Single-pass Adaptive Image Tokenization for Minimum Program Search
1. KARL (Kolmogorov-Approximating Representation Learning)
Traditional computer vision models rely on fixed-length representations for all images, regardless of their inherent complexity. This approach contradicts fundamental principles from Algorithmic Information Theory (AIT), which suggests that intelligent systems should compress data into their shortest possible programs. Simple images with repetitive patterns should require fewer tokens than complex scenes with intricate details, yet most current methods allocate identical computational resources to both.
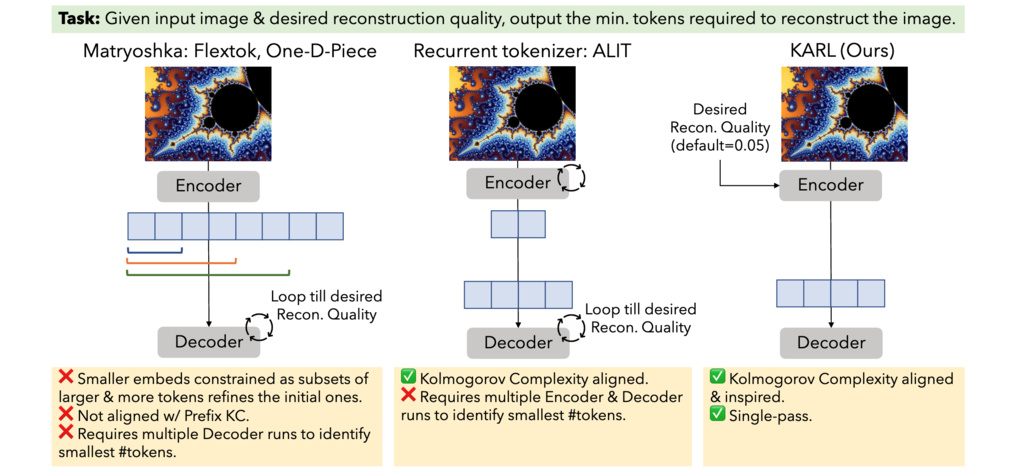
The system uses a Perceiver-inspired architecture with three main components:
- Latent Distillation Encoder: Processes 2D image tokens alongside learnable 1D latent tokens, producing both token embeddings and halting probabilities
- Adaptive Masking: Uses learned halting probabilities to determine which tokens are essential for reconstruction
- Cross-Attention Decoder: Reconstructs images using only active (non-halted) tokens
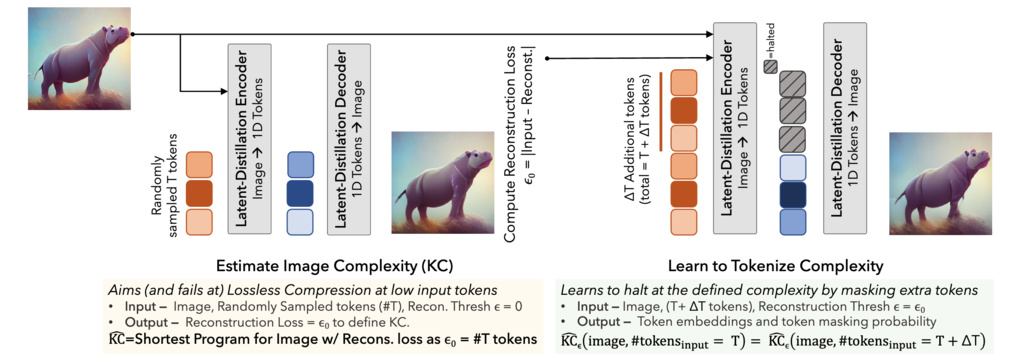
The training process alternates between two phases within each iteration:
Phase 1: Estimate Image Complexity (EIC)
- Input: Image and random token budget
- Target: Near-lossless reconstruction ()
- Output: Empirical reconstruction error
The loss function for this phase is:
Phase 2: Learn to Tokenize Complexity (LTC)
- Input: Same image , expanded token budget , and target quality
- Target: Match the reconstruction quality using only tokens
- Output: Token embeddings and halting probabilities
The total loss includes reconstruction, quantization, and halting components:
The halting loss encourages the model to preserve the first tokens while discarding the additional tokens:

