State of AI Report 2025
1. STATE OF AI REPORT 2025
-
Think before you speak: o1 “thinking” ignites the reasoning race DeepSeek R1-lite-preview DeepSeek V3 brings you to R1 DeepSeek V3.1 and V3.2-Exp (More thinking, more tool use, less cost)
-
Parallel reasoning:
- Adaptive Parallel Reasoning (APR) enables models to dynamically orchestrate branching inference through spawn() and join() operations, training both parent and child threads end-to-end using RL to optimize coordinated behavior.
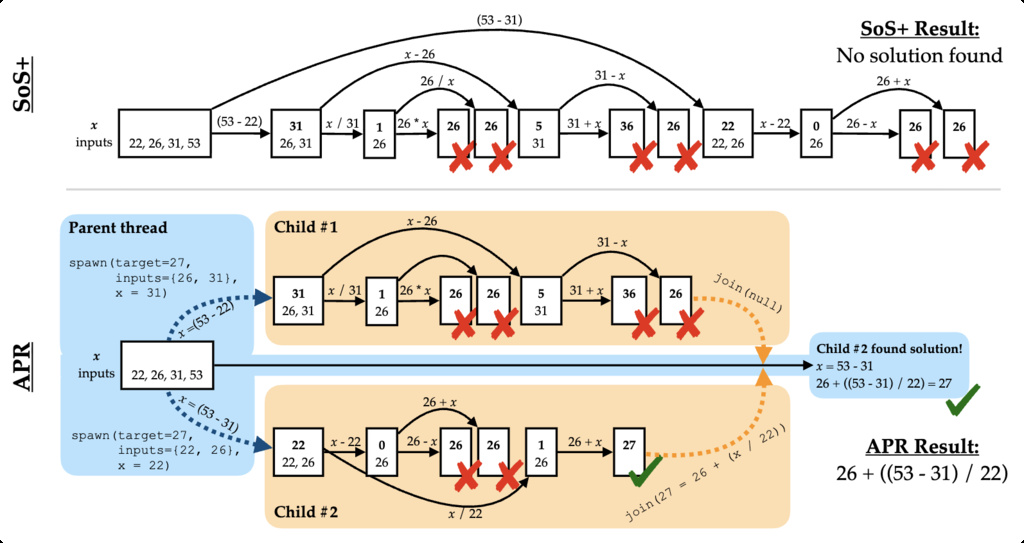
Figure 1: Serialized search (top) vs Adaptive Parallel Reasoning (bottom) - Sample Set Aggregator (SSA) trains a compact model to fuse multiple reasoning samples into one coherent answer, outperforming naive re-ranking methods.
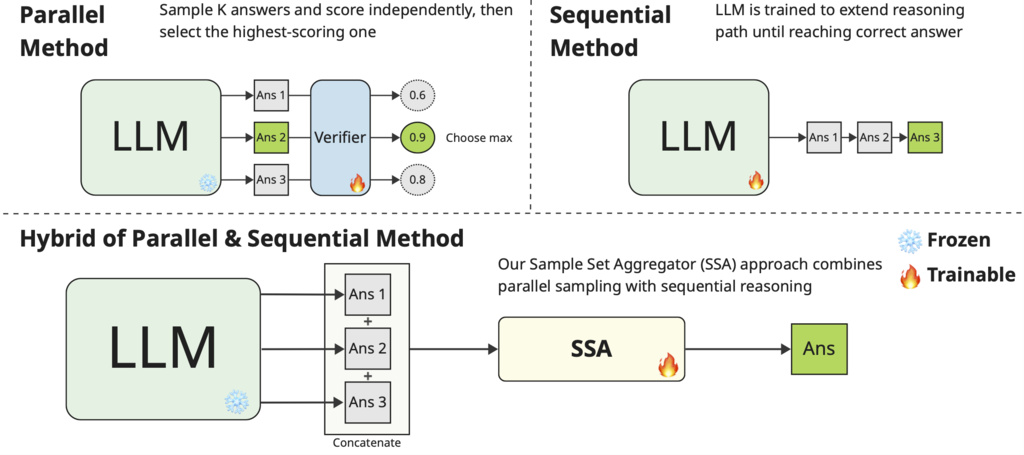
-
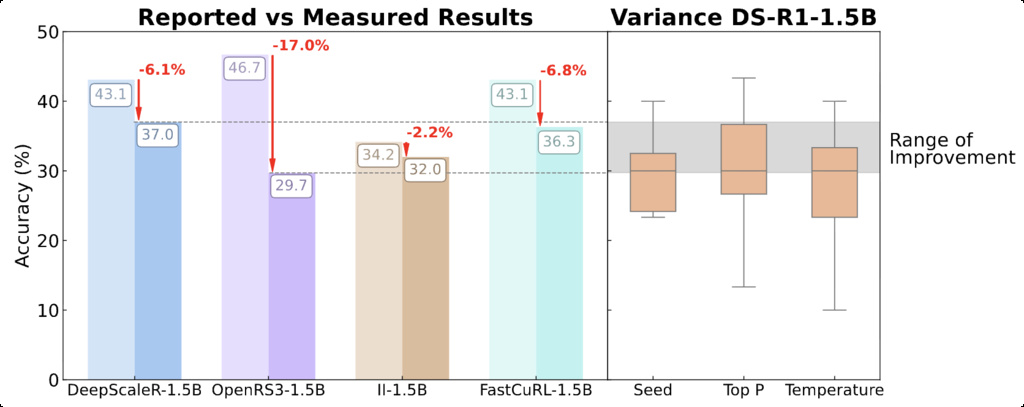
The illusion of reasoning gains: The improvements we observe from recent reasoning methods fall entirely within baseline model variance ranges (i.e. margin of error), which suggests that perceived reasoning progress may be illusory…
- Current benchmarks are highly sensitive to the implementation (decoding parameters, seeds, prompts, hardware) and small dataset sizes. For example, AIME'24 only has 30 examples where one question shifts Pass by 3+ percentage points, causing double-digit performance swings.
- What's more, RL approaches show minimal real gains and overfit easily. Under standardised evaluation, many RL methods drop 6-17% from reported results with no statistically significant improvements over baselines.
