Linear RNNs and Attention
1. How to Make Attention More Efficient?
- Optimize Kernels: Flash Attention (IO complexity reduced)
- Refine Attention: Make Attention "Sparse" (In a way that reduces KV cache size)
- Beyond Attention: Make RNNs Great Again (Redesign RNNs to scale them up)
1.1. Flash Attention
See Flash Attention
1.2. How to reduce KV Cache
- Prefilling Phase: Process the input tokens to build the KV cache for generating the first output token
- Decoding Phase: Generate each subsequent token based on the stored KV cache
Size required for KV Cache:
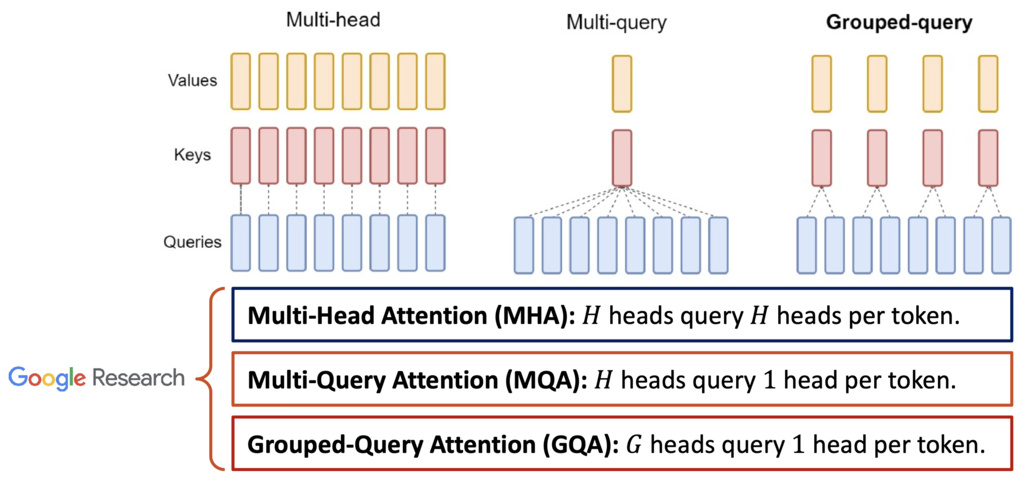
1.2.0.1. Reduce the number of heads (Reduce )
