Flowing Seamlessly Across Text and Image Tokens
1. FlowTok: Flowing Seamlessly Across Text and Image Tokens
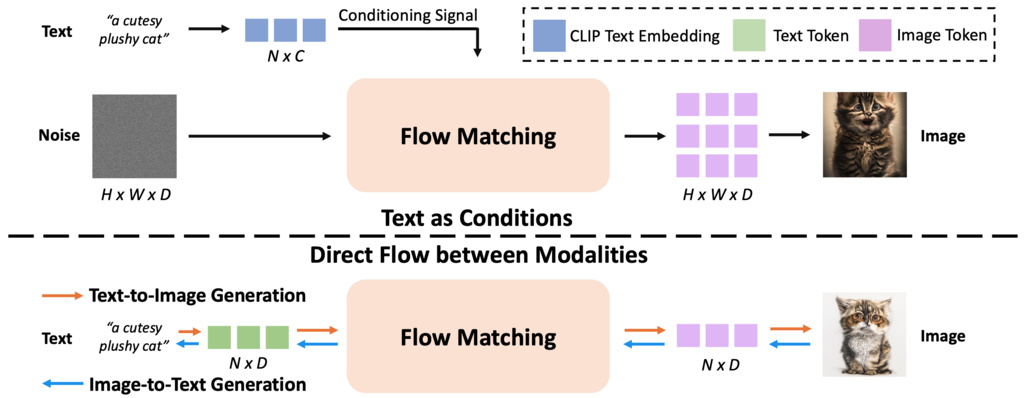
FlowTok presents a revolutionary approach to cross-modal generation by enabling direct flow matching between text and image modalities. Unlike conventional methods that treat text as a conditioning signal for image generation, FlowTok projects both modalities into a unified, compact 1D latent space.
1.1. Direct Flow Between Modalities
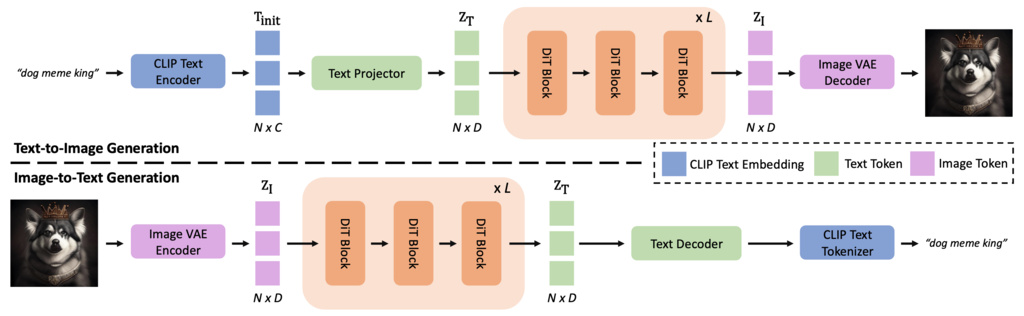
1.1.1. Unified Latent Space Design
FlowTok encodes both text and images into compact 1D tokens with shape :
Text Processing:
- CLIP text encoder extracts initial embeddings
- Text projector maps to latent space:
- Gaussian distribution modeling with KL regularization
Image Processing:
- Enhanced TA-TiTok with RoPE and SwiGLU FFN
- Direct encoding to where
- Maintains semantic information in compact representation
1.1.2. Flow Matching Framework
The flow matching objective learns direct transformation:
where the velocity field is:
Unlike standard flow matching that uses noise as source distribution, FlowTok treats text tokens and image tokens as both source and target distributions.
1.1.3. Semantic Preservation
To prevent information loss during dimensionality reduction, FlowTok introduces text alignment loss:
where:
1.1.4. Training Objective
Complete loss function:
where:
- : Flow matching loss
- : KL divergence regularization
- : Text alignment preservation