Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
1. REPresentation Alignment (REPA)
The main challenge in training diffusion models stems from the need to learn a high-quality internal representation h. We demonstrate that the training process for generative diffusion models becomes significantly easier and more effective when supported by an external representation, . Specifically, we propose a simple regularization technique that leverages recent advances in self-supervised visual representations as , leading to substantial improvements in both training efficiency and the generation quality of diffusion transformers.
These insights inspire us to enhance generative models by incorporating external self-supervised representations. However, the problems are
- Input mismatch: diffusion models work with noisy inputs while most self-supervised learning encoders are trained on clean images
- These off-the-shelf vision encoders are not designed for tasks like reconstruction or generation
To overcome these technical hurdles, we guide the feature learning of diffusion models using a regularization technique called REPresentation Alignment (REPA) that distills pretrained self-supervised representations into diffusion representations, offering a flexible way to integrate high-quality representations.
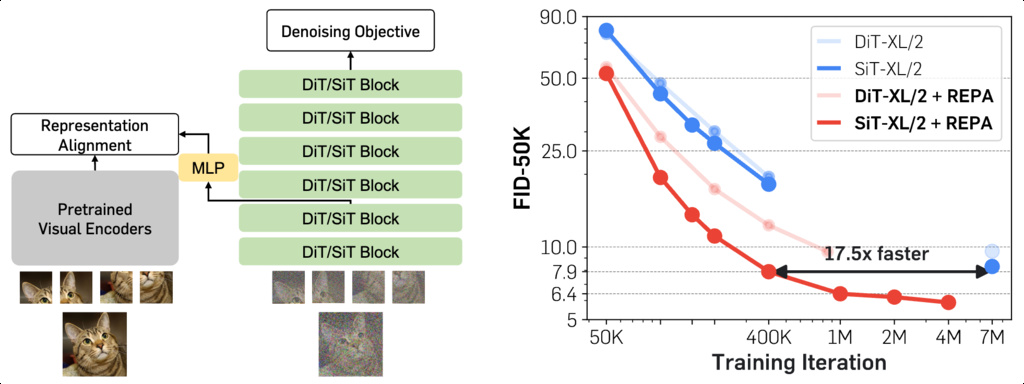
Let be a pretrained encoder, be a clean image. REPA aligns with where is a projection of an transformer encoder output that through a trainable projection head .