- Recent methods' improvements fall entirely within baseline model variance ranges, suggesting limited progress. This highlights the critical need for rigorous multi-seed evaluation protocols and transparent reporting standards.
-
How far have we come? One widely discussed paper suggests that large reasoning models (LRMs) paradoxically give up on complex problems and only outperform standard models in a narrow complexity window. However, critics argue these results stem from flawed experimental design rather than genuine reasoning failures.
-
How reasoning breaks:
- Minor variations: Simple distracting facts have huge impacts on a model's reasoning performance. For example, adding irrelevant phrases like “Interesting fact: cats sleep most of their lives” to maths problems doubles the chances of SOTA reasoning models getting answers wrong!
-
Small shifts cause big failures: Reasoning also degrades under mild distribution changes. Changing numbers or adding one innocuous clause slashes math accuracy, while shifting the length/format of chains-of-thought makes models produce fluent but incoherent steps. Forcing the model to “think” in a user's language raises readability but lowers accuracy. These effects persist at larger scales and after light post-training.
- Apple's GSM-Symbolic work shows that accuracy drops sharply when only the numeric instantiation changes, and adding a single seemingly relevant clause can cut performance by 65%. This suggests that models do template-matching rather than true algebraic reasoning.
- Work from ASU's DataAlchemy found that the CoT helps in-distribution but collapses when test tasks, chain length, or CoT format deviate from training. Longer, well-worded traces often mask incorrect logic.