Grouped-Query Attention (GQA)
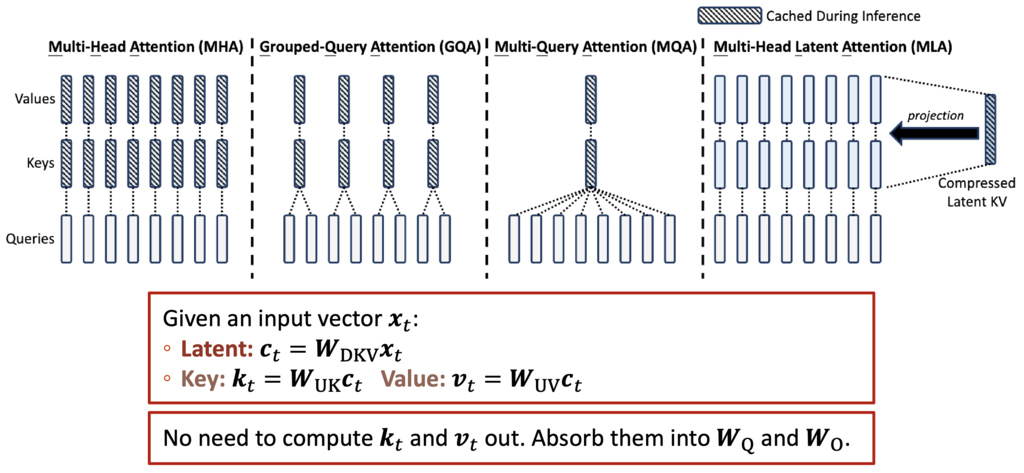
1.2.0.2. Only store some lower-dim latents (Reduce )
Multi-Head Latent Attention (MLA)
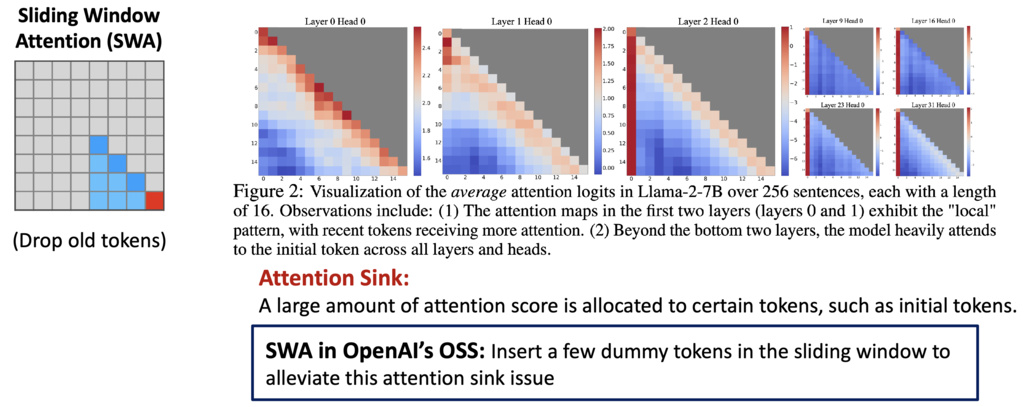
1.2.0.3. Store KV only for some tokens (Reduce )
Sliding Window Attention (SWA)
1.2.0.4. Store KV only for some layers (Reduce )
Cross-Layer Attention (CLA)
1.3. Modern RNNs
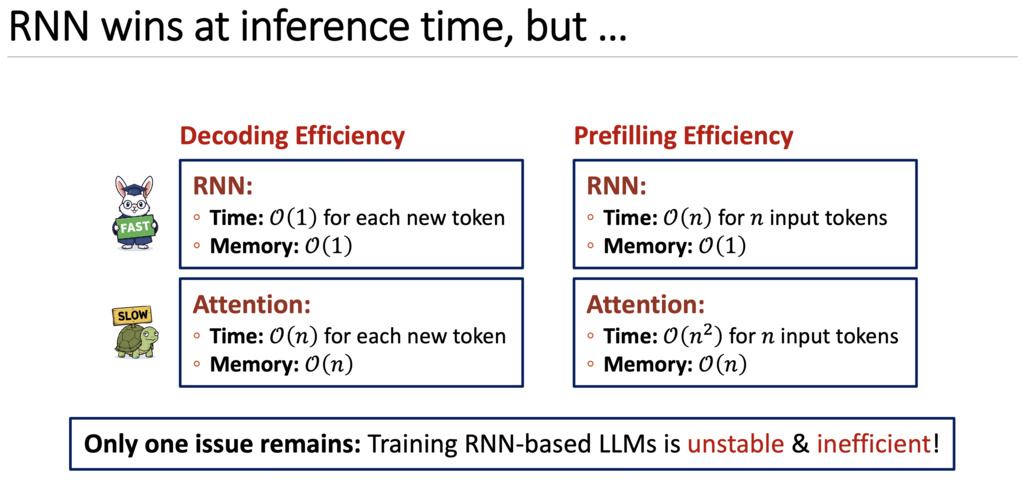

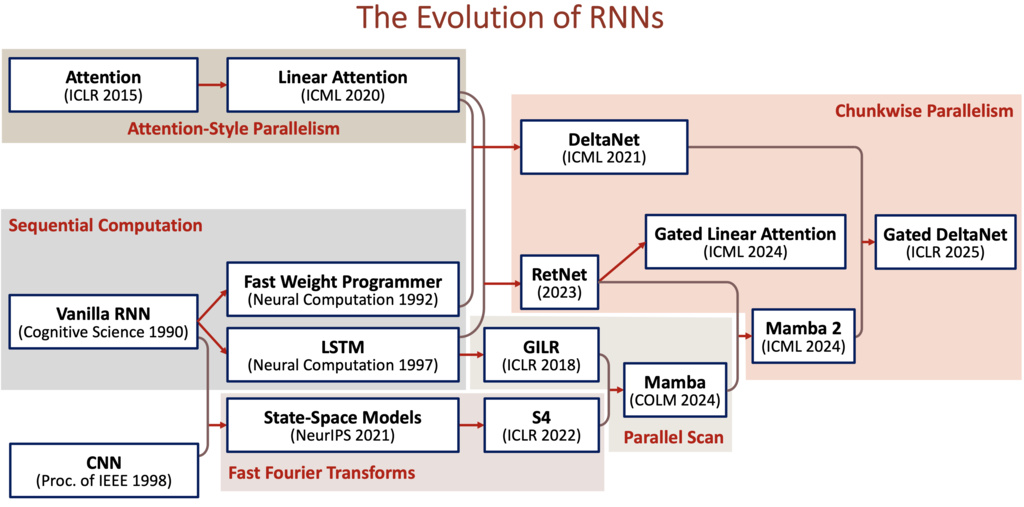
1.3.1. From Linear RNNs to Mamba
1.3.1.1. Can we parallelize Linear RNNs?
Yes! We can convert a Linear RNN to Prefix Sum Problem and solve it in time.
