VLM Robustness
1. Does Language Training Improve Vision-Language Model Robustness?
A foundational goal of machine learning is to develop models that work reliably across a broad range of data distributions. A central theme of transformer language models is their ability to generalize. By scaling up data and model size, large language models develop emergent abilities that exceed expectations (wei2022emergent). They can also transfer knowledge across domains and tasks (i2024gpt) (brown2020language) (sanh2022multitask). Generalize in length (anil2022exploring) (cai2025extrapolation) and compositional instructions (zhao2024can) (yang2024exploring).
While language models trained on large-scale data tend to be robust to distribution shifts, vision models behave quite differently. Images are inherently noisy and high-dimensional; even small perturbations can push them out-of-distribution, and it's difficult to cover all possible modes. Therefore, improving the robustness of vision models is crucial for their deployment in real-world applications.
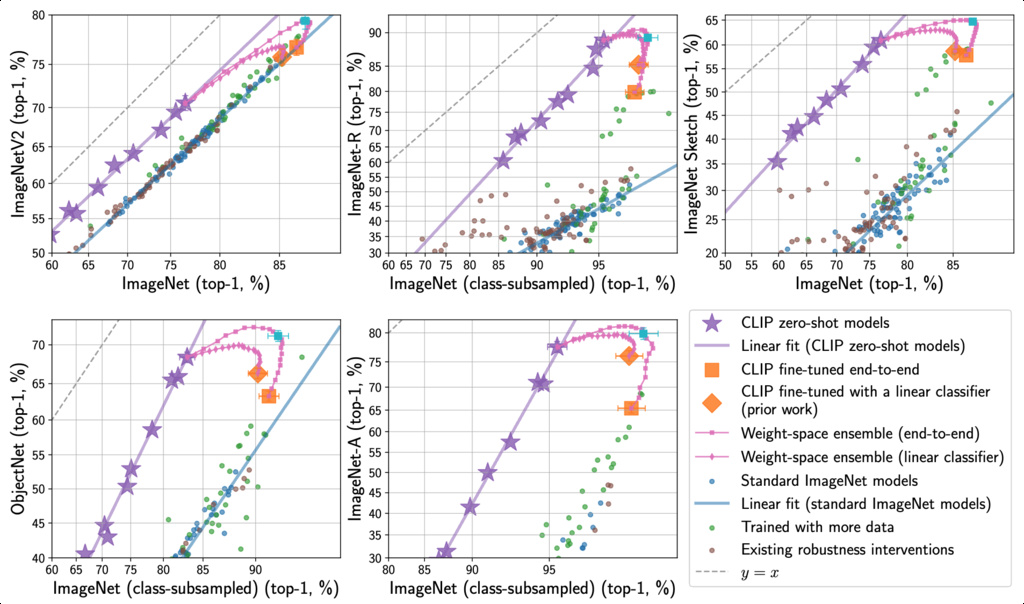
Previous work has demonstrated that CLIP and its variants exhibit greater robustness to distribution shifts compared to standard vision models (wortsman2022robust). This success suggests that pre-training on large, heterogeneous datasets represents a promising direction for increasing robustness (wortsman2022robust) (taori2020measuring). While CLIP is success regard to previous imagenet models, the effectiver robustness cannot surpass the line even with more data and different methods.
Contemporary vision-language models (VLMs) combine pretrained visual encoders with language models, utilizing large-scale datasets for visual instruction tuning (liu2023visual) (liu2023improved) (liu2024llava). These models excel in visual question answering, segmentation, detection, and other multimodal tasks.
Recent work have focused on "vision-centric" VLMs, reducing the reliance and bias on language priors (vo2025vision) (lee2025vl) (wu2025lanp) (leng2024mitigating).
Given the robustness and generalization of Language models and CLIP models, we wonder if such robustness can be transfer to VLMs. We systematically evaluate over 60 VLMs and over 60 visual encoders using carefully constructed multiple-choice classification benchmarks based on ImageNet and its variants.
1.1. Background
To measure robustness, we contrast model accuracy on two related but different distributions, a reference distribution and shifted distribution (wortsman2022robust).1 We assume both distributions have test sets for evaluation, and has an associated training set which is typically used for training or fine-tuning. The goal for a model is to achieve both high accuracy and consistent performance on the two distributions and . This is a natural goal as humans often achieve similar accuracy across the distribution shifts in our study (shankar2020evaluating). For a model , we let and refer to classification accuracy on the reference and shifted test sets, respectively.
Following (radford2019language), our focus here is on natural distribution shifts as they are more representative of the real world when no active adversary is present. Specifically, we present our key results for five natural distribution shifts derived from ImageNet (i.e., is ImageNet):
- ImageNetV2 (IN-V2) (recht2019do), a natural distribution shift derived from ImageNet (IN) (russakovsky2015imagenet) .