- Finally, Groningen/Harvard/MGH/Amsterdam's XReasoning shows how prompt-forcing the model to reason in the user's language lifts match rates to 98% on hard sets but reduces accuracy by 9-13 points. Using 100-250 example post-training improves language match but the accuracy penalty remains.
-
CoTs still work, even when models aren't honest… New findings from METR show that even when models generate unfaithful or misleading reasoning traces, CoT is still highly diagnostic for oversight.
-
Researchers find a single, steerable direction in model activations that encodes “test awareness.” By nudging the model along this direction, they can make it act more or less like it’s under evaluation. Turning awareness up increases refusals and safety-compliant behavior and turning it down does the opposite. This means reported safety can be inflated by evaluation setup rather than true robustness. This “test awareness” is akin to the Hawthorne effect, where humans change behavior when being observed and change their behavior accordingly.
-
…but there are safety concerns, like the "AI Hawthorne effect": Safety-first pretraining argues that safer behavior must be built into the base model, not bolted on later. A data-centric pipeline of filtering, recontextualizing, refusal curricula, and harmfulness tags does cut jailbreak success and survives benign finetuning. However, others cautions that training on vast, unsupervised web data bakes in biases that cannot be cleanly removed without harming utility, so “more safety data” is not a panacea.
-
Safety by design meets its skeptics: Researchers argue that to keep AI systems safe and monitorable, we may need to pay a "monitorability tax", i.e. accepting slightly less capable models in exchange for maintaining visibility into their reasoning.
-
Trading capability for transparency: Leaders from OpenAI, Google DeepMind, Anthropic, and Meta coordinated a joint call to action, urging the field to seize the opportunity to understand and preserve CoT monitorability.
-
Monitor your CoTs: just because you can read 'em, doesn't mean you should trust 'em: Leaders from OpenAI, Google DeepMind, Anthropic, and Meta coordinated a joint call to action, urging the field to seize the opportunity to understand and preserve CoT monitorability.
-
But can LLMs reason without generating tokens? Researchers from FAIR at META proposed a novel internal reasoning process that leverages an LLM’s own residual stream instead of a decoding tokens to a Chain-of-Thought (CoT) scratchpad.
-
Researchers begin to prioritise quality and diversity of post training data over volume
- The NaturalReasoning dataset uses web-grounded, graduate-level questions to unlock faster, cheaper progress in mathematical & scientific reasoning during supervised post-training.
- In RL post-training, a new Oxford paper demonstrates the automatic selection of optimal training problems. They introduce a method, LILO, to algorithmically identify questions that allow for maximally efficient training.
-
The evolution of AI reward signals towards environments with verifiable rewards: RL has expanded from simple, fully checkable signals to fuzzier and more subjective goals, and now is splintering again. Early systems used binary outcomes, then fuzzy human preferences and demonstrations, and more recently unverifiable creative tasks. Today, two new directions stand out: rubric-based rewards, where small sets of rules guide alignment, and a revival of verifiable correctness for math and coding through RLVR. Process rewards are also emerging to score intermediate reasoning steps, offering a middle ground.
-
Even so, RL environments and evaluations are fraught with challenges: As reward signals become more abstract, the simplified environments used for agent training have become the primary bottleneck, limiting progress towards generalizable intelligence.
-
RL from verifiable rewards: promising, but the evidence cuts both ways: RL with Verifiable Rewards (RLVR) has driven recent progress (OpenAI o1, DeepSeek-R1) by training on answers that can be automatically checked: math scores, program tests, or exact matches. However, two recent studies disagree on what RLVR actually adds. One argues it mostly reshuffles sampling without creating new reasoning; the other shows gains once you score the reasoning chains themselves rather than just final answers. Together they map where RLVR helps today and where it stalls.
-
Ushering in an era of AI-augmented mathematics: Math is a verifiable domain: systems can plan, compute, and check every step, and publish artifacts others can audit. So 2025 saw competitive math and formal proof systems jump together: OpenAI, DeepMind and Harmonic hit IMO gold-medal performance, while auto-formalization and open provers set new records.
