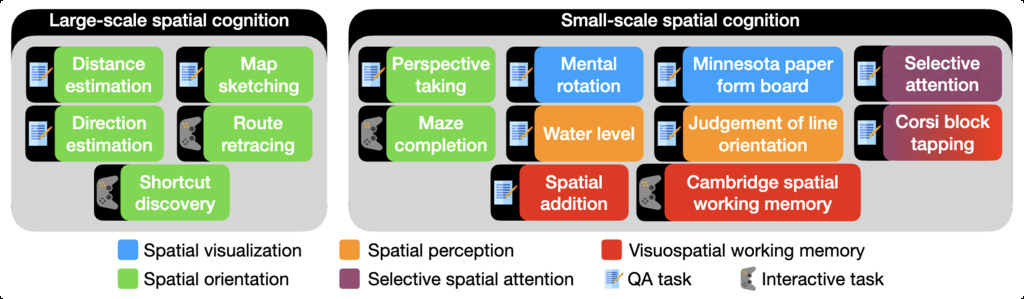
| SPACE (ramakrishnan2025does) | Evaluates spatial cognition | 5,008 | Synthetic Data |
 |
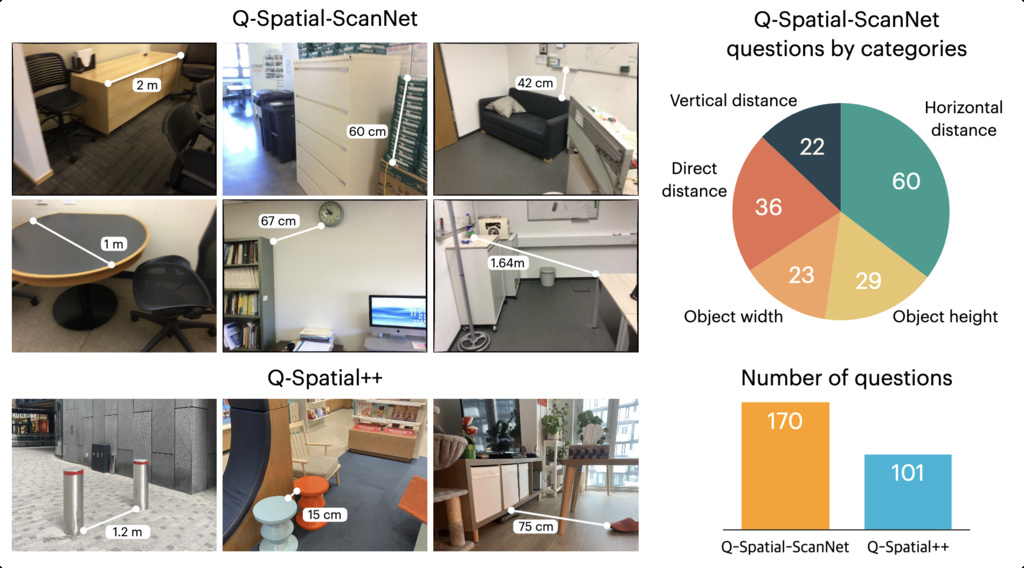
| Q-Spatial Bench (liao2024reasoning) | Quantitative spatial reasoning | 271 | ScanNet, images captured by iPhone |
 |
| SenseNova-SI-8M (cai2025scaling) | SenseNova-SI-8M reorganizes 4M open-source data and scales 4.5M additional data, according to fundamental spatial capbilities | 8.5M QA pairs | existing open-source datasets and synthetic data |
 |
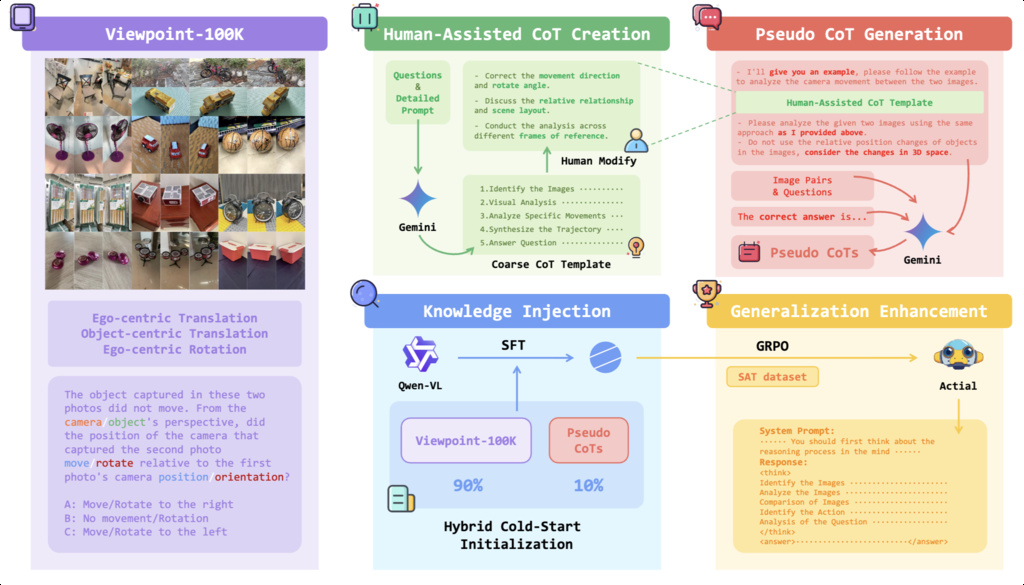
| Viewpoint-100K (zhan2025actial) | Viewpoint Learning | 100K object-centric image pairs and the corresponding QAs | MVImgNet |
 |
| Bench (yu2025thinking) | Humanoid visual search: A humanoid agent actively rotates its head to search for objects or paths in an immersive world represented by a 360° panoramic image | approximately 3,000 annotated task instances | self-collected footage across global metropolitan areas (New York, Paris, Amsterdam, Frankfurt) and open platforms (YouTube and the 360+x datase |
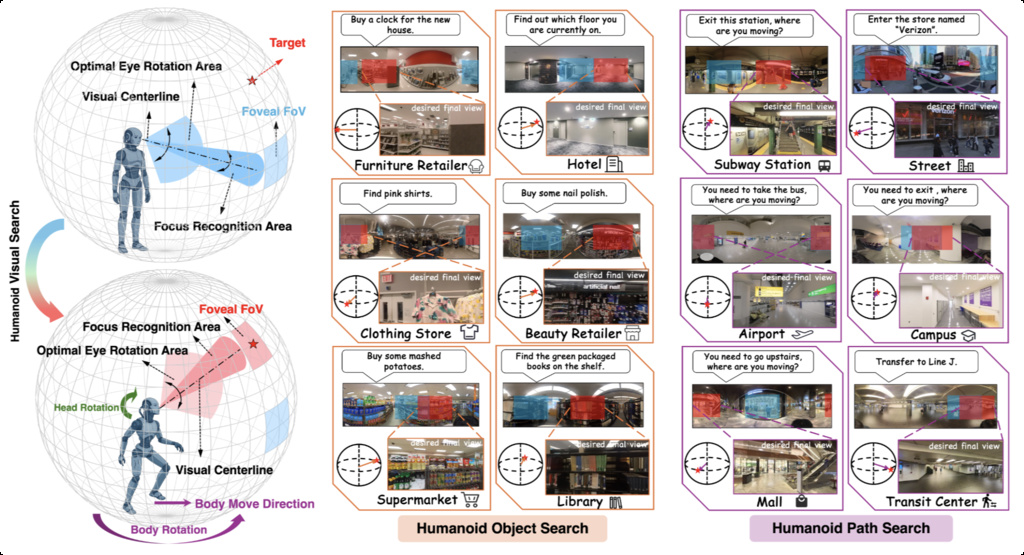 |
| Puffin-4M (liao2025thinking) | vision-language-camera triplets | 4M | existing open-source datasets and online |
 |
| TIGeR-300K (han2025tiger) | tool-invocation-oriented dataset | 300k | CA-1M |
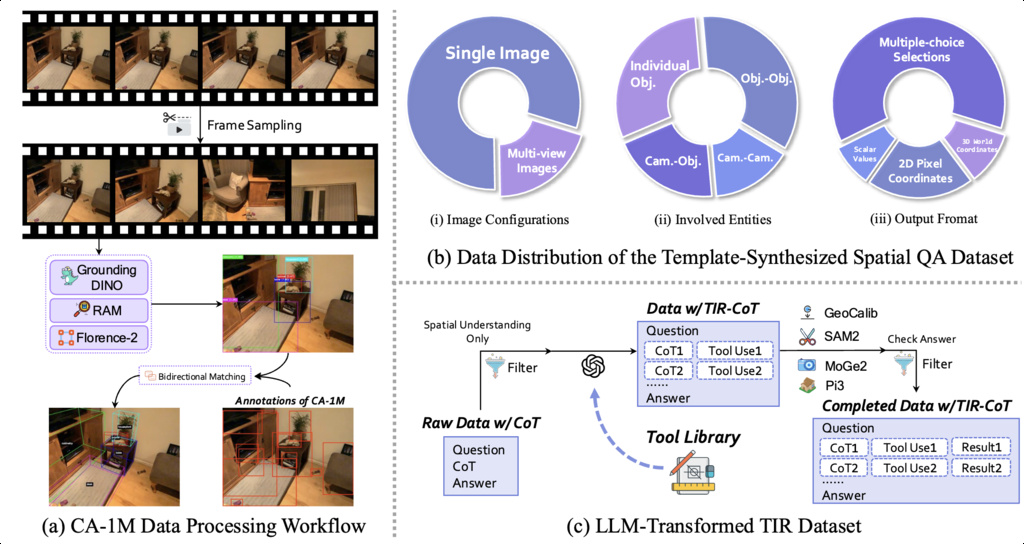 |
-
Spatial mental model: an internal representation of the environment that allows for consistent understanding and inference about space, independent of the current viewpoint.
References
- Cai, W., Ponomarenko, I., Yuan, J., Li, X., Yang, W., Dong, H., and Zhao, B. SpatialBot: Precise Spatial Understanding with Vision Language Models. Arxiv Preprint Arxiv: 2406.13642, 2024.
- Cai, Z., Wang, Y., Sun, Q., Wang, R., Gu, C., Yin, W., Lin, Z., Yang, Z., Wei, C., Qian, O., Pang, H. E., Shi, X., Deng, K., Han, X., Chen, Z., Li, J., Fan, X., Deng, H., Lu, L., … Yang, L. Holistic Evaluation of Multimodal LLMs on Spatial Intelligence. Arxiv Preprint Arxiv: 2508.13142, 2025.
- Cai, Z., Wang, R., Gu, C., Pu, F., Xu, J., Wang, Y., Yin, W., Yang, Z., Wei, C., Sun, Q., Zhou, T., Li, J., Pang, H. E., Qian, O., Wei, Y., Lin, Z., Shi, X., Deng, K., Han, X., … Yang, L. Scaling Spatial Intelligence with Multimodal Foundation Models. Arxiv Preprint Arxiv: 2511.13719, 2025.
- Chen, P., Lou, Y., Cao, S., Guo, J., Fan, L., Wu, Y., Yang, L., Ma, L., and Ye, J. SD-VLM: Spatial Measuring and Understanding with Depth-Encoded Vision-Language Models. Arxiv Preprint Arxiv:2509.17664, 2025.
- Cheng, A.-C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., and Liu, S. SpatialRGPT: Grounded Spatial Reasoning in Vision-Language Models. Advances in Neural Information Processing Systems, 2024.
- Du, M., Wu, B., Li, Z., Huang, X., and Wei, Z. EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models. Arxiv Preprint Arxiv: 2406.05756, 2024.
- Fan, Z., Zhang, J., Li, R., Zhang, J., Chen, R., Hu, H., Wang, K., Qu, H., Wang, D., Yan, Z., Xu, H., Theiss, J., Chen, T., Li, J., Tu, Z., Wang, Z., and Ranjan, R. VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction. Arxiv Preprint Arxiv: 2505.20279, 2025.
- Gholami, M., Rezaei, A., Weimin, Z., Mao, S., Zhou, S., Zhang, Y., and Akbari, M. Spatial Reasoning with Vision-Language Models in Ego-Centric Multi-View Scenes. Arxiv Preprint Arxiv: 2509.06266, 2025.