- ImageNet-R (IN-R) (hendrycks2021many), renditions (e.g., sculptures, paintings) for 200 ImageNet classes.
- ImageNet Sketch (IN-Sketch) (wang2019learning), which contains sketches instead of natural images.
- ObjectNet (barbu2019objectnet), a test set of objects in various scenes with 113 classes overlapping with ImageNet.
- ImageNet-A (IN-A) (hendrycks2021natural), a test set of natural images misclassified by a ResNet-50 (he2016deep) for 200 ImageNet classes.
To compare the robustness of models with different accuracies on the reference distribution, we follow the effective robustness framework introduced by (miller2021accuracy). Effective robustness quantifies robustness as accuracy beyond a baseline trained only on the reference distribution. A useful tool for studying (effective) robustness are scatter plots that illustrate model performance under distribution shift. These scatter plots display accuracy on the reference distribution on the -axis and accuracy under distribution shift on the -axis, i.e., a model is shown as a point . For the distribution shifts we study, accuracy on the reference distribution is a reliable predictor of accuracy under distribution shift. In other words, there exists a function such that approximately equals for models trained on the train set . Effective robustness (miller2021accuracy) is accuracy beyond this baseline, defined formally as .
In the corresponding scatter plots, effective robustness is vertical movement above expected accuracy under distribution shift. Effective robustness thereby disentangles accuracy changes on the reference distribution from the effect of robustness interventions. When we say that a model is robust to distribution shift, we mean that effective robustness is positive.
1.2. Related Work
(zhang2025out) use in-context learning (ICL) to improve out-of-distribution generalization.
(oh2025understanding) uses information theory to analyze the robustness of VLMs.
(oh2025visual) uses visual instruction bottleneck tuning to improve robustness.
Using RL to improve classification: (liu2025visual) (li2025think)
(li2024exploring) explores how generative mllms perceive more than clip with the same vision encoder.
1.3. Datasets Construction
The original ImageNet validation set is known to have several limitations, including incorrect labels, problematic class definitions, and duplicate or multi-label images (russakovsky2015imagenet) (vasudevan2022when) (northcutt2021pervasive). These issues can lead to an underestimation of true model performance. In response, (kisel2025flaws) consolidated prior label corrections to publish a "clean" label set. We use this label set in our evaluation.
Our evaluation employs a multiple-choice question format. As a baseline, we first constructed a benchmark by randomly sampling distractors. For each image, we created a 5-way multiple-choice question consisting of the ground-truth label and four incorrect labels chosen uniformly at random from the remaining 999 classes. We generated a test set of 5,000 such questions, a sample size sufficient to ensure statistically robust results (see Appendix Section A.3 for an analysis of sample size). However, this random sampling approach proved to be too simplistic; Most models achieve near-saturating accuracy on this task. This finding is consistent with prior work, which has shown that even with 26 random options, model performance remains above 95% (liu2024revisiting).
To create a more challenging and realistic evaluation, we leverage two types of obfuscation:
- Text obfuscation: We use ImageNet-hierarchy to select distractors that are semantically similar to the ground-truth label, making the classification task harder.
- Visual obfuscation: We use DION-v3 to select visually confusing distractors.
Although these two approaches generate quite different sets of choices, their results are very similar.
For simplicity, we focus on text obfuscation in the subsequent analysis.
1.4. Results
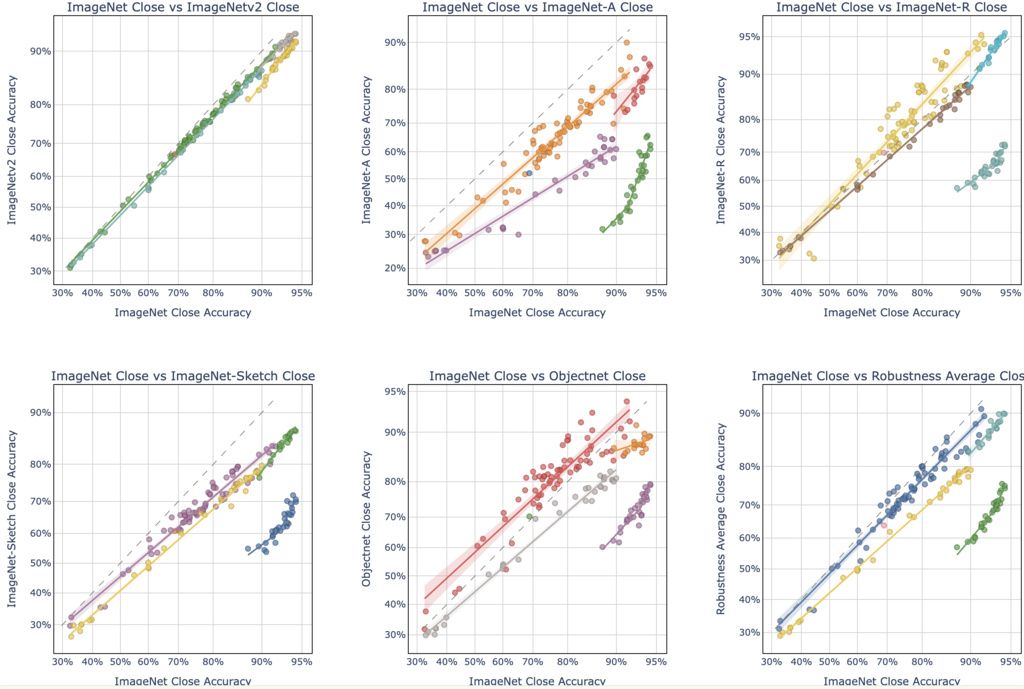
- On average, VLMs are more robust than visual encoders since they are more close to .
