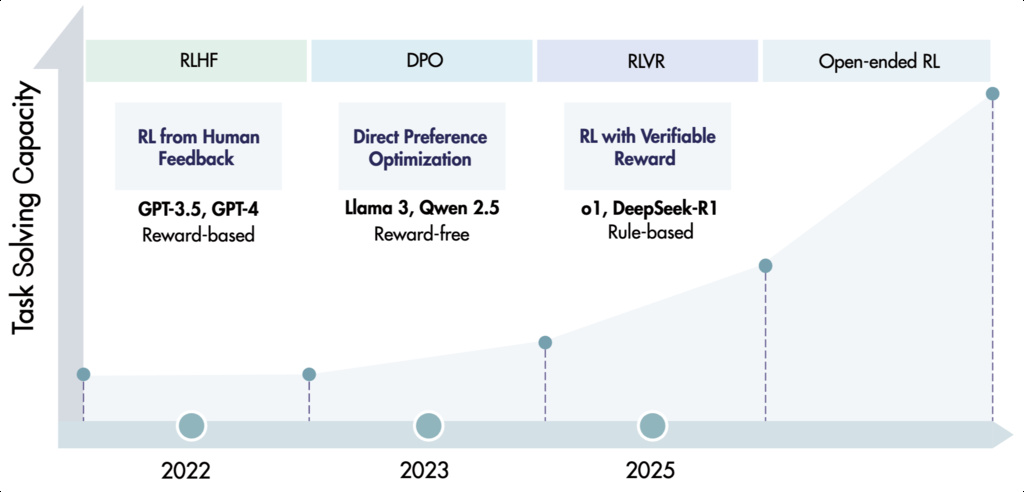
Reinforcement Learning for Large Reasoning Models
1. Background
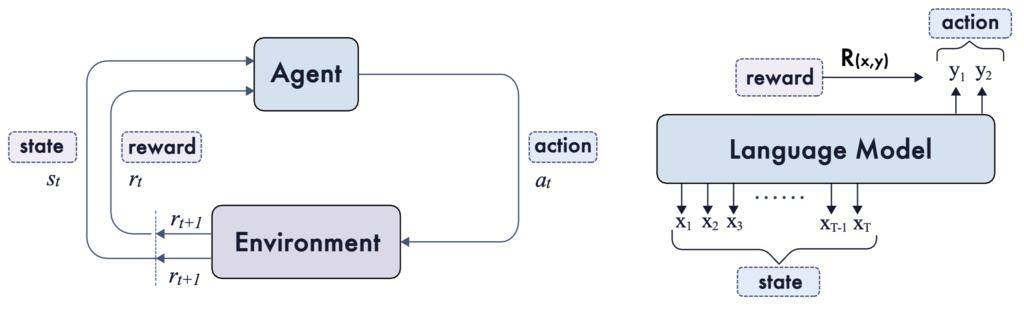
In classical RL, the problem is typically formulated as a Markov Decision Process (MDP), which is defined by a tuple . The main components include a state space , a action space , a transition dynamics , a reward function , and a discount factor . At each step, the agent observes a state , select an action according to its policy parameterized by , receives a reward , and transits to the next state . Theses concepts can be naturally mapped to the language domain with minimal adaptation.
The learning objective is to maximize the expected cumulative reward over the data distribution , that is,
1.1. Foundational Components
1.1.1. Reward Design
1.1.1.1. Verifiable Rewards
- Rule-based rewards provide scalable and reliable training signals for RL, especially in math and code tasks, by leveraging accuracy and format checks.
- Verifier's law highlights that tasks with clear and automatic verification enable efficient RL optimization, while subjective tasks remain challenging.
1.1.1.2. Generative Rewards
-
Model-based Verifiers for Verifiable Tasks.