- Gong, Z., Li, W., Ma, O., Li, S., Wang, Z., Li, S., Ji, J., Yang, X., Luo, G., Yan, J., and Ji, R. SpaCE-10: A Comprehensive Benchmark for Multimodal Large Language Models in Compositional Spatial Intelligence. Arxiv Preprint Arxiv: 2506.07966, 2025.
- Guo, X., Zhang, R., Duan, Y., He, Y., Nie, D., Huang, W., Zhang, C., Liu, S., Zhao, H., and Chen, L. SURDS: Benchmarking Spatial Understanding and Reasoning in Driving Scenarios with Vision Language Models. Arxiv Preprint Arxiv: 2411.13112, 2024.
- Gupta, A., Dollár, P., and Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Han, Y., Chi, C., Zhou, E., Rong, S., An, J., Wang, P., Wang, Z., Sheng, L., and Zhang, S. TIGeR: Tool-Integrated Geometric Reasoning in Vision-Language Models for Robotics. Arxiv Preprint Arxiv: 2510.07181, 2025.
- Hu, W., Lin, J., Long, Y., Ran, Y., Jiang, L., Wang, Y., Zhu, C., Xu, R., Wang, T., and Pang, J. G^2VLM: Geometry Grounded Vision Language Model with Unified 3D Reconstruction and Spatial Reasoning. Arxiv Preprint Arxiv: 2511.21688, 2025.
- remyxai. VQASynth, 2024.
- Jia, M., Qi, Z., Zhang, S., Zhang, W., Yu, X., He, J., Wang, H., and Yi, L. OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models. Arxiv Preprint Arxiv: 2506.03135, 2025.
- Kamath, A., Hessel, J., and Chang, K.-W. What's "up" with vision-language models? Investigating their struggle with spatial reasoning. Conference on Empirical Methods in Natural Language Processing, 2023.
- Li, P., Zhang, H., Sun, M., Shao, R., Xiang, T., Wang, W., and Shan, Y. MVImgNet: A Large-scale Dataset of Multi-view Images. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Li, J., Nan, X., Lu, M., Du, L., and Zhang, S. Proximity QA: Unleashing the Power of Multi-Modal Large Language Models for Spatial Proximity Analysis. Arxiv Preprint Arxiv: 2401.17862, 2024.
- Li, C., Zhang, C., Zhou, H., Collier, N., Korhonen, A., and Vuli'c, I. TopViewRS: Vision-Language Models as Top-View Spatial Reasoners. Conference on Empirical Methods in Natural Language Processing, 2024.
- Li, Y., Zhang, Y., Lin, T., Liu, X., Cai, W., Liu, Z., and Zhao, B. STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?. Arxiv Preprint Arxiv: 2503.23765, 2025.
- Li, L., Bigverdi, M., Gu, J., Ma, Z., Yang, Y., Li, Z., Choi, Y., and Krishna, R. Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations. Arxiv Preprint Arxiv: 2506.04633, 2025.
- Li, D., Li, H., Wang, Z., Yan, Y., Zhang, H., Chen, S., Hou, G., Jiang, S., Zhang, W., Shen, Y., Lu, W., and Zhuang, Y. ViewSpatial-Bench: Evaluating Multi-perspective Spatial Localization in Vision-Language Models. Arxiv Preprint Arxiv: 2505.21500, 2025.
- Liao, Y.-H., Mahmood, R., Fidler, S., and Acuna, D. Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language Models. Arxiv Preprint Arxiv: 2409.09788, 2024.
- Liao, K., Wu, S., Wu, Z., Jin, L., Wang, C., Wang, Y., Wang, F., Li, W., and Loy, C. C. Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation. Arxiv Preprint Arxiv: 2510.08673, 2025.
- Lin, J., Zhu, C., Xu, R., Mao, X., Liu, X., Wang, T., and Pang, J. OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding. Arxiv Preprint Arxiv: 2507.07984, 2025.
- Linghu, X., Huang, J., Niu, X., Ma, X., Jia, B., and Huang, S. Multi-modal Situated Reasoning in 3D Scenes. Advances in Neural Information Processing Systems, 2024.
