ColBERT and FILIP
1. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
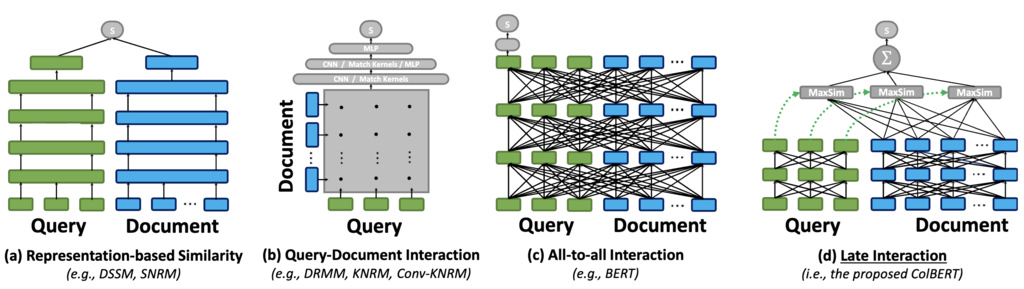
The field of Information Retrieval (IR) has seen remarkable progress with the advent of deep language models. These models, often based on the Transformer architecture, achieve state-of-the-art effectiveness in ranking tasks. However, their computational cost poses a significant challenge for real-world deployment, where query latency is a critical metric.
A typical neural ranker computes a relevance score for a given query and a document . The core issue is that computing this score often requires a joint, deep encoding of the query-document pair, making it impossible to pre-compute document representations offline. Let and represent the sets of contextualized token embeddings for the query and document, respectively, where each embedding is a vector in .
To address this efficiency bottleneck, ColBERT proposes a novel late interaction architecture. Instead of joint encoding, we independently encode the query and document and perform a lightweight, yet powerful, interaction step afterward. The final score is computed as a sum of maximum similarities:1
The model is trained end-to-end by minimizing a pairwise ranking loss function.
2. FILIP: Fine-grained Interactive Language-Image Pre-Training
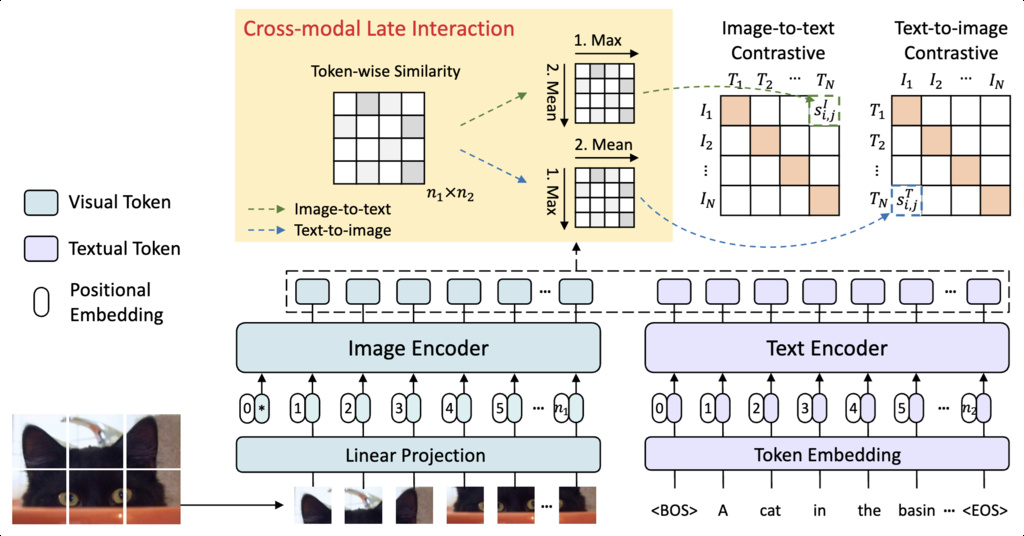
Vision-Language Pre-training (VLP) models like CLIP have demonstrated powerful capabilities by aligning global image and text features. However, this global alignment approach lacks the ability to capture finer-grained relationships, such as the correspondence between specific objects in an image and words in a text description.
To address this, the FILIP (Fine-grained Interactive Language-Image Pre-training) model was introduced. It enhances cross-modal alignment by adopting a late interaction mechanism inspired by ColBERT. This mechanism operates directly within the contrastive learning objective.
Instead of comparing single global feature vectors, FILIP computes a token-wise similarity matrix between all image patch embeddings and all text token embeddings . The final image-to-text similarity score is calculated by taking the average of token-wise maximum similarities:
where and are the number of image and text tokens, respectively. A symmetric operation is performed to compute the text-to-image similarity . This encourages a detailed alignment between image patches and textual words.
The model is trained using a standard contrastive loss over batches of image-text pairs. The key advantages are:
- It maintains the efficiency of dual-stream models, allowing for offline pre-computation of image and text representations.
- It achieves superior performance in downstream tasks, outperforming CLIP on zero-shot ImageNet classification and various image-text retrieval benchmarks, even with less training data.
- Visualizations confirm that FILIP learns meaningful, fine-grained alignments, correctly mapping textual tokens to corresponding image regions.
-
This approach is inspired by the idea that for a document to be relevant, each important concept in the query should find a strong semantic match within the document.