- Accuracy on the line.
- For VLMs, SigLip is more robust than CLIP, and web-scale-pretrained ViT is more robust than native training with VLM.
1.4.1. Visual Encoder primarily determine the robustness of VLMs
For VLMs, SigLip is more robust than CLIP, and web-scale-pretrained ViT is more robust than native training with VLM.
1.4.2.
On average, VLMs are more robust than visual encoders since they are more close to . But why? Do VLMs learn to use language to improve robustness? Or there's another reason? How can we leverage this to improve its visual encoder's robustness?
We think there are several possible reasons:
- Language supervision at test time via prompts ❌
- Large scale pretraining and instruction tunning data ❌
- The training distribution ❌
- Language supervision at training time ❌
- Using Patch tokens instead of cls tokens to encode images
- Using AnyRes and higher resolutions ❌
- Generative objectives instead of contrastive objectives ❌
We verified the above reasons one by one.
1.4.3. Language supervision at test time via prompts
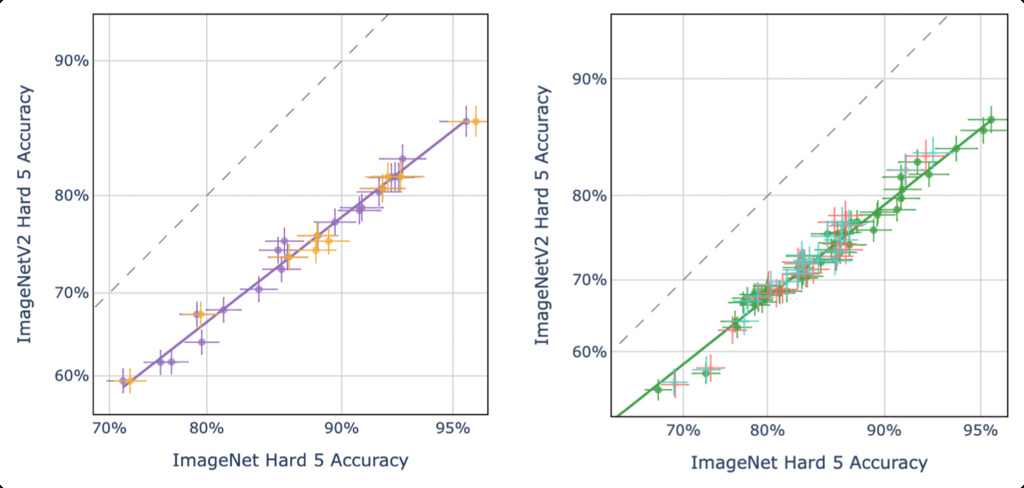
To ensure our findings are not artifacts of specific prompting strategies, we evaluate models using five different prompt formulations (detailed in Appendix Section A.4). Figure 3 demonstrates that varying prompt formats does not significantly alter the linear relationship, with all prompting strategies yielding points along the same trend line.
1.4.4. Large scale pretraining and instruction tunning data
- Small amount of instruction tunning data will arrive at the robustness line (1000 steps)
1.4.5. The training distribution
- Directly using instruction tunning data to train clip will not help
- Using CLIP and VLM co-training will not help
1.4.6. Language supervision at training time
- Initialize LLM and do instruction tunning and some openimages multiple-choice format learning still on VLM robustness line
- Different LLM have different backbone, but still on the same line
1.4.7. Using Patch tokens instead of cls tokens to encode images
Compressing token might decrease robustness.
Changing Patch tokens to cls tokens will not decrease robustness.
Using patch tokens to do early fusion contrastive learning will not help (yao2022filip) (mukhoti2023open) (zhang2024magiclens)
1.4.8. Using AnyRes and higher resolutions
- Resize images to 224 224 will decrease score, but still on the robustness line
- Change LLava-Onevision 'AnyRes' to 'pad' will decrease score, but still on the robustness line
- Finetuning 224 CLIP with 512 images still on the robustness line.
