VGGT
1. VGGT
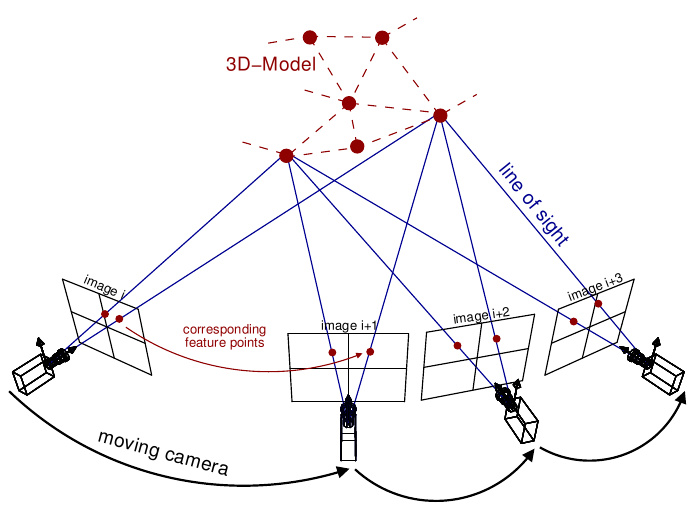
Traditional methods in the field of 3D scene reconstruction rely on Structure-from-Motion (SfM) techniques, which estimate camera poses and a sparse 3D structure from overlapping images by matching features and solving geometric constraints. Another method that can be used is Bundle Adjustment (BA), which refines cameras and 3D points by minimizing projection error across all observations through an iterative optimization process.
VGGT moves most of the difficulty and compute processing to its training time, giving fast and predictable inference. Rather than using a complex pipeline like previous methods, VGGT is a unified model that has been trained to understand multi‑view cues like parallax and occlusion, keeping different camera views and their respective depth in agreement. The payoff is a quicker method from raw images to a 3D reconstruction, which can be rendered, analyzed, or handed off to SLAM and NeRF pipelines.
1.1. Classical Pipelines
Structure-from-Motion and Bundle Adjustment are tried-and-true methods used for 3D reconstruction, but they also come with time and compute costs in their implementations.
- They depend on reliably matching the same real-world points across different photos. Flat or unmarked walls, motion blur, strong lighting changes between images, and wide baselines in stereo imaging lead to weak or wrong matches. Implementing RANSAC (Random Sample Consensus), an iterative algorithm used to estimate parameters of a model from a dataset that contains outliers, does lead to better matches, but requires additional compute and may still be insufficient.
- They introduce many failure points. A bad initialization, inaccurate camera input data, or miscalculating the relationship between two camera views can all snowball into a failed 3D reconstruction.
- They require significant engineering complexity to reach high accuracy. Feature detection, point matching, outlier rejection, pose estimation, object triangulation, and nonlinear optimization all require careful choices and parameter tuning to produce an effective result.
- They are iterative at test time, meaning that as an input set grows, runtime and memory typically grow superlinearly.