Rule-based systems are brittle, often missing correct answers in unexpected formats; Specification-Based GenRMs address this by serving as flexible, model-based verifiers. -
Generative Rewards for Non-Verifiable Tasks
Another key use of GenRMs is in Assessment-Based GenRMs, which enable RL when Verifier's Law fails—evolving from zero-shot LLM evaluators to co-evolving, sophisticated systems.-
Reasoning Reward Models (Learning to Think)
Train RMs to explicitly reason before rendering a judgment. -
Rubric-based Rewards (Structuring Subjectivity)
Rubrics use natural language to express nuanced criteria suited to non-verifiable domains. -
Co-Evolving Systems (Unifying Policy and Reward)
The most advanced paradigm moves beyond a static policy-reward relationship and toward dynamic systems where the generator and verifier improve together.- Self-Rewarding
- Co-Optimization
-
1.1.1.3. Dense Rewards
Outcome rewards may face issues such as sparse rewards and slow convergence speed

- Token-Level Rewards
-
Step-Level Rewards
- Model-based
- Sampling-based
-
Turn-level Rewards
- Direct per-turn supervision
- Deriving turn-level from outcome
1.1.1.4. Unsupervised Rewards
-
Unsupervised rewards eliminate the human annotation bottleneck, enabling reward signal generation at the scale of computation and data, not human labor.
-
Main approaches include deriving signals either from the model's own processes (model Specific: consistency, internal confidence, self-generated knowledge) or from automated external sources (model-agnostic: heuristics, data corpora).
-
Model-Specific Rewards
- Rewards from Output Consistency
- Rewards from Internal Confidence
- Rewards from Self-Generated Knowledge
-
Model-Agnostic Rewards
- Heuristic Rewards
- Data-Centric Rewards
1.1.1.5. Rewards Shaping
- Rule-based Reward Shaping
- Structure-based Reward Shaping
1.1.2. Policy Optimization
1.1.2.1. Policy Gradient Objective
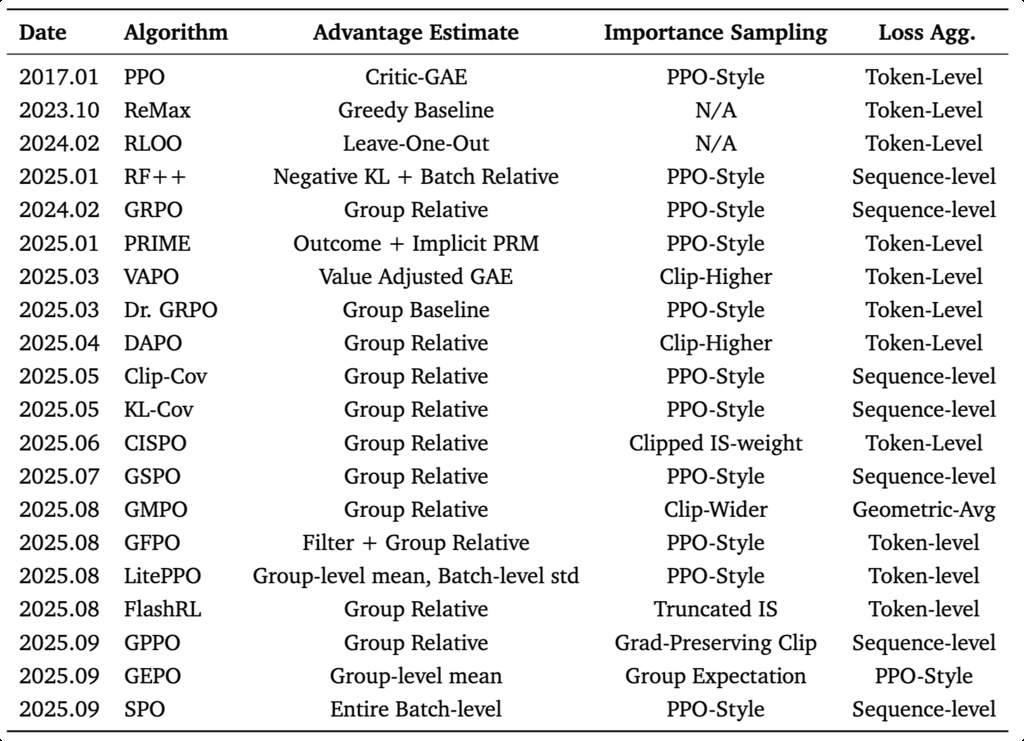
1.1.2.2. Critic-based Algorithms
See PPO.
