Could VQ-VAE Beat VAE?
1. MGVQ
- Existing VQ-VAEs suffer from significant information loss due to aggressive reduction of latent dimensions, leading to degraded reconstruction quality.
- The representation capacity of conventional VQ-VAEs is limited by the finite size of a single codebook, hindering their ability to capture fine-grained details.
- Traditional VQ-VAE training often encounters "codebook collapse" where many code vectors remain unused, effectively reducing the model's actual capacity.
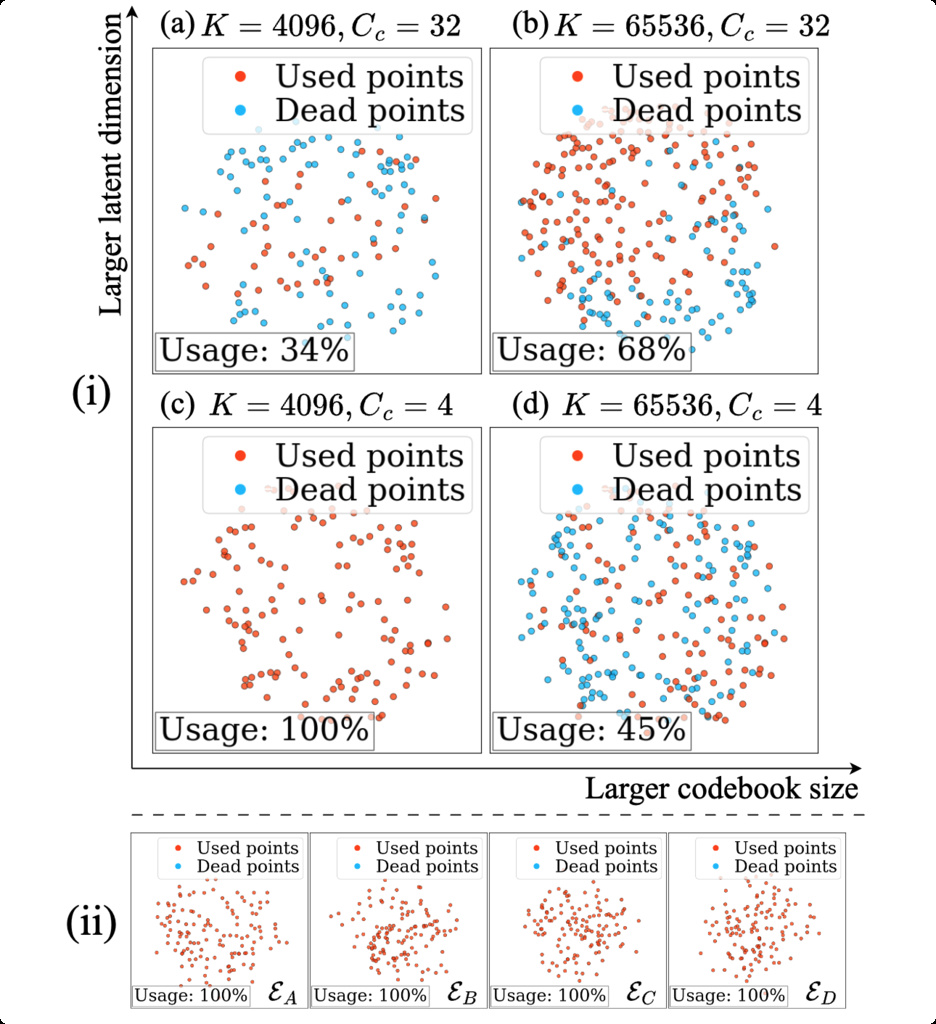
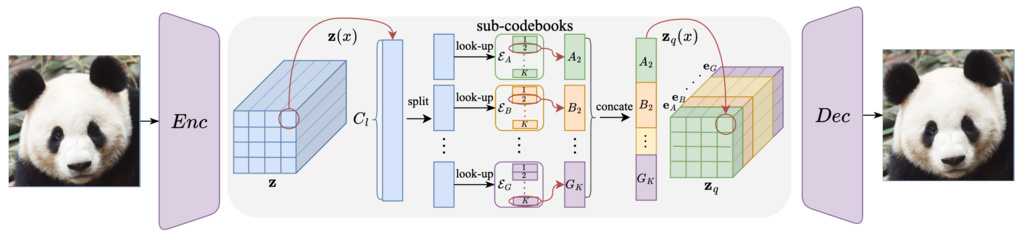
To enhance the VQ-VAE performance, our insight is that the key point is increasing the representation capacity instead of the codebook size. Therefore, we attempt to enlarge the representation capacity but maintain a small codebook size for easy optimization.
2. SEMANTICIST
Most existing visual tokenizers face a fundamental limitation: they lack explicit structural constraints in their latent spaces, leading to inefficient representation and difficulties in interpretation.
