GRPO
1. The Limitations of Reward-Only Approaches
Naive reinforcement learning approaches that rely solely on reward signals suffer from two fundamental limitations: high variance in gradient estimates and insufficient incentives for incremental improvements. Without an appropriate baseline, the policy (Actor) lacks a reference point that reflects its current performance level, significantly hindering training efficiency.
The solution involves establishing a baseline and measuring relative performance improvements. Formally, the advantage function is defined as:
For a given state and action , a positive advantage indicates that the actual reward exceeds the critic's expectation, signifying above-average performance.
2. Challenges in Advantage Estimation
However, advantage-based methods introduce additional complexities. When the policy achieves an unexpectedly high reward, the critic adjusts its expectations upward. This adjustment may reflect temporary performance fluctuations rather than sustained improvement, potentially driving the actor toward overly aggressive exploration strategies. Conversely, underestimating breakthrough performance by assigning low advantages fails to provide adequate learning signals.
3. Proximal Policy Optimization Framework
Proximal Policy Optimization (PPO) (schulman2017proximal) addresses these stability concerns through ratio clipping. The policy ratio is defined as:
and constrained within to limit the magnitude of policy updates per iteration.
Additionally, PPO incorporates a KL divergence penalty against a reference model (typically the initial policy) to prevent the policy from deviating excessively from its original behavior distribution, thereby mitigating reward hacking and maintaining training stability.
The complete PPO objective function is:
where and represent questions and outputs sampled from the dataset and old policy, respectively. The advantage is computed using Generalized Advantage Estimation (GAE) (schulman2016high).
4. Computational Limitations of PPO in LLM Settings
While PPO's actor-critic framework with clipping and KL regularization provides theoretical guarantees, it faces practical limitations in large language model (LLM) applications. The critic network must typically match the actor's capacity to accurately evaluate high-dimensional state spaces, resulting in substantial computational overhead. This burden becomes particularly pronounced in scenarios with sparse reward signals, such as final answer evaluation tasks.
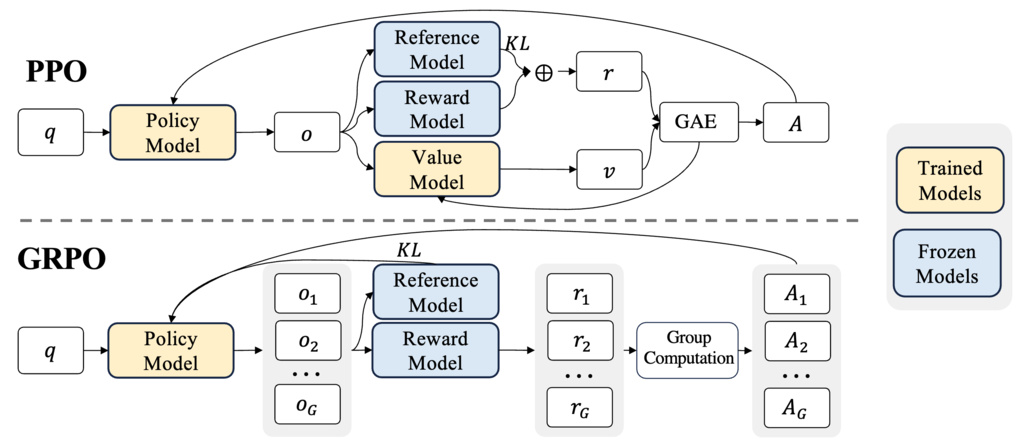
5. Group Relative Policy Optimization
Group Relative Policy Optimization (GRPO) (shao2024deepseekmath) addresses these computational challenges through a fundamentally different approach to baseline estimation. The key innovations include:
- Elimination of the value network: GRPO foregoes the separate critic network entirely
- Group-based sampling: Multiple outputs are generated from the current policy for each input state
- Relative advantage computation: The average reward across grouped outputs serves as the baseline
- Preserved stability mechanisms: PPO's clipping and KL regularization are retained
The GRPO objective function is formulated as:
where the relative advantage is computed as:
This formulation establishes a dynamic, context-aware baseline through group statistics while eliminating the computational overhead of maintaining a separate value function. The approach maintains the stability properties of PPO while significantly reducing training resource requirements.
References
- Schulman, J., Moritz, P., Levine, S., Jordan, M. I., and Abbeel, P. High-Dimensional Continuous Control Using Generalized Advantage Estimation. International Conference on Learning Representations (ICLR), 2016.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal Policy Optimization Algorithms, 2017.
- Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y. K., Wu, Y., and Guo, D. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024.