1.4.9. Generative objectives instead of contrastive objectives
We test VLM2Vec (jiang2024vlm2vec) (meng2025vlm2vec) models and VLM2Vec-LLava trained by (li2024exploring)
After caption pretraining of LLaVA, we fine-tune the VLM2Vec model using LoRA (hu2021lora) on two different datasets. The training is conducted using the LLaVA-1.5-7B model with SigLIP vision encoder as the backbone.
For hyperparameters, we set the learning rate to 2e-5 with a linear scheduler and 0.03 warmup ratio. Training is performed for 400 steps with a batch size of 64 per device using bf16 precision. We apply LoRA with rank to enable efficient fine-tuning while preserving model capacity. The temperature parameter for contrastive learning is set to 0.02, and we use last-token pooling for generating embeddings.
Two training configurations are used: (1) LLaVA finetuning dataset, and (2) CC12M recaption dataset (emporium2024conceptual), which is recaptioned by llama3-llava-next-8b and further cleaned by Meta-Llama-3-8B.
VLM2Vec uses contrastive training to adapt a vision-language model into an embedding model. For VQA dataset, we apply the instruction to the original query to generate an instruction-conditioned version:
And the target is the answer to the question. For caption dataset, we only let to achieve similar training strategy as CLIP models. And the target is the caption of the image.
Given a pretrained VLM, we feed query and target into it to obtain the query and target embeddings (, ) by taking the last layer vector representation of the last token. To train the embedding model, we adopt the standard InfoNCE loss (oord2019representation) over the in-batch negatives:
where is the set of in-batch negatives, and is a function that computes the matching score between query and target . We adopt the temperature-scaled cosine similarity function as , where is a temperature.
1.4.10. VQA data
Data is one of the deterministic factors in CLIP robustness, different data source might bring different robustness and simply mixing them will not help, quality is more important than quantity (nguyen2022quality).
Overall no pre-training data distribution is consistently the most robust across all evaluation settings.
2. Question-Guided Evidence Selection Explains and Transfers VLM Robustness
2.1. Abstract
We study why, under the same frozen visual encoder, vision-language models (VLMs) exhibit higher effective robustness than CLIP-style models on multiple distribution shifts. We first document a linear “law of robustness” in the probit plane and then give a simple high-dimensional theory showing (i) why models trained with the same frozen features fall on a line, (ii) what sets the line’s slope and which baseline the line passes through, and (iii) why VQA-style task signals raise that line via question-guided evidence selection. Finally, we convert this mechanism into a practical embedding recipe (vlm2vec) that improves OOD performance at matched ID accuracy.
2.2. 1. Introduction
- A paradox: with the visual encoder frozen, why can swapping only the task signal (caption vs VQA) move a model from the “CLIP line-family” up to the “VLM line-family”?
- Observational law: points (ID, OOD) in the probit plane align on lines; towers set line families (height), task signals set slopes and in-line positions.
- Our thesis: VQA acts as question-guided evidence selection over fixed features, rotating the effective decision toward cross-domain stable semantics, which increases slope and lifts the line.
- Contributions: a unified measurement protocol and theory; a mechanism (evidence selection) that explains VLM > CLIP under frozen towers; a deployable embedding recipe (vlm2vec).
We analyze a simple but canonical binary classification example where each training data is parametrized by its ground-truth linear classifier and its Signal-to-Noise Ratio (SNR) . Concretely, a training dataset is a set of i.i.d. paired samples from a joint distribution defined as follows.
Assumption 1 (Data distribution). We define a joint distribution as (i) uniformly at random, and (ii) where the noise is zero-mean and has independent entries with variance one. For an observation , we refer to as the signal power and as the corresponding noise power with SNR .
Assumption 2 (Trained model distribution). We consider a (random) linear model parameter that predicts a binary label for a test example . We assume that the random model , trained on is unbiased, , and that has independent entries with variance one each. The randomness comes from the training data as well as any internal randomness in the training algorithm. The parameter captures the variations in the resulting model distribution due to changes the training algorithm.
Concretely, one canonical example of a trained model is . It follows that with . Hence, measures the randomness of the trained model relative to this simple training algorithm.
We analyze the resulting accuracy when evaluated on two test distributions and as defined above, with , and defined similarly. In particular, we are interested in how the accuracy pair behaves as we vary the sample size and as we vary the training algorithm represented by . Here, is the inverse of the CDF of a standard Gaussian distribution, defined as where . is also called the probit function. This choice of mapping the accuracy with the probit function is critical in getting the linear relation, which we will explain in Remark 1.
Theorem 1 (Universality of accuracy on the line). Under Assumptions 1 and 2, asymptotically as the dimension grows linearly in the sample size such that , we have
Further, under Assumption 5 in the Appendix, for some universal constant ,
We provide a proof in Appendix F.1. This analysis implies that for any training sample size and any (variation due to the) training algorithm , the resulting accuracy pair after probit transform lies on a universal line determined by Eq., and the slope only depends on the two test distributions and the training distribution . The similarity between the training data and each test dataset is captured by the angles: and . More similar training data achieves a larger test accuracy. The hardness of the test distribution is captured by the SNR of each test dataset: and . We emphasize that this line is universal in the sense that the slope does not depend on the sample size and training algorithm parameter . We are interested in the regime where scales linearly in and both are large such that the second term in the above equation is negligible.
Remark 1. Why do we get the accuracy-on-the-line phenomenon? The prediction of the trained (random) linear model on a random test data point involves the inner product, which performs a natural spatial averaging over the coordinates. Since the noise across the coordinates is independent and has bounded variance, the central limit theorem applies. The resulting error has a Gaussian tail. Hence, the probit mapping, , is critical in translating accuracy into the relevant mean to standard deviation ratio: . This is consequently important for getting the universal linear relation, because irrelevant parameters, and , cancel out in the slope of . Refer to the proof of Theorem 1 (Appendix F.1) for more details.
Remark 2. Intersection at the random guess: Previous work that considered models with a wide range of accuracies has found that all lines intersect at a point corresponding to "random guess", which in this binary example is . Our theoretical analysis is consistent with this empirical observation: all universal lines intersect at up to a small additive error scaling as .
3. Proof of Theorem 1
Assumption 5. Under the hypotheses of Theorem 1, suppose there exists a positive constant such that the third moments are bounded by , , and for all .
Under this assumption, we show that
as it will make the first and second claims straightforward. For , the first error event is , where we used the fact that and . Since the third moments are bounded, applying Berry-Esseen theorem, we get that the probability of error is bounded by . This gives , and consequently
This proves the desired claim.
3.1. 2. Measuring on the Probit Line
- Protocol: freeze visual tower ; train heads with different task signals; report across seeds/compute.
- Definitions: line slope, family height, effective robustness (vertical lift at fixed ID).
3.2. 3. Theory: Why Lines Appear and Who Sets the Slope
3.2.1. 3.1 Setup and Notation
Let be a frozen visual representation. Consider binary one-vs-rest subproblems with labels and features . A linear head predicts by the score . Training uses a task signal–induced data distribution .
We model class-conditional features by a standard high-dimensional Gaussian location model:
where encodes the task-aligned mean direction under , and is an SNR. For evaluation, we have two test distributions with parameters and .
Define the training direction
3.2.2. 3.2 Probit-Linearity under Frozen Features
Theorem 1 (Probit linearity). Fix the frozen and the training distribution . Let be any family of heads obtained by training on under varying sample sizes, seeds, or regularization, while keeping fixed. In the high-dimensional regime (with and ), the pair of probit accuracies on two test distributions satisfies, for all ,
where the slope
the remainder is negligible in the limit.
Interpretation. All models trained with the same frozen features and the same lie (up to vanishing error) on a common line in the probit plane. The line’s slope depends only on geometric alignment between the training direction and each test direction, modulated by their SNRs, not on sample size or optimizer noise.
Sketch of proof. (i) Under the Gaussian location model, the signed margins are approximately Gaussian by high-dimensional CLT; misclassification events are tail events controlled by standardized means. (ii) Training on makes concentrate around the task direction up to a random scale and small orthogonal noise, so . (iii) Probit accuracy is asymptotically proportional to with a common -dependent scale that cancels in the ratio across , yielding a line with slope .
Corollary 1 (Which baseline the line passes through). If a baseline head was trained on the same frozen and the same (e.g., a CLIP head aligned to web captions on that tower), then its probit point lies on the same line. Consequently, any re-trained heads on (different seeds/strength) will form a line through A. Replacing the tower changes and typically changes ’s induced , so the family becomes a distinct line that passes through the new baseline (e.g., “through B”).
Corollary 2 (Towers set line families). Changing the visual tower changes the induced feature geometry and hence the achievable for any given task signal, shifting the family height (the locus of lines you can realize). Empirically, stronger towers (e.g., SigLIP) realize higher families for both CLIP-style and VLM-style training.
3.2.3. 3.3 From Slope to VLM Robustness: Why VQA Lifts the Line
We now link the slope to task signals.
Definition (Question-guided evidence selection). A task signal (e.g., VQA) induces training reweighting or constraints that increase the alignment between and cross-domain stable evidence while reducing reliance on spurious background factors, all over the same frozen .
Proposition 2 (Task signals that improve cross-domain alignment increase slope). Let be a caption-style training distribution and be its VQA-style counterpart on the same . Suppose
Then
Hence, at matched , VQA-trained heads achieve higher —the line lifts.
