Position Paper
1. Vision encoders should be image size agnostic and task driven
A four year old child has processed more bytes of visual data than what is contained in the largest text corpora used to train modern large language models (LLMs).
The goal of vision is not to process and understand every detail of what we are seeing, but to extract biologically relevant information.
A path towards better and more efficient vision encoders, is one that focuses on models that are task-driven and image size agnostic.
1.1. Why Image Size Agnostic?
-
Current Challenge: In models like ViT, compute grows quadratically with the number of tokens/patches (proportional to image size), which is problematic for high-resolution images from modern cameras.
-
Distribution Shift: With bottom-up patch extraction, the same 'patch' from two differently sized images can have totally different semantic meaning, causing distribution shift between training and inference.
-
Biological Insight: The fovea in the human eye covers only a small angle with high acuity; elsewhere vision is low-res, and we move our gaze to focus. Efficient vision systems should emulate this.
-
Proposed Method: The authors present a top-down multi-zoom patch mechanism:
- At each step, patches are extracted from a selected center with several 'zooms' (from large, low-res areas to small, high-res regions).
- All patches are resized to a fixed dimension before entering the transformer (e.g., 16x16).
- Importantly, the number and size of patches are determined by the task requirement, not the input image size.
1.2. Why Task Driven?
-
Current Limitation: Most vision encoders are task-agnostic: they extract the same features regardless of what downstream task is being done.
-
Argument: Different tasks (classification, localization, "Where's Waldo?") demand very different attention and processing strategies. For efficient and relevant feature extraction, the system should be steered by the task prompt.
-
Analogy: If you're questioned after briefly seeing an image, you'll struggle to recall unanticipated details. But if you know the task/question in advance, you'll look more efficiently.
-
Implication: An iterative vision encoder can process context in a way that is dynamically guided by the task head/prompt—much more biologically plausible.
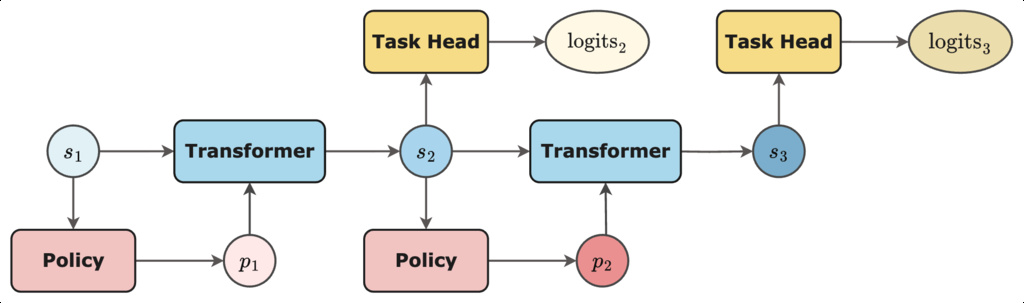
1.3. Proof-of-Concept Architecture
The authors propose and evaluate a prototype system:
-
Top-Down Patch Extraction: Given a center (x, y) and multiple zoom levels, extract patches (parametrized by center and scale) dynamically. This is both hardware-friendly and suitable for variable image sizes.
-
Iterative Transformer with Internal State: Rather than processing all patches at once, the transformer receives a set of patches plus a learned internal state, updates the state, and this proceeds for several iterations—mirroring sequential human gaze.
-
The internal state is implemented as a set of learned vectors (inspired by ViT registers and DETR queries), passed between iterations.
-
Learned Policy (Where to Look Next): A policy network (trained with reinforcement learning, specifically Group Relative Policy Optimization/GRPO) takes the current internal state and predicts where to extract the next patch group.
-
Task Head: At every iteration, the state is sent to the task head (e.g., for classification).
- Stage 1: Pretrain transformer and task head with a random policy for patch selection.
- Stage 2: Freeze transformer and train the patch selection policy to maximize task performance.
1.4. Open Questions & Limitations
-
End-to-End Training: How to co-train transformer and policy (the state observed by the policy is non-stationary as transformer parameters shift; RL and supervised SL have quite different training dynamics).
-
Scaling to Self-Supervised Learning: How to define policy rewards in generic self-supervised pretraining (as opposed to simple classification loss)?
-
Differentiable Policy Alternatives: Is RL optimal or could differentiable policies (implicit neural representations, etc.) facilitate proper end-to-end training?
-
Random Policy Issue: Random policies work surprisingly well for image classification, possibly masking the value of a task-driven policy for this task.
-
Task Prompting in Pretraining: How to properly bring task-prompted vision feature extraction into the era of generic, highly reusable visual backbones?