-
Bigger models, same budget: RL with LoRA adapters: Thinking Machines show that RL can match full fine-tuning even with rank-1 Low-Rank Adaptation (LoRA). In policy-gradient setups, LoRA updates only tiny adapters while the backbone stays frozen, yet it reaches the same peak performance, often with a wider range of stable learning rates. The reason is that RL supplies very few bits per episode, so even tiny adapters have ample capacity to absorb what RL can teach.
-
Beyond reasoning is … continual learning? The scaling paradigm is shifting from static pre-training to dynamic, on-the-fly adaptation. Test-time fine-tuning (TTT) adapts a model's weights to a specific prompt at inference, a step towards continuous learning.
-
Too many cooks? Researchers have discovered why merging multiple expert AI models hits a performance wall: the task vector space undergoes rank collapse, causing different experts' knowledge to become redundant rather than complementary. Subspace Boosting uses singular value decomposition to maintain the unique contributions of each model, achieving >10% gains when merging up to 20 specialists. This breakthrough could facilitate versatile systems that combine specialized models without the usual degradation that occurs at scale.
-
The Muon Optimizer: expanding the compute-time Pareto frontier beyond AdamW: Researchers show that Muon expands the compute-time Pareto frontier beyond AdamW, the first optimizer to challenge the 7-year incumbent in large-scale training. Muon demonstrates better data efficiency at large batch sizes, enabling faster training with more devices.
-
Cutting your losses: significant memory reduction for LLM training: As vocabularies grow, the loss layer consumes up to 90% of training memory in modern LLMs. Apple researchers show that this bottleneck can be eliminated by computing the loss without materializing the massive logit matrix, enabling dramatically larger batch sizes and more efficient training.
-
How much do LLMs memorize? There's a way to separate memorization from generalization, showing that GPT-family models have a finite “capacity” of 3.6 bits per parameter. Models memorize training data until that capacity is full, then must generalize once dataset size exceeds it. This explains the “double descent” phenomenon and why today’s largest LLMs, trained with extreme data-to-parameter ratios, are difficult to probe for specific memorized examples. At the same time, membership inference attacks are still improving on smaller-scale models.
-
Learning from superintelligence: AlphaZero teaches chess grandmasters new concepts: Researchers extracted novel chess concepts from AlphaZero (an AI system that mastered chess via self-play without human supervision) and successfully taught them to 4 world champion grandmasters, demonstrating that superhuman AI systems can advance human knowledge at the highest expert levels. This paper demonstrates an exciting process for mining superhuman knowledge and proving humans can learn them.
-
Kimi K2: stable trillion-scale MoE for agentic intelligence in the open: China’s Moonshot AI built a 1T-param MoE with 32B active trained using MuonClip, an improved optimizer that integrates the token-efficient Muon algorithm with a stability-enhancing mechanism, to deliver greater stability and advancing open-weight models for agentic workflows. It ranks as the 1 open text model on LMArena.
-
Open source vs. proprietary: where are we now? There was a brief moment around this time last year where the intelligence gap between open vs. closed models seemed to have compressed. And then o1-preview dropped and the intelligence gap widened significantly until DeepSeek R1, and o3 after it. Today, the most intelligent models remain closed: GPT-5, o3, Gemini 2.5 Pro, Claude 4.1 Opus, and new entrant, Grok 4. Beside gpt-oss, the strongest open weights model is Qwen. Pictured are the aggregate Intelligence Index, which combines multiple capabilities dimensions across 10 evaluations.
-
OpenAI pivots from the “wrong side of history” to aligning with “America-first AI”: With mounting competitive pressure from strong open-weight frontier reasoning models from DeepSeek, Alibaba Qwen and Google DeepMind’s Gemini and the US Government pushing for America to lead the way across the AI stack, OpenAI released their first open models since GPT-2: gpt-oss-120b and gpt-oss-20b in August 2025. These adopt the MoE design using only 5.1B (of 120B) and 3.6B (of 20B) active parameters per token and grouped multi-query attention. Post-training mixes supervised finetuning and reinforcement learning, with native tool use, visible reasoning, and adjustable thinking time. However, in the community vibes post-release have been mid, in part due to poor generalisation (similar to MSFT phi models) potentially due to over distillation.
-
The New Silk Road: China’s open models overtake the previously Meta-led West: The original Silk Road connected East and West through the movement of goods and ideas. The new Silk Road moves something far more powerful: open source models, and China is setting the pace. After years of trailing the US in model quality prior to 2023, Chinese models - and Qwen in particular - have surged ahead as measured by user preference, global downloads and model adoption. Meanwhile, Meta fumbled post-Llama 4, in part by betting on MoE when dense models are much easier for the community to hack with at lower scales.
-
Once a “Llama rip-off”, developers are increasingly building on China’s Qwen: Meta’s Llama used to be the open source community’s darling model, racking up hundreds of millions of downloads and plentiful finetunes. In early 2024, Chinese models made up just 10 to 30% of new finetuned models on Hugging Face. Today, Qwen alone accounts for >40% of new monthly model derivatives, surpassing Meta’s Llama, whose share has dropped from circa 50% in late 2024 to just 15%. And this isn’t because the West gave up. Chinese models got a lot smarter and come in all shapes and sizes - great for builders!
-
Why are researchers going Chinese? China’s RL tooling and permissive licenses are steering the open-weight community. ByteDance Seed, Alibaba Qwen and Z.ai are leading the charge with verl and OpenRLHF as go-to RL training stacks, while Apache-2.0/MIT licenses on Qwen, GLM-4.5 and others make adoption frictionless. Moreover, model releases come in many shapes and sizes to facilitate developer adoption of all flavors.
-
World models step out of the clip: real-time, interactive video arrives: Prior clip models (Sora, Gen-3, Dream Machine, Kling) render fixed videos you can’t steer mid-stream. World models predict the next frame from state and your actions, enabling closed-loop interactivity and minute-scale consistency. Crucially, no game engines were harmed!
-
Prior clip models (Sora, Gen-3, Dream Machine, Kling) render fixed videos you can’t steer mid-stream. World models predict the next frame from state and your actions, enabling closed-loop interactivity and minute-scale consistency. Crucially, no game engines were harmed!
-
Training agents inside of scalable world models: Dreamer 4 trains a video world model that can predict object interactions and future frames, then learns its policy entirely in imagination. A new “shortcut forcing” objective and an efficient transformer make the model run at real-time speeds on a single GPU. The agent is the first to reach diamonds in Minecraft using offline data only, outperforming OpenAI's VPT while using roughly 100x less labeled data.
-
China's video generation matures: a strategic divergence: From late‑2024, Chinese labs split between open‑weight foundations and closed‑source products. Tencent seeded an open ecosystem with HunyuanVideo, while Kuaishou’s Kling 2.1 and Shengshu’s Vidu 2.0 productize on speed, realism and cost. Models tend to use Diffusion Transformers (DiT), which replace convolutional U-Nets with transformer blocks for better scaling and to model joint dependencies across frames, pixels, and tokens.
-
OpenAI launches Sora 2: controllable video-and-audio inches toward a world simulator: OpenAI's second-gen Sora adds synchronized dialogue and sound, stronger physics, and much tighter control over multi-shot scenes. It can also insert a short “cameo” of a real person with their voice and appearance into generated footage, and launches alongside an invite-only iOS app for creation and remixing.
- Despite being a video model, Sora 2 can “solve” text benchmarks when framed visually. EpochAI tested a small GPQA Diamond sample and Sora 2 reached 55% (vs 72% for GPT-5) by prompting for a video of a professor holding up the answer letter. Four videos were generated per question and any clip without a clear letter was marked wrong.