2. Self-Representation Alignment (SRA)
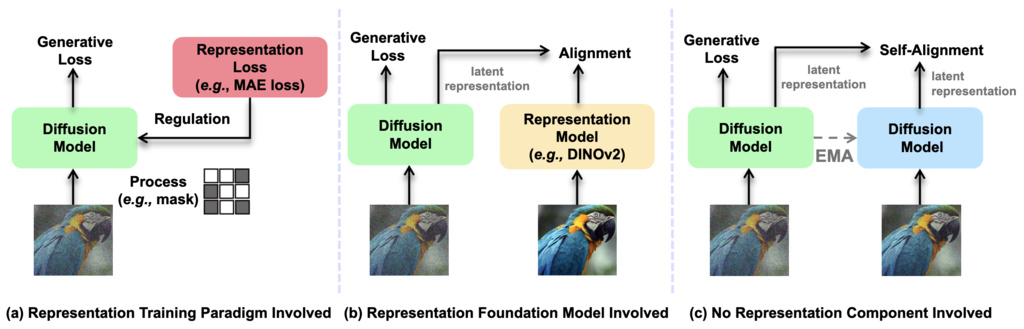
SRA attains self-alignment by minimizing the patch-wise distance between the teacher's output () and the student's output variant ():
where is a patch index, is a pre-defined distance calculation function, and , is the parameters of student diffusion transformer and the projection head. This objective is similar to that mentioned in REPA, except that we're aiming to align with DIT's own teacher instead of external transformer itself. The final loss is:
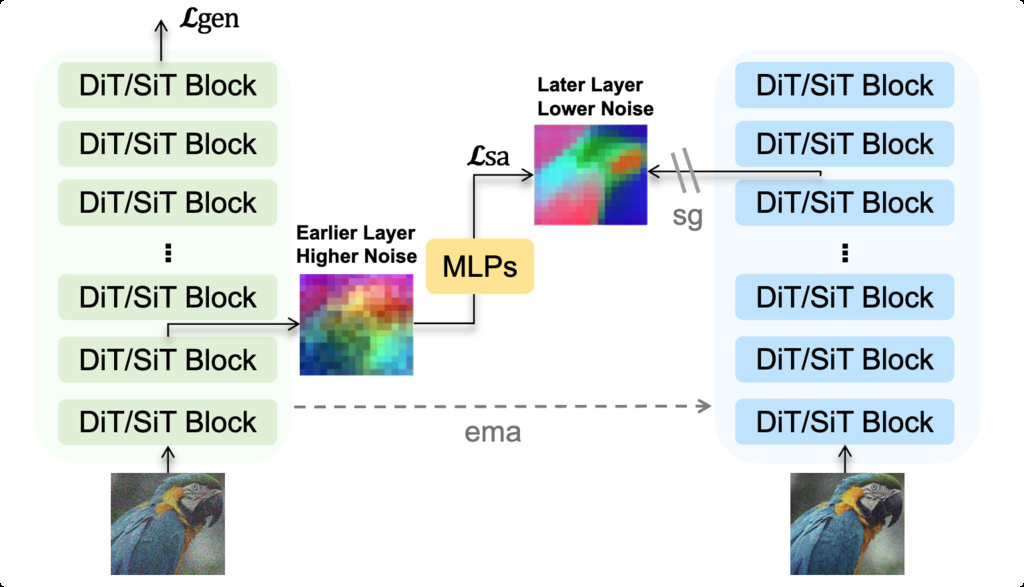
3. LayerSync
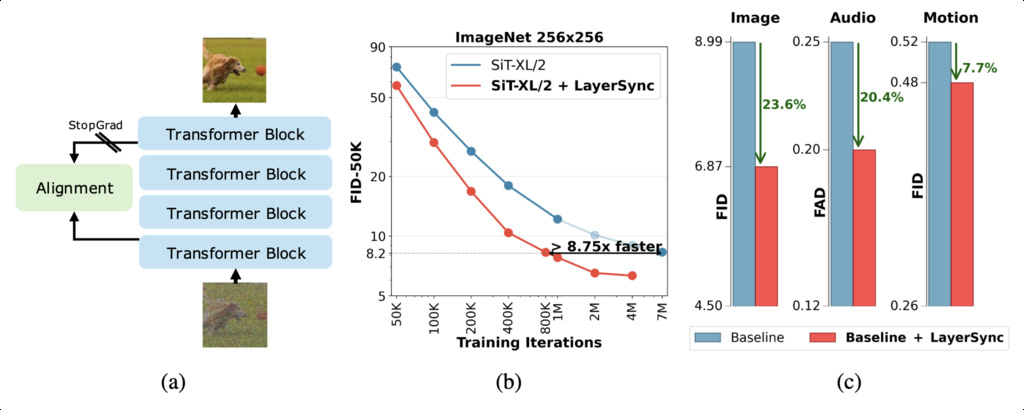
4. Velocity Refiner with Acceleration (VeRA)
Existing flow-based generative models, such as SiT, primarily utilize only the final layer's output for velocity prediction, under-utilizing rich intermediate representations. This under-utilization of internal features leads to slower model convergence and suboptimal generation performance in flow-based models.
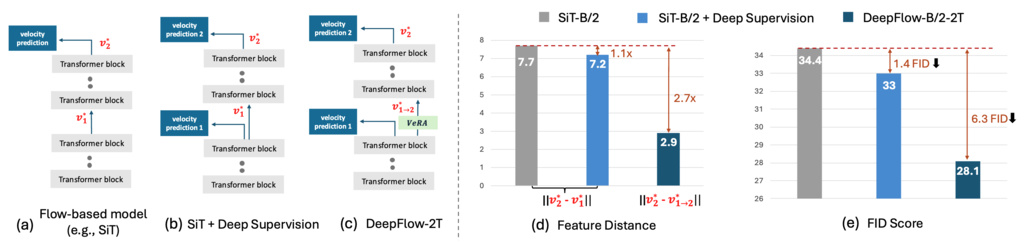
4.1. Deep Supervision
DeepFlow employs deep supervision by inserting auxiliary velocity layers after selected intermediate transformer blocks. The corresponding deep supervision loss at these key transformer layers is defined as follows:
This approach encourages intermediate layers to develop meaningful velocity representations earlier in the network, improving gradient flow and feature alignment across layers.