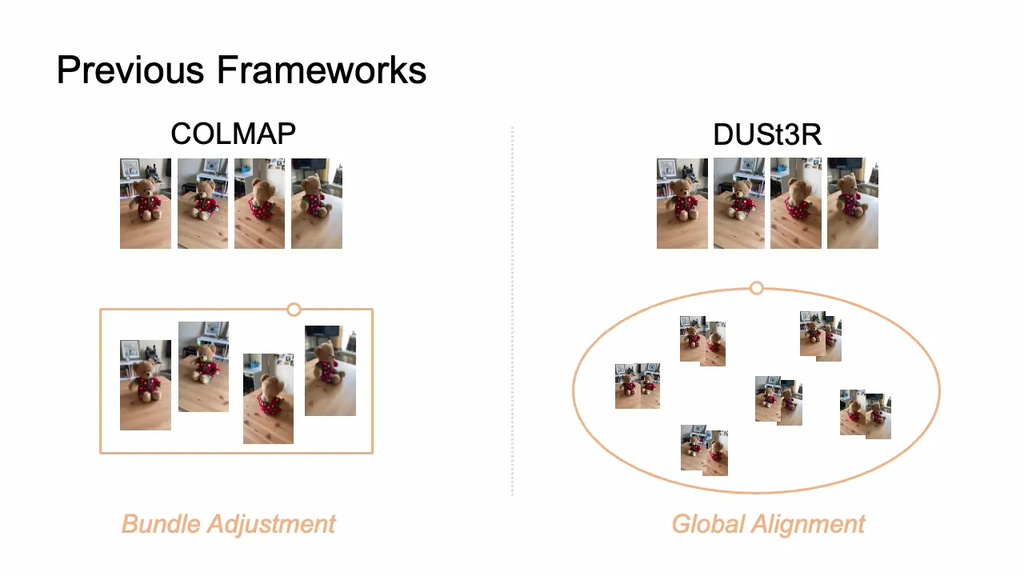
These issues don't take away from the excellent innovations that these methods introduced, but rather they simply create room for an alternative that shifts more of the burden to training time and leaves a lighter, faster path at inference.
1.2. What VGGT Brings To The Table
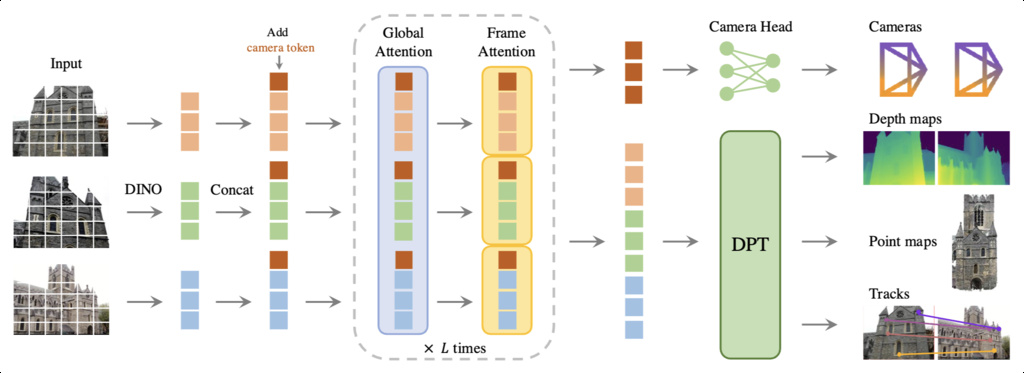
VGGT is a large vision transformer trained end to end on diverse image collections. It accepts a variable number of views, working with a single image, a short clip, or more than two hundred images from a photo sequence. All predictions live in the coordinate frame of the first camera, making the outputs easy to compose.
The model returns four families of results.
- Camera data: A camera regression head directly produces both the camera's internal parameters such as focal length (intrinsic parameters), and its position in the real world (extrinsic parameters).
- Dense depth maps: A depth value for each pixel in each image.
- 3D point maps: A per-pixel 3D point expressed in the shared frame. This is redundant with depth and cameras by design, yet it improves stability and downstream utility.
- Tracking features: Dense features that a lightweight tracker can use to follow points across frames.
The most important property is not any single metric. It is that you get all of these outputs together, in a consistent frame, from one forward pass. That unification removes a lot of unnecessary parts of a previously complicated pipeline, making the system more predictable.
1.3. Architecture Overview
VGGT represents each image as a sequence of tokens produced by a strong visual backbone using DINOv2. Image patches become tokens with local appearance and geometry cues. The transformer then alternates two kinds of attention blocks.
1.3.1. Key Innovations
- Frame-wise self-attention lets tokens within a single image interact. This builds clean per-image features that capture edges, corners, and texture patterns.
- Global self-attention lets tokens from different images communicate. This is where cross-view reasoning happens. Parallax, occlusion boundaries, and repeated patterns become part of the model's context.