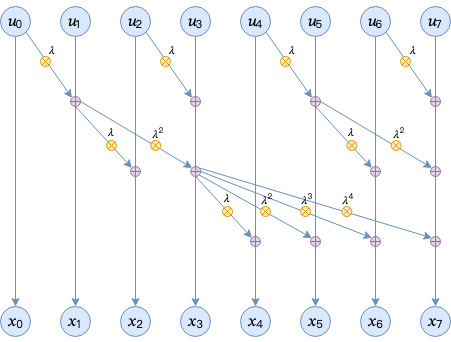
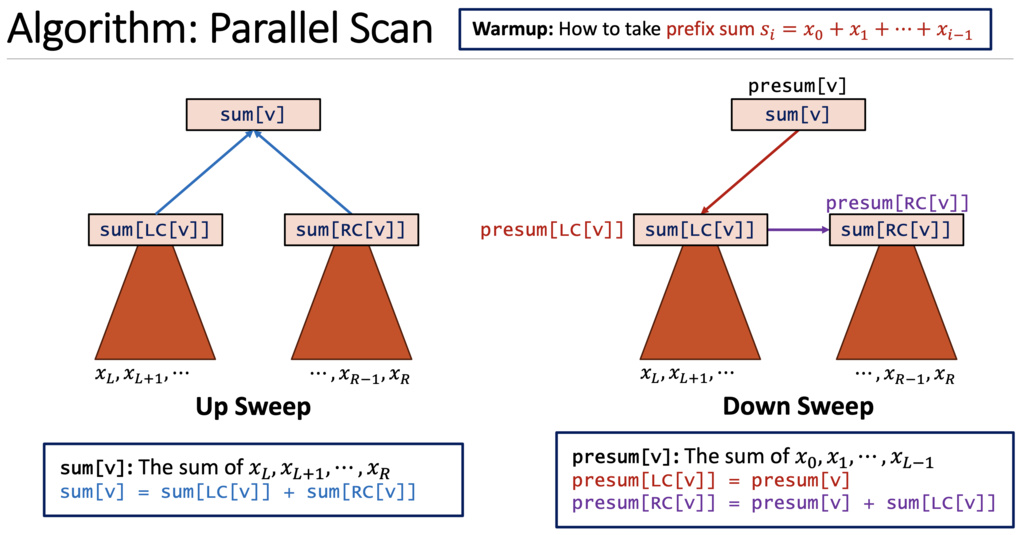
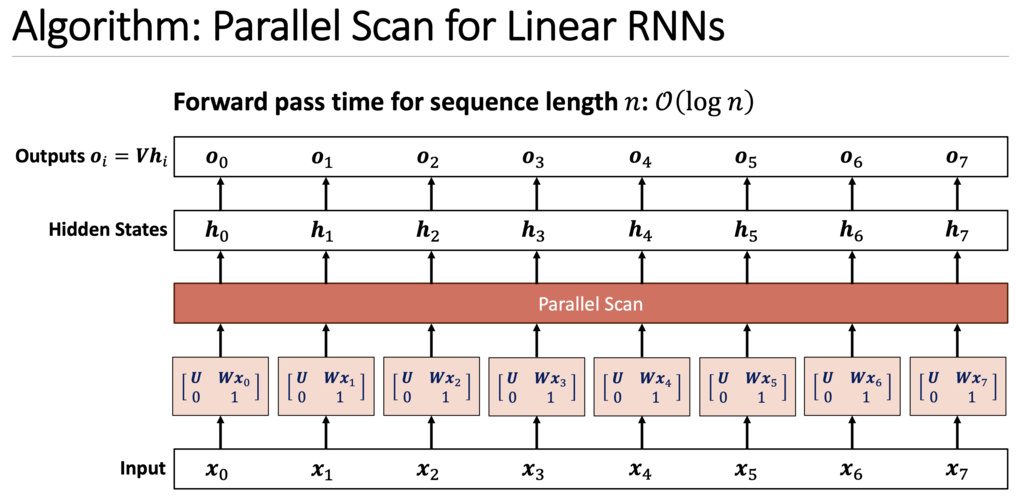
Although the state transition is linear, nonlinearity can be introduced elsewhere.


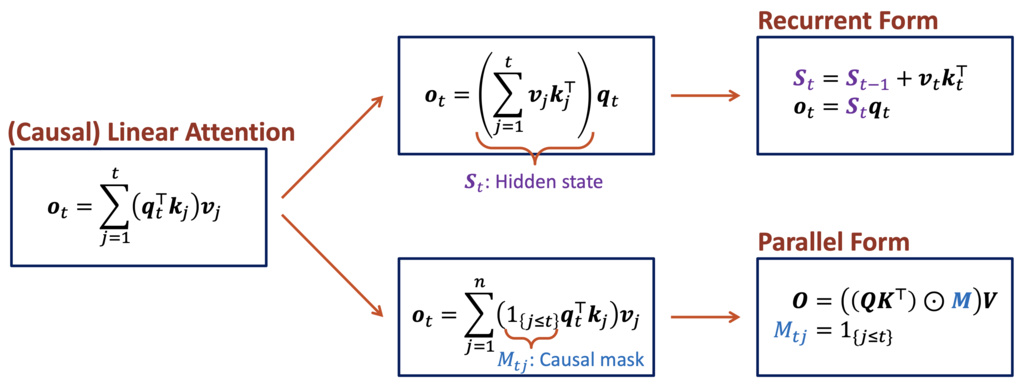
1.3.1.2. From Linear Attention to DeltaNet
Linear Attention can be seen as a special type of RNN.
Standard softmax attention has quadratic complexity: and memory.
Linear Attention tries to rewrite softmax attention:
- Notice softmax and RMSNorm afterwards are both doing normalization, we can take
References
- Kaifeng Lyu's PPT