4.2. Velocity Refiner with Acceleration (VeRA) Block
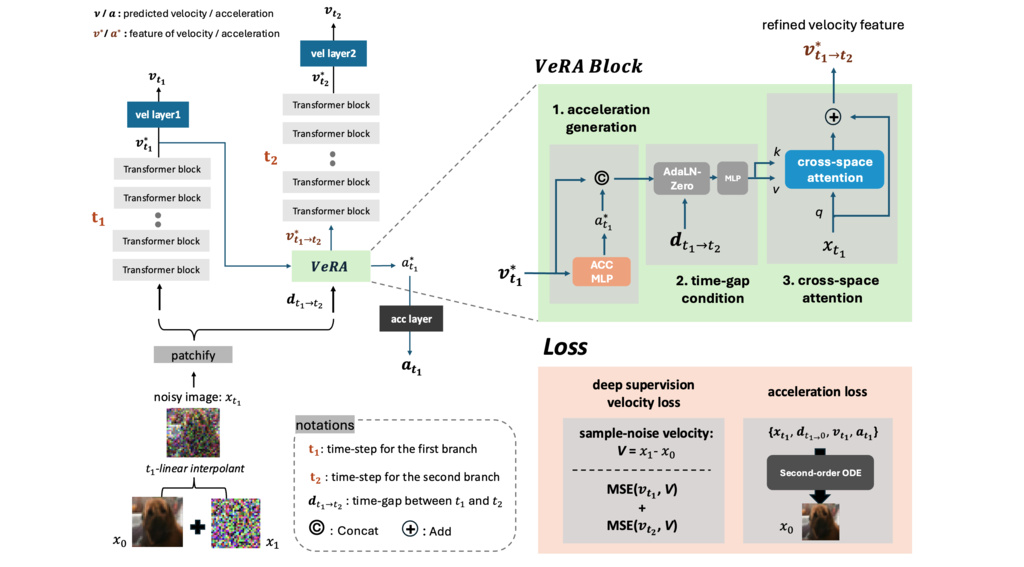
Positioned between adjacent branches, it refines velocity features from preceding layers and aligns them with subsequent processing stages. The block comprises three main components:
- Acceleration Generation and Second-Order ODE Training
The VeRA block begins by generating an "acceleration feature" from the input velocity feature using a Multi-Layer Perceptron (ACC_MLP):
Then we can endow with acceleration property using a second-order ordinary differential equation (-ODE) as following equation:
- Feature Concatenation and Time-gap Conditioning
After computing the acceleration features ( ), we concatenate these with the original velocity features ( ). To enable this concatenated feature to be aware of time-gap, we apply a time-gap-conditioned adaptive layer normalization with a following MLP as below:
- Spatial Information Integration via Cross-Attention
Beyond feature alignment with temporal property using different time-steps, the VeRA block also integrates spatial context by employing a cross-attention (CA) mechanism. This mechanism facilitates interaction between two spaces: modulated velocity feature space from previous step and spatial feature space from an original patchified image as noted in following equation.
DeepFlow incorporates deep supervision and VeRA block
5. Decoupled Diffusion Transformer (DDT)
The authors of "Decoupled Diffusion Transformer" (DDT) identify a fundamental "optimization dilemma" in existing diffusion transformers. In conventional architectures, the same neural network modules must simultaneously handle two conflicting tasks: encoding low-frequency semantic information from noisy inputs and decoding high-frequency details for reconstruction. This dual responsibility creates optimization tension because effective semantic encoding requires suppressing high-frequency noise, while detail reconstruction demands preserving and generating high-frequency components.
DDT resolves this optimization conflict through a principled decoupled encoder-decoder architecture that explicitly separates semantic extraction from detail reconstruction:
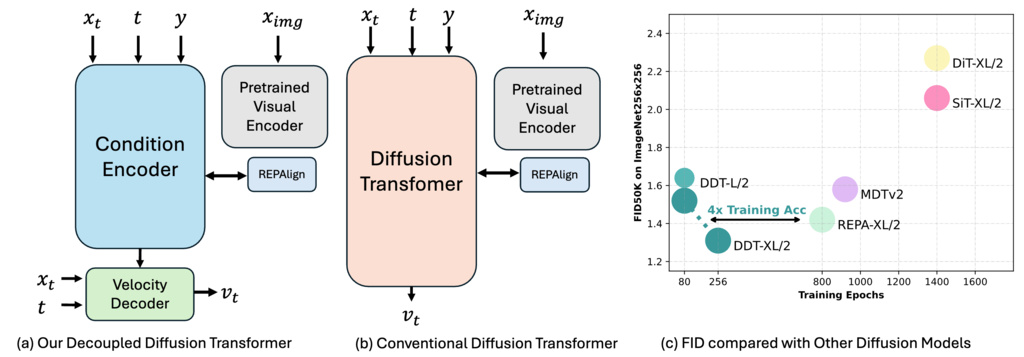
5.1. Condition Encoder
The condition encoder specializes in extracting low-frequency semantic components from three inputs: the noisy latent image , timestep , and class label . It employs interleaved attention and feed-forward blocks similar to DiT/SiT, with timestep and class conditioning via AdaLN-Zero injection.