Alternating these blocks across layers is a simple idea, but they work in conjunction to create a better model. Local reasoning sharpens each view, while global reasoning ties the views together. Repeating both steps produces features that are good at single‑view detail and multi‑view consistency at the same time.
Two extra token types guide the outputs:
- A camera token accompanies each image. It distills pose‑relevant information and feeds the camera head that calculates camera data.
- A set of register tokens acts as stable slots that the dense prediction transformer (DPT) head, a transformer head that upsamples transformer features into per‑pixel maps, uses to aggregate multi‑scale context while recovering spatial detail.
Downstream heads attend to these tokens to produce cameras, depth, point maps, and dense features. There is no test‑time optimization loop as reasoning happens inside attention during the forward pass.
Though depth maps and 3D point maps are connected by the pinhole camera model, predicting both improves learning. The two outputs provide different gradient signals during training, helping the model to learn internal checks that create more consistent predictions.
VGGT also produces multiple different outputs through separate heads. The camera head regresses intrinsic parameters and poses, while a DPT‑style dense head restores per‑pixel detail for depth and point maps. In addition, a tracking head exposes dense features suitable for correspondence and can be fine‑tuned independently, following CoTracker‑style supervision. This modularity lets you swap, extend, or specialize heads for tasks such as SLAM initialization, NeRF warm starts, or video tracking.
1.3.2. From Images To 3D
To help with understanding the model, here is a qualitative description for a single pass through the model on a short image sequence.
- The images are resized to a standard resolution, while a DINOv2 backbone converts patches to tokens. A camera token and several register tokens are attached to each image’s token list.
- Frame‑wise attention runs and strengthens per‑image features. In this step, edges align, textures become more coherent, and local geometry cues become clearer.
- Global attention runs and lets tokens communicate across images. Tokens that represent the same physical region begin to agree. The model “notices” parallax and occlusion cues because the features that move together across views become consistent.
- Several rounds of local and global attention follow. Each round increases the agreement both within and across views.
- Output heads attend to the camera tokens and register tokens and produce cameras, depth maps, and point maps. Dense features are ready for a tracker.
- All outputs are already in the same coordinate frame, so you can render a point cloud or a depth overlay immediately.
- The key point is that VGGT learns all the heavy lifting through attention, which executes it implicitly, rather than needing to be explicitly optimized in a classical system.
1.4. Training Strategy
The VGGT training loss is calculated by combining losses for cameras, depth, point maps, and tracking.
- Camera loss teaches the model to predict three things: how the camera is turned (rotation), where it is (translation), and its internal settings like focal length (intrinsic parameters). Rotations use stable parameterizations such as quaternions (four numbers that together represent one 3D rotation) or 6D representations to prevent any degrees of freedom from being lost. For translation, it learns position only up to a scale, since everything is measured relative to the first camera’s coordinate frame rather than in absolute meters.
- Depth and point losses penalize deviations from ground truth when available with the inclusion of uncertainty weightings. Regions that are ambiguous, like blank walls or specular surfaces, contribute less to the gradient, while including spatial smoothness to favour piecewise smooth depth and preserving edges.
- Tracking loss teaches the features to support correspondences across views, downweighted with so that it does not dominate.
The model was trained on a large mix of datasets that cover indoor scenes, outdoor scenes, and synthetic environments, while a wide range of diverse sources were used. These datasets included CO3Dv2, ScanNet, MegaDepth, Habitat, and Replica. The model contains 1.2 billion parameters and was trained on 64 A100 GPUs over nine days. Exposure changes, motion blur, lens differences, and scale variations were also implemented to teach the network to handle the messiness of real images.
One practical detail that was used to ensure consistency was coordinate normalization. All predictions are expressed in a learned canonical frame, anchored to the first camera. Even though many systems hardcode a normalization procedure, VGGT learns it as part of training. This choice removes a post‑processing step and lets the network adapt as data changes.