While modern approaches such as (vector quantized) variational autoencoders share similar goals as earlier methods—compressing images into a compact, lowdimensional space while minimizing reconstruction errors—they have largely abandoned the inherent structural properties, such as orthogonality and orderliness, that were critical to the success of earlier PCA-based techniques. For instance, mainstream methods employ a 2D latent space, where image patches are encoded into latent vectors arranged in a 2D grid. While this approach achieves high reconstruction quality, it introduces redundancies that scale poorly as image resolution increases. More recently, 1D tokenizers have been proposed to find a more compact set of latent codes for image representation. Although these methods more closely resemble earlier approaches, they lack structural constraints on latent vectors, making optimization challenging and often resulting in high reconstruction errors.
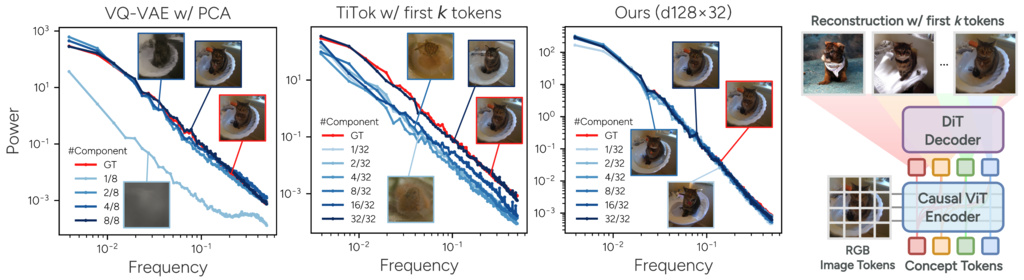
We further investigate the latent space of state-of-theart methods, including VQ-VAE and TiTok, and find that the lack of a structured latent space leads to an inherent tendency for their learned representations to couple significant semantic-level content with less significant lowlevel spectral information—a phenomenon we refer to as semantic-spectrum coupling.
The above motivates us to ask: Can insights from classic PCA techniques be integrated with modern 1D tokenizers to achieve a compact, structured representation of images— one that reduces redundancy while effectively decoupling semantic information from less important low-level details?
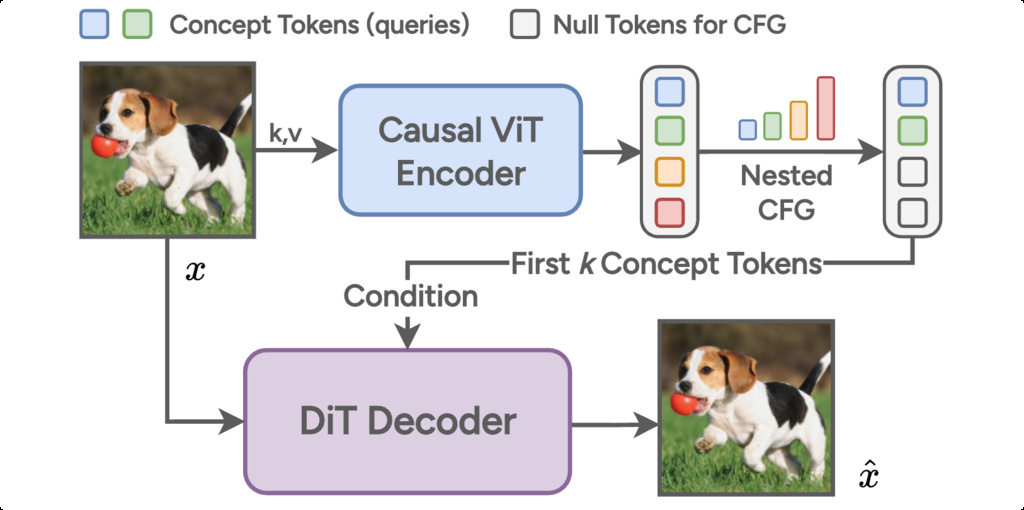
2.1. SEMANTICIST Architecture
The encoder E takes the below concatenate token sequence for processing: .
The SEMANTICIST architecture consists of two primary components:
Causal Vision Transformer Encoder: Transforms input images into a sequence of tokens with an implicit ordering constraint.
Diffusion-based Image Decoder: Reconstructs the original image from the tokenized representation.
Nested Classifier-Free Guidance (nested CFG) is a novel technique designed to endow visual token sequences with a clear hierarchical, principal component-like structure. During training, a random cutoff point in the token sequence is selected, and all tokens after this point are replaced with a learnable "null token." This mechanism compels the model to encode the most critical and informative content in the earliest tokens, while later tokens successively add finer details. Over many training iterations, this process yields token sequences where the leading tokens capture the largest share of variance, similar to principal components in PCA, and trailing tokens provide diminishing, complementary information. In summary, nested CFG transforms continuous token representations into a "coarse-to-fine" hierarchy that is highly interpretable, flexible, and efficient for both reconstruction and generation tasks.