- A likely explanation is a prompt-rewriting LLM layer that first solves the question and then embeds the solution in the video prompt, similar to re-prompting used in some other video generators.
-
Generated worlds enable practical open-ended learning: Open endedness describes a learning system that continually proposes and solves new tasks without a fixed endpoint, selecting tasks that are both novel and learnable, and accumulating the resulting skills so they can be reused to reach further, harder tasks. Interactive and persistent world models make this increasingly feasible.
-
How should we measure progress on open-endedness? Open endedness describes a learning system that continually proposes and solves new tasks without a fixed endpoint, selecting tasks that are both novel and learnable, and accumulating the resulting skills so they can be reused to reach further, harder tasks. Interactive and persistent world models make this increasingly feasible.
-
From tools to collaborators: AI agents as partners in discovery: AI is moving from answering questions to generating, testing, and validating new scientific knowledge. New “AI labs” organize coalitions of agent roles (PI, reviewers, experimenters) that ideate, cite, run code, and hand results back to human teams, shortening the loop from hypothesis to validation.
-
Diffusion language models: parallel denoising challenges autoregression: Diffusion LLMs generate by iteratively denoising masked sequences with full-context attention, updating many tokens in parallel at each step. Recent systems now reach competitive 7-8B quality, add arbitrary-order generation and infilling, and expose useful quality-latency trade-offs.
-
Tokenizer-free LLMs via dynamic byte patches: The Byte Latent Transformer (BLT) learns directly from bytes and uses entropy-driven “patches” as the compute unit. At 8B, BLT matches tokenized LLM quality while opening a new scaling axis and cutting inference FLOPs for the same quality. Follow-on work pushes dynamic chunking and adaptation beyond fixed tokenizers.
-
Attention sinks aren’t a bug…they’re the brakes: Attention is the transformer’s core mechanic. Many heads learn an ‘attention sink’ at the first position that stabilizes computation by throttling over-mixing as depth and context grow. There’s been debate over why models learn this and what it’s for.
-
LLMs are professional yes-men, and we trained them to be that way: "Sycophancy" isn't a bug, it's exactly what human feedback optimisation produces. A study of five major LLMs shows they consistently tell users what they want to hear rather than the truth.
-
Can vision models align with human brains…and how does that alignment emerge? By systematically varying model size, training scale, and image type in DINOv3 (Meta’s latest self-supervised image model trained on billions of images), researchers show that brain-model convergence emerges in a specific sequence. They find that early layers align with sensory cortices, while only prolonged training and human-centric data drive alignment with prefrontal regions. Larger models converge faster, and later-emerging representations mirror cortical properties like expansion, thickness, and slow timescales.
-
Merging the virtual and physical worlds: pre-training on unstructured reality: The new generation of robotic agents is built on a foundation of large-scale pre-training, but the key innovation is a move away from expensive, annotated datasets. The frontier is now focused on leveraging vast quantities of unlabeled, in-the-wild video to learn world models and physical affordances.
-
Computer Use Agents (CUA) have improved by leaps and bounds, and still fall short: Research labs like OpenAI, Anthropic, and ByteDance have been hard at work creating benchmarks and interaction methods for native language model computer use. While the use of RL and multi step reasoning has led to large improvements by and large the models still fall short.
-
Building agents that remember: from context windows to lifelong memory: Agent memory is shifting from ad-hoc context management to structured, persistent systems. The frontier is now beyond retrieval and into dynamic consolidation, forgetting, and reflection to allow agents to develop coherent identities across interactions, tasks, and even lifetimes…
-
Computer Use Agents (CUA) have improved by leaps and bounds, and still fall short: Research labs like OpenAI, Anthropic, and ByteDance have been hard at work creating benchmarks and interaction methods for native language model computer use. While the use of RL and multi step reasoning has led to large improvements by and large the models still fall short.