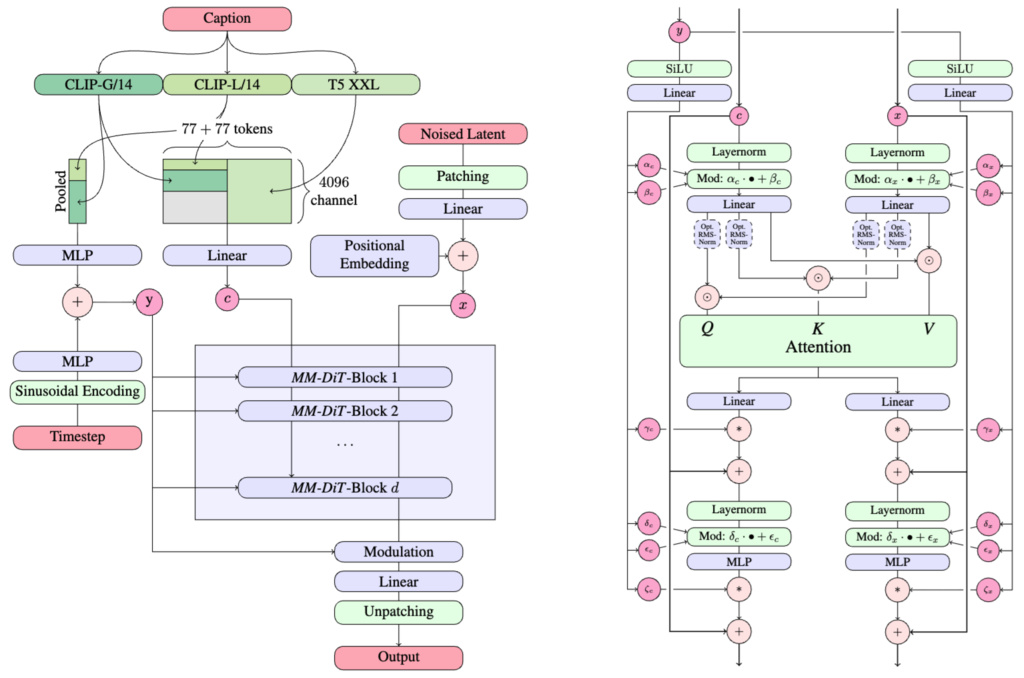
1. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
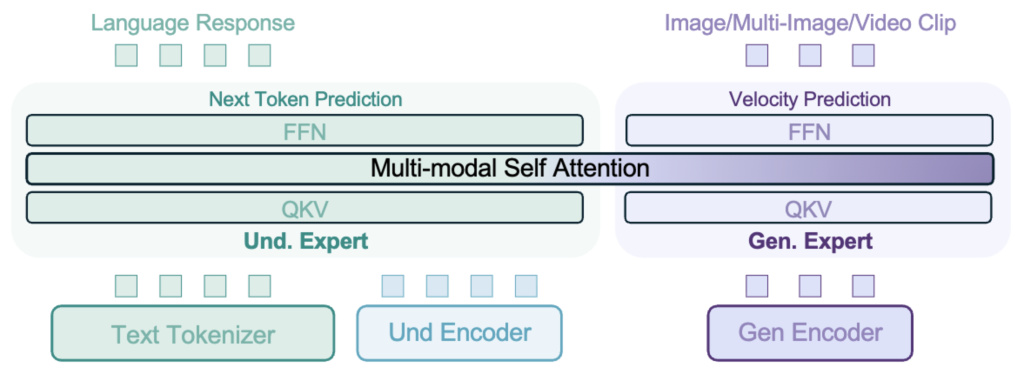
2. Emerging Properties in Unified Multimodal Pretraining
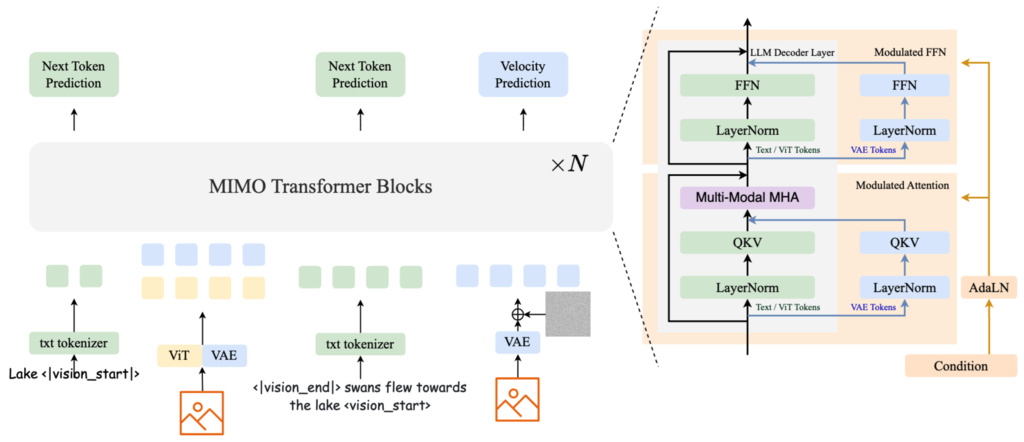
3. Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
Figure 3: The model consists of N modified LLM decoder layers, using different QKV matrix and FFN to process visual tokens. When the image is used as a condition, VAE and ViT are both used to extract visual features, and VAE is used alone when generating images. It is worth noting that we assign the same position id to the ViT token and its corresponding VAE token. The condition will modulate the visual token through an AdaLN layer.