Crucially, the encoder receives direct supervision through Representation Alignment (REPAlign), which enforces consistency between extracted features and pre-trained vision foundation model representations (DINOv2).
5.2. Velocity Decoder
The velocity decoder focuses on processing the noisy latent alongside the self-condition feature to predict the velocity field . Operating within a linear flow diffusion framework, it minimizes the flow matching loss.
5.3. Inference Acceleration Through Encoder Sharing
A key innovation of DDT is leveraging the consistency of extracted semantic features. across adjacent timesteps for inference acceleration. The authors propose two strategies:
-
Uniform Encoder Sharing: Recomputing at fixed intervals (every K steps) rather than every denoising step.
-
Statistical Dynamic Programming: A more sophisticated approach that frames optimal sharing as a minimal-cost path problem. Using a pre-computed similarity matrix of cosine distances between features across timesteps, dynamic programming finds the optimal recalculation schedule that maximizes sharing while minimizing performance degradation.
6. Representation Entanglement for Generation (REG)
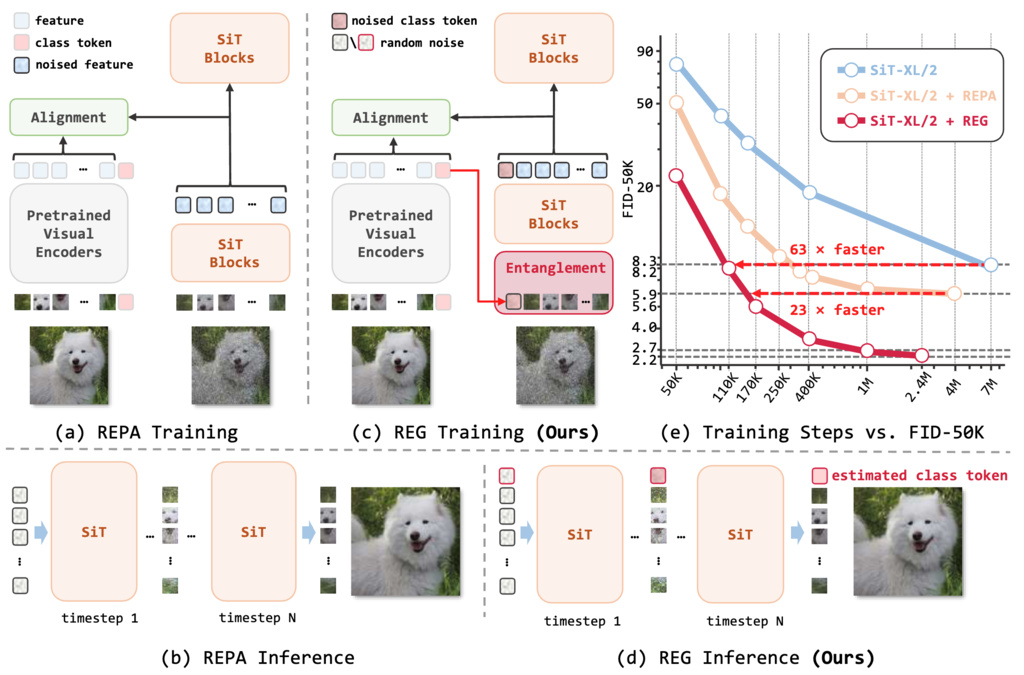
Introduce the class token from the vision foundation model to entangle with image latents for providing the discriminative guidance. .
The prediction loss is formulated as:
The total loss is formulated as:
7. ReDi
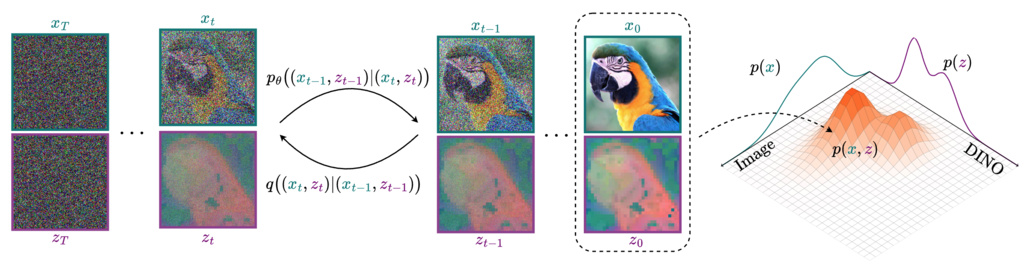
Rather than aligning diffusion features with external representations via distillation, we propose to jointly model both images (specifically their VAE latents) and their high-level semantic features extracted from a pretrained vision encoder (e.g., DINOv2) within the same diffusion process.
