Pre-training and Post-training of image generation model
1. The core problem: avoiding the “AI look”
Many modern image models over-optimize for capability metrics (text rendering, attribute binding, counting, etc.) and drift into the “AI look”: overly smooth skin, shallow depth-of-field, bland compositions, oversaturated or uniformly bright images.
Aesthetics scorers widely used for training or evaluation (e.g., LAION-Aesthetics, Pickscore, ImageReward, HPSv2), often built on low-res CLIP finetunes, struggle to rank images from today's stronger models and encode biased preferences (e.g., favoring certain subjects like female portraits, soft focus, high brightness).
Human aesthetics are subjective and multi-dimensional, so a single score is inadequate. The fix is better data curation and output alignment to maintain tasteful defaults without collapsing diversity.
2. The art of mode collapse
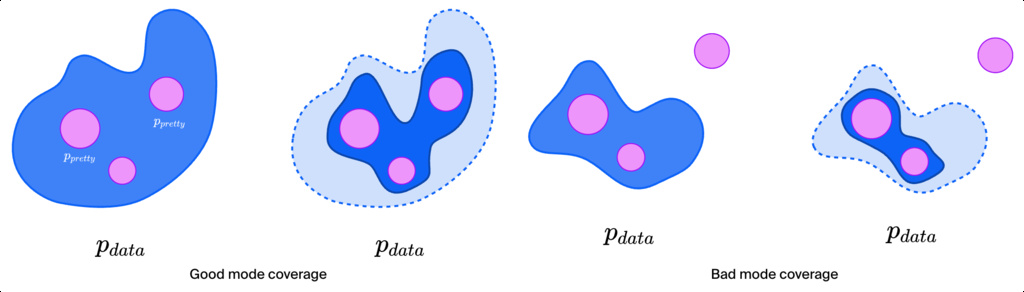
Pretraining for mode coverage: maximize diversity in styles, subjects, and scenes, and deliberately keep “bad samples” so negative prompts actually work. This stage builds world knowledge and versatility.
Post-training for mode collapse: steer the distribution toward a target aesthetic. While pretraining sets the upper bound for diversity and structure, the perceived final quality is largely determined by post-training.

3. Some findings
- quality over quantity: fewer than 1 million top-tier samples were sufficient for strong post-training gains. More data helps stability and debiasing, but the decisive factor is curation quality.
- Take an opinionated approach: mixing heterogeneous aesthetic preferences leads to bland compromises—simple symmetric compositions, softened textures, color grading collapse—i.e., back to the “AI look.” Aesthetics are subjective, so alignment should intentionally “bias” toward a clear artistic direction to deliver better default outputs.