Proof (one line). Directly compare the definitions of for the two training distributions; cancel in the ratio if unchanged, and the stated inequality on cosine ratios yields the strict ordering of slopes.
Operational takeaway.
- Caption signals that mirror the tower's pretraining web distribution tend to produce nearly collinear with the CLIP baseline direction, so the line passes through the baseline and has a “caption slope”.
- VQA signals impose question-conditioned constraints that select semantically relevant, stable evidence (even with a CLS head), rotating toward directions better shared by ID and OOD. This strictly increases slope and lifts the line—explaining why VLM lines sit above CLIP lines under the same frozen tower.
3.3. 4. What Sets the Family vs What Sets the Slope (Empirics)
- Towers set line families (height): CLIP vs SigLIP.
- Task signals set slopes and on-line positions: caption → baseline line; VQA → higher slope and lift; caption↔VQA mixtures interpolate the slope.
3.4. 5. From Mechanism to Method: A Robust Embedding (vlm2vec)
- Train with question-guided task signals on the frozen tower; distill to a deployable embedding.
- Observation: vlm2vec (VQA) lies on the VLM family; vlm2vec (caption) lies on the CLIP family.
3.5. 6. Negative Results (Concise)
- Prompt templates, resolution, and generative vs discriminative objectives: second-order effects on the line; do not change the family and rarely change the slope materially under frozen towers.
3.6. 7. Discussion and Future Work
- Patch tokens as an amplifier of evidence selection (left to future mechanistic analysis).
- Data efficiency and compute–robustness tradeoffs; failure modes and biases.
-
and are somtimes referred to as in-distribution (ID) and out-of-distribution (OOD). In this work, we include evaluations of zero-shot models, which are not trained on data from the reference distribution, so referring to would be imprecise. For clarity, we avoid the ID/OOD terminology.
References
-
and are somtimes referred to as in-distribution (ID) and out-of-distribution (OOD). In this work, we include evaluations of zero-shot models, which are not trained on data from the reference distribution, so referring to would be imprecise. For clarity, we avoid the ID/OOD terminology.
References
- Anil, C., Wu, Y., Andreassen, A., Lewkowycz, A., Misra, V., Ramasesh, V., Slone, A., Gur-Ari, G., Dyer, E., and Neyshabur, B. Exploring Length Generalization in Large Language Models. Advances in Neural Information Processing Systems (Neurips), 2022.
- Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., Tenenbaum, J., and Katz, B. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Advances in Neural Information Processing Systems (Neurips), 2019.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., … Amodei, D. Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems (Neurips), 2020.
- Cai, Y., Yin, F., Hammou, D., and Mantiuk, R. Do computer vision foundation models learn the low-level characteristics of the human visual system?. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Cai, Z., Lee, N., Schwarzschild, A., Oymak, S., and Papailiopoulos, D. Extrapolation by Association: Length Generalization Transfer in Transformers, 2025.
- Emporium, C. conceptual-captions-cc12m-llavanext, 2024.
- He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., and others. The many faces of robustness: A critical analysis of out-of-distribution generalization. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., and Song, D. Natural adversarial examples. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- Hu, J. E., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., and Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. International Conference on Learning Representations (ICLR), 2021.
- Huh, M., Cheung, B., Wang, T., and Isola, P. The Platonic Representation Hypothesis. International Conference on Machine Learning (ICML), 2024.
- OpenAI, Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., Avila, R., Babuschkin, I., Balaji, S., Balcom, V., Baltescu, P., Bao, H., Bavarian, M., Belgum, J., … Zoph, B. GPT-4 Technical Report, 2024.
- Jiang, Z., Meng, R., Yang, X., Yavuz, S., Zhou, Y., and Chen, W. VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks. International Conference on Learning Representations (ICLR), 2024.
- Kisel, N., Volkov, I., Hanzelková, K., Janouskova, K., and Matas, J. Flaws of ImageNet, Computer Vision's Favorite Dataset. ICLR Blogposts, 2025.
- Lee, K.-i., Kim, M., Yoon, S., Kim, M., Lee, D., Koh, H., and Jung, K. VLind-Bench: Measuring Language Priors in Large Vision-Language Models. Proceedings of the Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL), 2025.
- Leng, S., Zhang, H., Chen, G., Li, X., Lu, S., Miao, C., and Bing, L. Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
- Li, S., Koh, P. W., and Du, S. S. Exploring how generative mllms perceive more than clip with the same vision encoder. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024.
- Li, M., Zhong, J., Zhao, S., Lai, Y., Zhang, H., Zhu, W. B., and Zhang, K. Think or Not Think: A Study of Explicit Thinking in Rule-Based Visual Reinforcement Fine-Tuning, 2025.