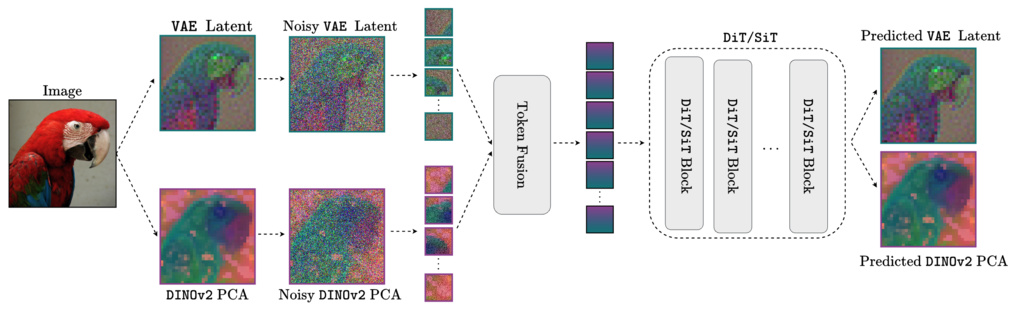
7.1. Representation Guidance
To ensure the generated images remain strongly influenced by the visual representations during inference, we introduce Representation Guidance. This technique during inference modifies the posterior distribution to: , where controls how strongly samples are pushed toward higher likelihoods of the conditional distribution . This yields the guided score function:
By recalling the equivalence of denoisers and scores, we implement this representation-guided prediction at each denoising step as follows:
8. REPA-E
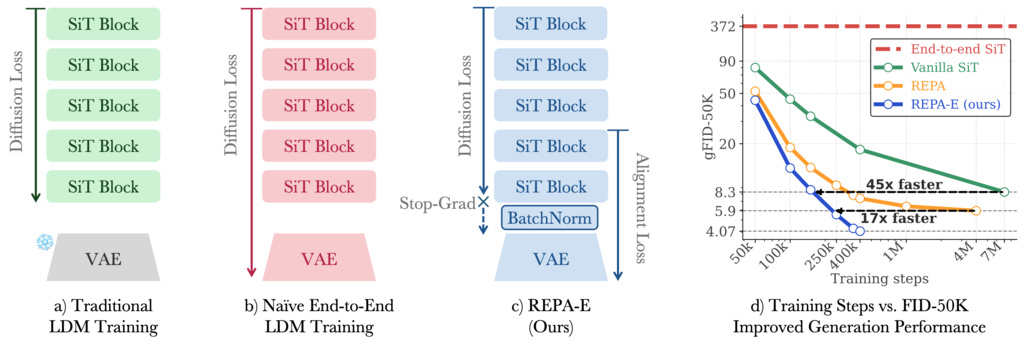
Higher representation-alignment score correlates with improved generation performance. This offers an alternate path for improving final generation performance using representation-alignment score as a proxy.
The maximum achievable alignment score with vanilla-REPA is bottlenecked by the VAE latent space features.
8.1. End-to-End Training with REPA
Batch-Norm Layer for VAE Latent Normalization. To enable end-to-end training, we first introduce a batchnorm layer between the VAE and latent diffusion model. Typical LDM training involves normalizing the VAE features using precomputed latent statistics (e.g., std for SD-VAE). This helps normalize the VAE latent outputs to zero mean and unit variance for more efficient training for the diffusion model. However, with end-to-end training the statistics need to be recomputed whenever the VAE model is updated - which is expensive. To address this, we propose the use of a batchnorm layer which uses the exponential moving average (EMA) mean and variance as a surrogate for dataset-level statistics. The batch-norm layer thus acts as a differentiable normalization operator without the need for recomputing dataset level statistics after each optimization step.
End-to-End Representation-Alignment Loss. We next enable end-to-end training, by using the REPA loss for updating the parameters for both VAE and LDM during training.
Diffusion Loss with Stop-Gradient. Backpropagating the diffusion loss to the VAE causes a degradation of latent-space structure.
