Vision foundation model Aligned Variational AutoEncode
1. Vision foundation model Aligned Variational AutoEncode (VA-VAE)
As visual tokenizers become more sophisticated with higher-dimensional latent spaces to improve reconstruction quality, they paradoxically become harder for diffusion models to work with, leading to poor generation performance.
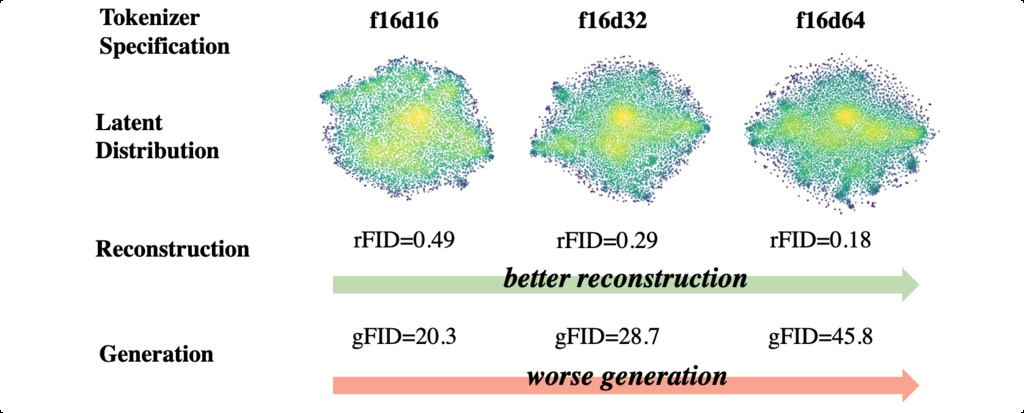
To resolve this dilemma, the research introduces a Vision Foundation Model Aligned Variational AutoEncoder (VA-VAE) that uses a novel Vision Foundation Model Alignment Loss (VF Loss). This approach leverages the structured, semantically meaningful representations learned by pre-trained vision foundation models to guide the tokenizer's latent space toward being more "generation-friendly."
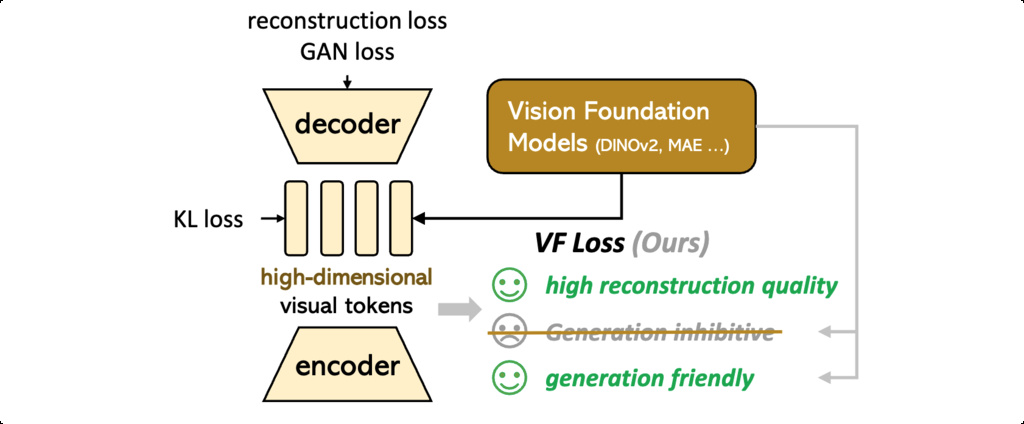
Relationship to REPA: REPA aims to employ vision foundation models to constrain DiT, thereby enhancing the convergence speed of generative models. In contrast, our work takes into account both the reconstruction and generative capabilities within the latent diffusion model, with the objective of leveraging foundation models to regulate the highdimensional latent space of the tokenizer, thereby resolving the optimization conflict between the tokenizer and the generative model.
1.1. Align VAE with Vision Foundation Models
Vision Foundation model alignment loss (VF loss) consists of two components: marginal cosine similarity loss and marginal distance matrix similarity loss.
1.1.1. Marginal Cosine Similarity Loss
We project the image latents to match the dimensionality of foundational visual representations using a linear transformation , producing .
The Marginal Cosine Similarity Loss enforces element-wise alignment between the VAE's latent features and foundation model features, focusing alignment on less similar pairs:
1.1.2. Marginal Distance Matrix Similarity Loss
Complementary to , which enforces point-to-point absolute alignment, we also aim for the relative distribution distance matrices within the features to be as similar as possible. The Marginal Distance Matrix Similarity Loss aligns the internal structure and relationships within the latent space:
Here, represents the total number of elements in each flattened feature map.
1.1.3. Adaptive Weighting
The adaptive weighting function is defined as to ensure and have similar impacts on model optimization.