- Liu, Y., Zhang, B., Zang, Y., Cao, Y., Xing, L., Dong, X., Duan, H., Lin, D., and Wang, J. Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning. Arxiv Preprint Arxiv: 2510.27606, 2025.
- Liu, Y., Ma, M., Yu, X., Ding, P., Zhao, H., Sun, M., Huang, S., and Wang, D. SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning. Arxiv Preprint Arxiv: 2505.12448, 2025.
- Ma, X., Yong, S., Zheng, Z., Li, Q., Liang, Y., Zhu, S.-C., and Huang, S. SQA3D: Situated Question Answering in 3D Scenes. International Conference on Learning Representations, 2022.
- Ma, W., Chen, H., Zhang, G., Chou, Y.-C., Chen, J., Melo, C. de, and Yuille, A. 3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025.
- Ouyang, K., Liu, Y., Wu, H., Liu, Y., Zhou, H., Zhou, J., Meng, F., and Sun, X. SpaceR: Reinforcing MLLMs in Video Spatial Reasoning. Arxiv Preprint Arxiv: 2504.01805, 2025.
- Qin, Y., Wei, B., Ge, J., Kallidromitis, K., Fu, S., Darrell, T., and Wang, X. Chain-of-Visual-Thought: Teaching VLMs to See and Think Better with Continuous Visual Tokens. Arxiv Preprint Arxiv: 2511.19418, 2025.
- Ramakrishnan, S. K., Wijmans, E., Krähenbühl, P., and Koltun, V. Does Spatial Cognition Emerge in Frontier Models?. The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025.
- Ray, A., Duan, J., II, E. L. B., Tan, R., Bashkirova, D., Hendrix, R., Ehsani, K., Kembhavi, A., Plummer, B. A., Krishna, R., Zeng, K.-H., and Saenko, K. SAT: Dynamic Spatial Aptitude Training for Multimodal Language Models. Second Conference on Language Modeling, 2025.
- Shiri, F., Guo, X.-Y., Far, M. G., Yu, X., Haf, R., and Li, Y.-F. An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024.
- Song, C. H., Blukis, V., Tremblay, J., Tyree, S., Su, Y., and Birchfield, S. RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Tang, K., Gao, J., Zeng, Y., Duan, H., Sun, Y., Xing, Z., Liu, W., Lyu, K., and Chen, K. LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?. Arxiv Preprint Arxiv: 2503.19990, 2025.
- Team, G. R., Abeyruwan, S., Ainslie, J., Alayrac, J.-B., Arenas, M. G., Armstrong, T., Balakrishna, A., Baruch, R., Bauza, M., Blokzijl, M., Bohez, S., Bousmalis, K., Brohan, A., Buschmann, T., Byravan, A., Cabi, S., Caluwaerts, K., Casarini, F., Chang, O., … Zhou, Y. Gemini Robotics: Bringing AI into the Physical World. Arxiv Preprint Arxiv: 2503.20020, 2025.
- Wang, X., Ma, W., Li, Z., Kortylewski, A., and Yuille, A. L. 3D-Aware Visual Question Answering about Parts, Poses and Occlusions. Advances in Neural Information Processing Systems, 2023.
- Wang, W., Ren, Y., Luo, H., Li, T., Yan, C., Chen, Z., Wang, W., Li, Q., Lu, L., Zhu, X., Qiao, Y., and Dai, J. The All-Seeing Project V2: Towards General Relation Comprehension of the Open World. Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXXIII, 2024.
- Wang, J., Ming, Y., Shi, Z., Vineet, V., Wang, X., Li, Y., and Joshi, N. Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models. Advances in Neural Information Processing Systems, 2024.
- Wang, W., Tan, R., Zhu, P., Yang, J., Yang, Z., Wang, L., Kolobov, A., Gao, J., and Gong, B. SITE: towards Spatial Intelligence Thorough Evaluation. Arxiv Preprint Arxiv: 2505.05456, 2025.
- Wang, S., Pei, M., Sun, L., Deng, C., Shao, K., Tian, Z., Zhang, H., and Wang, J. SpatialViz-Bench: An MLLM Benchmark for Spatial Visualization. Arxiv Preprint Arxiv: 2507.07610, 2025.