VAE Regularization Losses. Finally, we introduce regularization losses for VAE , to ensure that the end-to-end training process does not impact the reconstruction performance (rFID) of the original VAE.
Overall Training. The overall training is then performed in an end-to-end manner using the following loss,
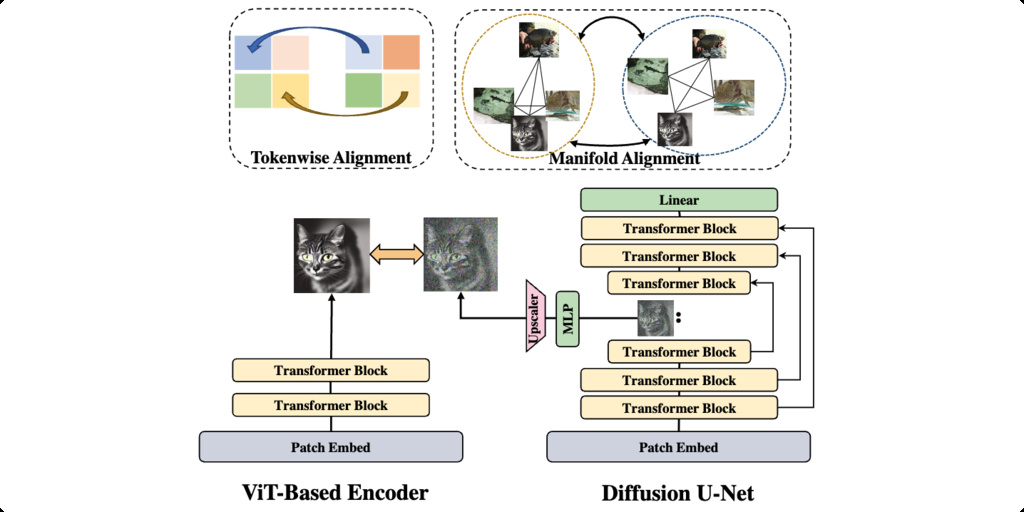
9. U-REPA
Adapting REPA to U-Net architectures.
10. SoftREPA
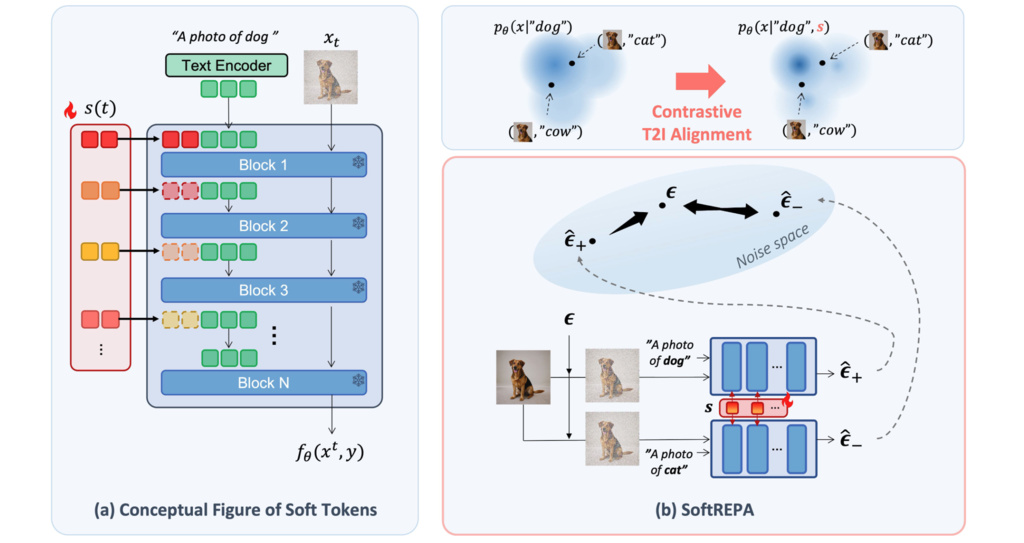
While modern text-to-image (T2I) generative models have achieved remarkable success, a persistent challenge is the occasional misalignment between the generated image and the input text prompt. This can manifest as incorrect objects, attributes, or compositions. Existing approaches to fix this often require extensive fine-tuning or specialized preference datasets, which can be computationally expensive.
10.1. The SoftREPA Method
SoftREPA enhances text-image alignment by leveraging contrastive learning with a small set of trainable parameters, known as "soft tokens," while keeping the large pre-trained model frozen.