- Liu, H., Li, C., Li, Y., and Lee, Y. J. Improved Baselines with Visual Instruction Tuning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual Instruction Tuning. Advances in Neural Information Processing Systems (Neurips), 2023.
- Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., and Lee, Y. J. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge, 2024.
- Liu, H., Xiao, L., Liu, J., Li, X., Feng, Z., Yang, S., and Wang, J. Revisiting MLLMs: An In-Depth Analysis of Image Classification Abilities, 2024.
- Liu, Z., Sun, Z., Zang, Y., Dong, X., Cao, Y., Duan, H., Lin, D., and Wang, J. Visual-RFT: Visual Reinforcement Fine-Tuning. IEEE/CVF International Conference on Computer Vision (ICCV), 2025.
- Meng, R., Jiang, Z., Liu, Y., Su, M., Yang, X., Fu, Y., Qin, C., Chen, Z., Xu, R., Xiong, C., Zhou, Y., Chen, W., and Yavuz, S. VLM2Vec-V2: Advancing Multimodal Embedding for Videos, Images, and Visual Documents, 2025.
- Miller, J. P., Taori, R., Raghunathan, A., Sagawa, S., Koh, P. W., Shankar, V., Liang, P., Carmon, Y., and Schmidt, L. Accuracy on the Line: on the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization. International Conference on Machine Learning (ICML), 2021.
- Mukhoti, J., Lin, T.-Y., Poursaeed, O., Wang, R., Shah, A., Torr, P. H., and Lim, S.-N. Open vocabulary semantic segmentation with patch aligned contrastive learning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Nguyen, T., Ilharco, G., Wortsman, M., Oh, S., and Schmidt, L. Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP. Advances in Neural Information Processing Systems (Neurips), 2022.
- Northcutt, C. G., Athalye, A., and Mueller, J. W. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. Neural Information Processing Systems: Datasets and Benchmarks Track, 2021.
- Oh, C., Fang, Z., Im, S., Du, X., and Li, Y. Understanding Multimodal LLMs Under Distribution Shifts: An Information-Theoretic Approach. International Conference on Machine Learning (ICML), 2025.
- Oh, C., Li, J., Im, S., and Li, Y. Visual Instruction Bottleneck Tuning, 2025.
- Oord, A. van den, Li, Y., and Vinyals, O. Representation Learning with Contrastive Predictive Coding, 2019.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., and others. Language models are unsupervised multitask learners, 2019.
- Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do ImageNet Classifiers Generalize to ImageNet?. International Conference on Machine Learning (ICML), 2019.
- Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., and others. Imagenet large scale visual recognition challenge. International Journal of Computer Vision (IJCV), 2015.
- Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T. L., Raja, A., Dey, M., Bari, M. S., Xu, C., Thakker, U., Sharma, S. S., Szczechla, E., Kim, T., Chhablani, G., Nayak, N., … Rush, A. M. Multitask Prompted Training Enables Zero-Shot Task Generalization. International Conference on Learning Representations (ICLR), 2022.
- Shankar, V., Roelofs, R., Mania, H., Fang, A., Recht, B., and Schmidt, L. Evaluating Machine Accuracy on ImageNet. International Conference on Machine Learning (ICML), 2020.
- Taori, R., Dave, A., Shankar, V., Carlini, N., Recht, B., and Schmidt, L. Measuring Robustness to Natural Distribution Shifts in Image Classification. Advances in Neural Information Processing Systems (Neurips), 2020.
- Vasudevan, V., Caine, B., Lopes, R. G., Fridovich-Keil, S., and Roelofs, R. When does dough become a bagel? Analyzing the remaining mistakes on ImageNet. Advances in Neural Information Processing Systems (Neurips), 2022.
- Vo, A., Nguyen, K.-N., Taesiri, M. R., Dang, V. T., Nguyen, A. T., and Kim, D. Vision Language Models are Biased, 2025.
- Wang, H., Ge, S., Lipton, Z., and Xing, E. P. Learning robust global representations by penalizing local predictive power. Advances in Neural Information Processing Systems (Neurips), 2019.
- Wang, Q., Lin, Y., Chen, Y., Schmidt, L., Han, B., and Zhang, T. A sober look at the robustness of clips to spurious features. Advances in Neural Information Processing Systems (Neurips), 2024.
- Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., and Fedus, W. Emergent Abilities of Large Language Models. Transactions on Machine Learning Research (TMLR), 2022.
- Wortsman, M., Ilharco, G., Kim, J. W., Li, M., Kornblith, S., Roelofs, R., Lopes, R. G., Hajishirzi, H., Farhadi, A., Namkoong, H., and Schmidt, L. Robust fine-tuning of zero-shot models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Wu, Z., Niu, Y., Gao, H., Lin, M., Zhang, Z., Zhang, Z., Shi, Q., Wang, Y., Fu, S., Xu, J., Ao, J., Dai, E., Feng, L., Zhang, X., and Wang, S. LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models, 2025.
