Understanding Multimodal LLMs Under Distribution Shifts
1. Understanding Multimodal LLMs Under Distribution Shifts

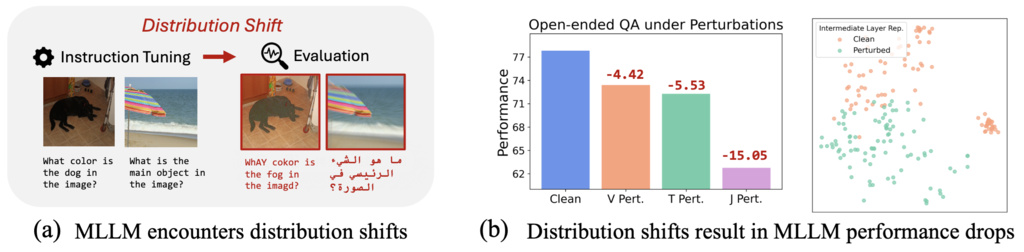
Despite the strong capabilities of MLLMs, their reliability in unfamiliar scenarios can be problematic.
- The authors introduce a theoretical framework from an information-theoretic perspective, proposing a new metric called Effective Mutual Information (EMI) to measure how well MLLMs maintain the relevance between user queries and model responses under distribution shifts.
- They derive mathematical upper bounds that can predict the performance gap of MLLMs when moving from familiar (in-distribution) to unfamiliar (out-of-distribution) data.
- Experiments involving 61 types of distribution shifts (visual, textual, and joint) demonstrate that EMI strongly correlates with common empirical metrics (like win rate) for evaluating model responses.
- The results show that as the severity of data shift increases, model performance drops, and their theoretical framework can accurately quantify and predict this degradation.
2. On the Out-Of-Distribution Generalization of Multimodal Large Language Models
While MLLMs excel on common object recognition tasks, they exhibit dramatic performance degradation on domain-specific data, particularly in medical and molecular imagery. Direct application of MLLMs to specific domains without further adaptation or fine-tuning is likely to be insufficiently accurate and reliable.
Three plausible hypotheses for this performance degradation are:
- Semantic misinterpretation: MLLMs may struggle to grasp the nuanced meaning and implications of specific scientific categories within prompts, harming their understanding of the task.
- Visual feature extraction insufficiency: The inherent characteristics of medical and molecular data, like high dimensionality or intricate image features, might challenge the model's internal encoding and processing mechanisms, hindering accurate visual information extraction.
- Mapping deficiency: Restricted training data in specialized domains hinders the development of robust mappings between semantic meanings and visual features in MLLMs.
We use synthetically generated images, naturally occurring distribution shifts, and domain-specific imagery like medical and molecular datasets.
- MLLMs achieve outstanding performance on most of the well-used datasets for domain generalization or OOD generalization, such as PACS, VLCS, OfficeHome, DomainNet, and NICO++.
- While MLLMs excel at zero-shot generalization on OOD datasets of synthetic and natural images, their performance plummets when transitioning to medical and molecular data. Specifically, all MLLMs make near-random predictions on all medical and molecular datasets including Camelyon17, CT-XCOV, XCOVFour, HAM10000, NIH-Chest, DrugOOD_Assay, DrugOOD_Scaffold, DrugOOD_Size, and DrugOOD_Protein. This significant drop in performance suggests the crucial fact that MLLMs struggle with zero-shot generalization beyond domains closely resembling their training data.
Our analysis identifies that mapping deficiency can be the primary hindrance to model generalization.
These findings demonstrate that when ICE closely mirror the distribution of test data, MLLMs can achieve substantial performance gains on many new tasks, where the degree of improvement scales with the number of examples provided. This further suggests that the primary obstacle to generalization in these tasks likely stems from deficiencies in task-specific knowledge mapping within the MLLMs.
3. Visual Instruction Bottleneck Tuning
To enhance generalization, existing efforts typically fall into two categories:
- data-centric approaches, which collect more instruction data and processes input in a finer granularity, and
- model-centric approaches, which scale up the underlying model using more expressive or specialized backbones. However, both data scaling and model scaling are resource-intensive—requiring significant annotation or computational cost.
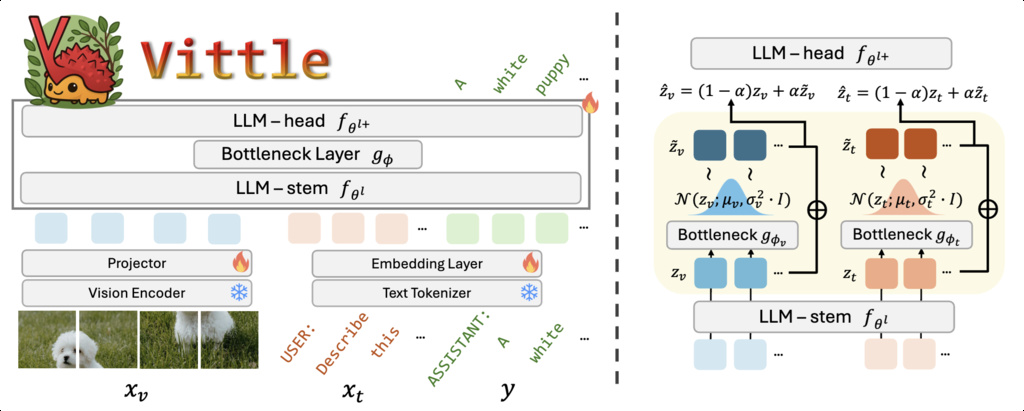
In this work, we propose a new approach from a representation-centric view to improve the robustness of MLLMs under distribution shifts. Rather than scaling data or model, we introduce a lightweight, theoretically grounded module that enhances the internal representations of MLLMs via the information bottleneck (IB) principle.
Let be a multimodal input query, the desired output, and an intermediate representation extracted by the MLLM encoder . The Information Bottleneck principle aims to learn representations that are maximally informative about the output while being minimally informative about the input . Formally, this is expressed as the optimization objective:
where denotes mutual information and is the trade-off coefficient.
In other words, the IB objective promotes representations that discard non-essential features tied to the input modality, while preserving those critical for solving the task. This property is particularly desirable for robust instruction tuning, where diverse multimodal inputs must be mapped to consistent, meaningful outputs under varied conditions (e.g., visual and textual perturbations). Despite its appeal, integrating the IB objective into MLLM training is highly non-trivial due to the intractability of mutual information estimation and the complexity of autoregressive and multimodal architectures.
References
- On the Out-Of-Distribution Generalization of Multimodal Large Language Models
- Understanding Multimodal LLMs Under Distribution Shifts: An Information-Theoretic Approach
- Visual Instruction Bottleneck Tuning
- COUNTS: Benchmarking Object Detectors and Multimodal Large Language Models under Distribution Shifts