10.1.1. Learnable Soft Tokens
Soft tokens are learnable vectors that do not correspond to any specific words in a vocabulary. During the generation process, these tokens are prepended to the original text embeddings at various layers of the model's denoiser.
Because the main model remains frozen, only these soft tokens—fewer than 1 million parameters in total—are optimized during training. They act as adaptable guides, steering the model's internal representations toward better semantic alignment with the text prompt without requiring a full model retrain.
10.1.2. Contrastive T2I Alignment Loss
SoftREPA is trained using a contrastive framework that teaches the model to distinguish between correctly paired images and text (positive pairs) and mismatched pairs (negative pairs).
The "similarity" between an image and a text is defined based on the model's denoising performance. Intuitively, if the pair is a good match, the model should accurately predict the noise vector that was added to the image. The similarity logit is formulated as an exponential of the negative denoising error:
Here, a smaller denoising error results in a higher similarity score (closer to 1). The final SoftREPA loss is a contrastive objective that maximizes the similarity of positive pairs while minimizing it for negative pairs. Given a positive pair and a set of negative texts , the loss for the learnable tokens is:
This objective function effectively pushes the model's predicted noise for a positive pair closer to the ground truth while pushing the predictions for negative pairs further away.
11. Representation Autoencoders (RAE)
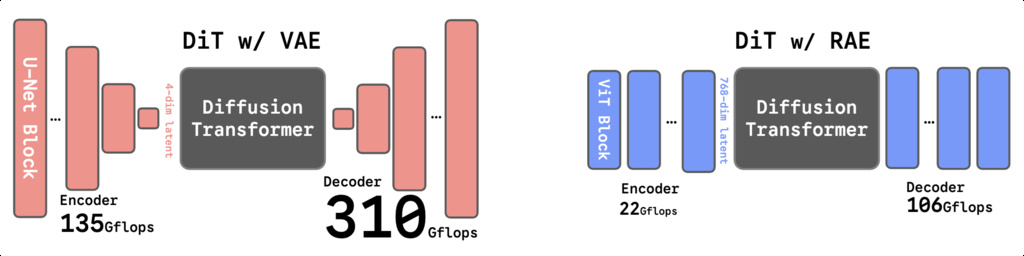
DiT have emerged as powerful models for generative tasks, regularly using a variational autoencoder (VAE) to compress input images into low-dimensional latent spaces for the diffusion process. However, most existing DiTs still depend on traditional VAE encoders that:
- Use outdated architectures
- Restrict information capacity with low-dimensional latents
- Rely on loss functions optimized only for reconstruction, limiting generative quality
11.1. High Fidelity Reconstruction From Frozen Encoders
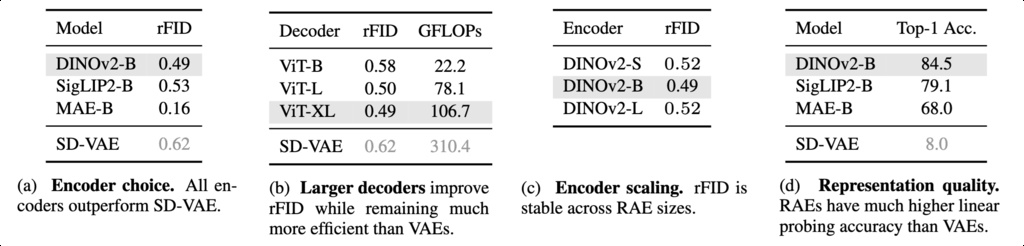
DiT does not work out of the box. To our surprise, the standard diffusion recipe fails with RAE. Training directly on RAE latents causes a small backbone such as DiT-S to completely fail, while a larger backbone like DiT-XL significantly underperforms it's counterpart with the SD-VAE latents. To investigate this observation, we raise several hypotheses detailed below, which we will discuss in the following sections:
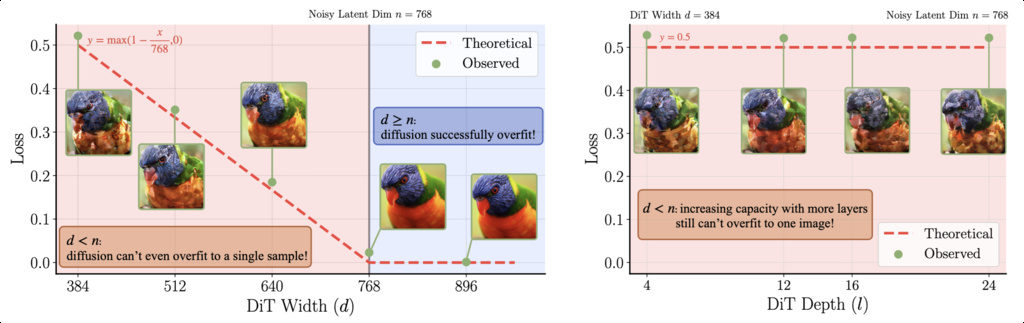
- Suboptimal design for diffusion transformers. When modeling high-dimensional RAE tokens, the optimal design choices for diffusion transformers can diverge from those of the standard DiT, which was originally tailored for low-dimensional VAE tokens
Suboptimal design for diffusion transformers. We now fix the width of DiT to be at least as large as the RAE token dimension. For RAE with the DINOv2-B encoder, we pair it with DiT-XL in our following experiments.