- Yamamoto, T., Akahoshi, H., and Kitazawa, S. Emergence of human-like attention and distinct head clusters in self-supervised vision transformers: A comparative eye-tracking study, 2025.
- Yang, H., Lu, H., Lam, W., and Cai, D. Exploring Compositional Generalization of Large Language Models. Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2024.
- Yao, L., Huang, R., Hou, L., Lu, G., Niu, M., Xu, H., Liang, X., Li, Z., Jiang, X., and Xu, C. FILIP: Fine-grained Interactive Language-Image Pre-Training. International Conference on Learning Representations (ICLR), 2022.
- Zhai, Y., Tong, S., Li, X., Cai, M., Qu, Q., Lee, Y. J., and Ma, Y. Investigating the Catastrophic Forgetting in Multimodal Large Language Models. Conference on Parsimony and Learning (CPAL), 2023.
- Zhang, K., Luan, Y., Hu, H., Lee, K., Qiao, S., Chen, W., Su, Y., and Chang, M.-W. MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions. International Conference on Machine Learning (ICML), 2024.
- Zhang, X., Li, J., Chu, W., hai, j., Xu, R., Yang, Y., Guan, S., Xu, J., Jing, L., and Cui, P. On the Out-Of-Distribution Generalization of Large Multimodal Models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- Zhao, H., Kaur, S., Yu, D., Goyal, A., and Arora, S. Can Models Learn Skill Composition from Examples?. Advances in Neural Information Processing Systems (Neurips), 2024.
A Appendix
A.1 ImageNetv2
ImageNetV2 is an independent test set designed to evaluate the generalization of models trained on ImageNet (recht2019do). It was created by closely replicating the original ImageNet data collection and annotation pipeline to ensure a similar data distribution while remaining completely separate from the original validation and test sets. This provides a robust "out-of-sample" evaluation of a model's true performance.
The construction protocol involved several key steps:
-
Data Sourcing: Candidate images were sourced from Flickr, filtered to match the timeframe of the original ImageNet collection to control for changes in camera technology and photography styles.
-
Class-wise Retrieval: The team used keywords and class definitions from the original ImageNet documentation to query images for each of the 1,000 classes, aiming to replicate the intra-class diversity of the original dataset.
-
Crowdsourced Annotation: Using Amazon Mechanical Turk (MTurk), annotators were presented with an interface and instructions that mimicked the original labeling process. Each image was evaluated by multiple annotators to determine if it belonged to the target class.
-
Quality Control & Sampling: High data quality was maintained by monitoring annotator agreement and manually reviewing ambiguous cases. From the pool of validated images, three distinct test sets were sampled to analyze the effect of annotation artifacts: MatchedFrequency, Threshold-0.7, and TopImages. Each test set contains 10,000 images, preserving the original class balance. For our experiments, we use the MatchedFrequency version unless otherwise specified.
A.2 Probit Scaling
For our scatter plots comparing model accuracies, we follow standard practice and apply probit scaling to the axes (miller2021accuracy) (wortsman2022robust). The probit function is the inverse of the standard normal cumulative distribution function (CDF), where is the original accuracy and is the transformed value.
This transformation is crucial for analyzing accuracy scores, which are bounded between 0 and 1. On a linear scale, the variance of accuracy scores is compressed near the boundaries (e.g., the difference between 98% and 99% appears small). Probit scaling maps the [0, 1] interval to the entire real line, effectively "stretching" the scale at the extremes. This allows for a more meaningful visualization of performance differences between high-performing models and makes linear relationships in performance more apparent across the full range of accuracies.
A.3 Dataset Statistics
To determine a sufficient sample size for stable evaluation, we analyzed model performance on randomly sampled subsets of our benchmark of varying sizes. The results, presented in Table 1, show the accuracy of two representative models, SmolVLM and SmolVLM2, as a function of the number of questions in the ImageNet validation set.
| Num | 500 | 1000 | 2000 | 5000 | 8000 | 10000 | 20000 | 30000 |
| SmolVLM | 85.2% | 85.8% | 86.45% | 86.72% | 87.19% | 86.65% | 86.92% | 86.91% |
| SmolVLM2 | 93.6% | 94.6% | 94.75% | 93.7% | 93.86% | 94.11% | 94.05% | 94.17% |
The data indicates that accuracy scores converge as the sample size increases. Beyond 2,000 samples, the reported accuracy for both models varies by less than 0.5 percentage points. Therefore, our primary test set size is well above the threshold required to produce stable and conclusive results.
A.4 Change Prompt
- Prompt 1: A photo of a {class}
- Prompt 2: {class}
- Prompt 3: What type of object is in this photo?
- Prompt 4: Select the most appropriate label for the object shown in the image.
- Prompt 5: Identify the object in this image.