- Xu, R., Wang, W., Tang, H., Chen, X., Wang, X., Chu, F.-J., Lin, D., Feiszli, M., and Liang, K. J. Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models. Arxiv Preprint Arxiv: 2505.17015, 2025.
- Yang, S., Xu, R., Xie, Y., Yang, S., Li, M., Lin, J., Zhu, C., Chen, X., Duan, H., Yue, X., Lin, D., Wang, T., and Pang, J. MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence. Arxiv Preprint Arxiv: 2505.23764, 2025.
- Yang, J., Yang, S., Gupta, A. W., Han, R., Fei-Fei, L., and Xie, S. Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Yang, R., Zhu, Z., Li, Y., Huang, J., Yan, S., Zhou, S., Liu, Z., Li, X., Li, S., Wang, W., Lin, Y., and Zhao, H. Visual Spatial Tuning. Arxiv Preprint Arxiv: 2511.05491, 2025.
- Yeh, C.-H., Wang, C., Tong, S., Cheng, T.-Y., Wang, R., Chu, T., Zhai, Y., Chen, Y., Gao, S., and Ma, Y. Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs. Arxiv Preprint Arxiv: 2504.15280, 2025.
- Yin, B., Wang, Q., Zhang, P., Zhang, J., Wang, K., Wang, Z., Zhang, J., Chandrasegaran, K., Liu, H., Krishna, R., Xie, S., Li, M., Wu, J., and Fei-Fei, L. Spatial Mental Modeling from Limited Views. Structural Priors for Vision Workshop at Iccv'25, 2025.
- Yu, H., Han, Y., Zhang, X., Yin, B., Chang, B., Han, X., Liu, X., Zhang, J., Pavone, M., Feng, C., Xie, S., and Li, Y. Thinking in 360\textdegree{}: Humanoid Visual Search in the Wild. Arxiv Preprint Arxiv: 2511.20351, 2025.
- Zhan, X., Huang, W., Sun, H., Fu, X., Ma, C., Cao, S., Jia, B., Lin, S., Yin, Z., Bai, L., Ouyang, W., Li, Y., Guo, J., and Guo, Y. Actial: Activate Spatial Reasoning Ability of Multimodal Large Language Models. Arxiv Preprint Arxiv: 2511.01618, 2025.
- Zhang, Y., Xu, Z., Shen, Y., Kordjamshidi, P., and Huang, L. SPARTUN3D: Situated Spatial Understanding of 3D World in Large Language Models. International Conference on Learning Representations, 2024.
- Zhang, Z., Wang, Z., Zhang, G., Dai, W., Xia, Y., Yan, Z., Hong, M., and Zhao, Z. DSI-Bench: A Benchmark for Dynamic Spatial Intelligence. Arxiv Preprint Arxiv: 2510.18873, 2025.
- Zhang, J., Chen, Y., Zhou, Y., Xu, Y., Huang, Z., Mei, J., Chen, J., Yuan, Y.-J., Cai, X., Huang, G., Quan, X., Xu, H., and Zhang, L. From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D. Arxiv Preprint Arxiv: 2503.22976, 2025.
- Zhang, W., Zhou, Z., Zeng, X., Liu, X., Fang, J., Gao, C., Li, Y., Cui, J., Chen, X., and Zhang, X.-P. Open3D-VQA: A Benchmark for Comprehensive Spatial Reasoning with Multimodal Large Language Model in Open Space. Arxiv Preprint Arxiv: 2503.11094, 2025.
- Zhang, W., Huang, Y., Xu, Y., Huang, J., Zhi, H., Ren, S., Xu, W., and Zhang, J. Why Do MLLMs Struggle with Spatial Understanding? A Systematic Analysis from Data to Architecture. Arxiv Preprint Arxiv: 2509.02359, 2025.
- Zhou, E., An, J., Chi, C., Han, Y., Rong, S., Zhang, C., Wang, P., Wang, Z., Huang, T., Sheng, L., and Zhang, S. RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics. Arxiv Preprint Arxiv: 2506.04308, 2025.
- Zhou, S., Vilesov, A., He, X., Wan, Z., Zhang, S., Nagachandra, A., Chang, D., Chen, D., Wang, X. E., and Kadambi, A. VLM4D: Towards Spatiotemporal Awareness in Vision Language Models. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025.