- The critic model is trained on a small subset of labeled data, and provides scalable tokenlevel value signals for unlabeled roll-out data.
- The critic is required to run and update alongside the LLM, resulting in a significant computational overhead and scales unfavorably for complex tasks.
1.1.2.3. Critic-Free Algorithms
See GRPO.
- Critic-free algorithms only require sequence-level rewards for training, making them more sufficient and scalable.
- For RLVR tasks, rule-based training signals reliably prevent critic-related issues such as reward hacking.
1.1.2.4. Off-policy Optimization
- Training-Inference Precision Discrepancy
- Asynchronous Off-policy Training
-
Off-Policy Optimization
- Optimizer-Level Off-Policy Methods
- Data-Level Off-Policy Methods
- Mix-Policy Methods
1.1.2.5. Regularization Objectives
- KL Regularization
- Entropy Regularization
- Length Penalty
1.1.3. Sampling Strategy
1.1.3.1. Dynamic and Structure Sampling
-
Dynamic Sampling
- Efficiency-oriented Sampling
- Exploration-oriented Sampling
-
Structured Sampling
- Search-driven Tree Rollouts
- Shared-prefix or Segment-wise Schema
1.1.3.2. Sampling Hyper-parameters
- Exploration and Exploitation Dynamics
- Length Budgeting and Sequence Management
2. Foundational Problems
2.1. RL's Role: Sharpening or Discovery
The Sharpening view suggests that RL does not create genuinely novel patterns, but instead refines and reweights correct responses already contained within the base model. By contrast, the Discovery view claims that RL is capable of uncovering new patterns that the base model does not acquire during pre-training and would not generate through repeated sampling.
Unified view: RLHF as implicit imitation learning; SFT as inverse RL—both within a distribution-matching, reward-optimization framework.
Research focus: From "Sharpening vs. Discovery" to identifying the regimes where each dominates.
2.2. RL vs. SFT: Generalize or Memorize
- Which method better enables out-of-distribution generalization?
- Does behavior cloning via SFT set an upper bound on generalization capabilities?
RL tends to achieve "true generalization" on verifiable tasks and undersubstantial distribution shifts, but it is not a panacea. Modified SFT can help bridge the remaining gaps in generalization.Consequently, best practices are converging towards unified or alternating hybrid paradigms that combine the strengths of both approaches.
2.3. Model Prior: Weak and Strong
Key dimensions: the comparative advantages of applying RL to base versus instruction-tuned models, the substantial variations in RL responsiveness across different model families (particularly between Qwen and Llama architectures).
As RL increasingly serves to resharpen latent pretraining competencies rather than create novel abilities, the focus shifts toward optimizing the pretraining-to-RL pipeline holistically rather than treating these stages independently.
2.4. Training Recipes: Tricks or Traps
RL training for large models has primarily evolved from the PPO series, maintaining stability through a variety of engineering techniques such as trimming, baseline correction, normalization, and KL regularization.
While practical "tricks" are valuable for stabilizing RL training, the essence of"scientific training" lies in verification and scalability, e.g., Scaling Laws.
2.5. Reward Type: Process or Outcome
In standard RL, the objective of the policy is to maximize the expected cumulative reward. The "Reward is Enough" hypothesis further posits that appropriately designed rewards are sufficient and that maximizing returns can, in principle, give rise to all aspects of intelligence.