- Suboptimal noise scheduling. Prior noise scheduling and loss re-weighting tricks are derived for image-based or VAE-based input, and it remains unclear if they transfer well to high-dimension semantic tokens
Suboptimal noise scheduling. We now default the noise schedule to be dependent on the effective data dimension for all our following experiments.
- Diffusion generates noisy latents. VAE decoders are trained to reconstruct images from noisy latents, making them more tolerant to small noises in diffusion outputs. In contrast, RAE decoders are trained on only clean latents and may therefore struggle to generalize.
Diffusion generates noisy latents. We now adopt the noise-augmented decoding for all our following experiments.

12. Self-supervised representations for Visual Generation (SVG)
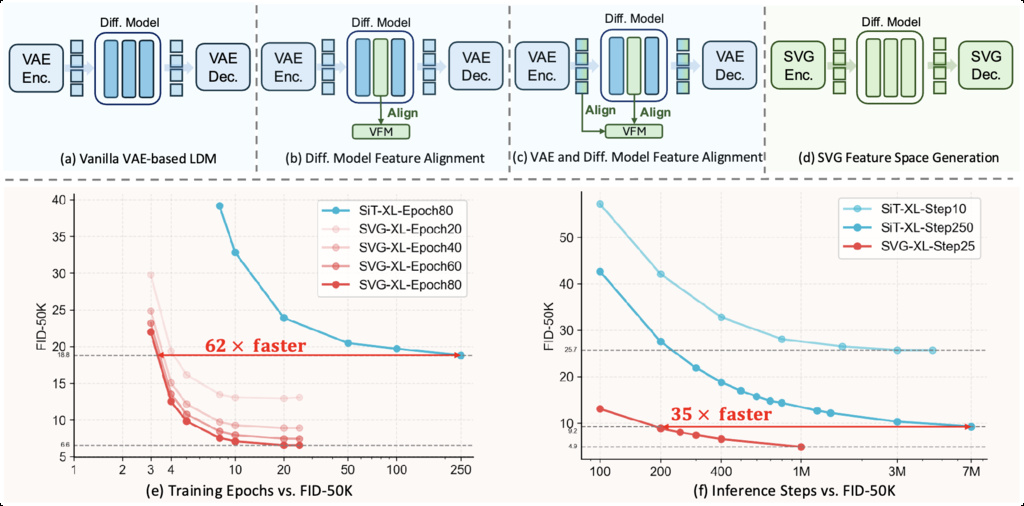
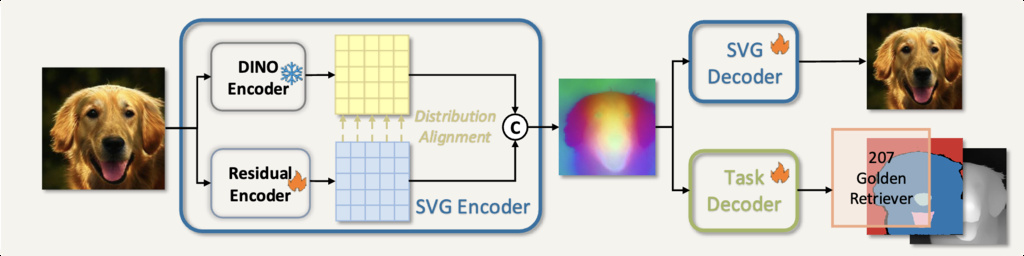
The authors introduce SVG—a latent diffusion generator without a VAE. Instead, SVG uses self-supervised DINO features, which retain strong semantic discriminability. The framework consists of a frozen DINO backbone for feature extraction and a residual branch for fine visual details. The diffusion process takes place directly in this semantic space.
13. End-to-end Pixel-space Generative model (EPG)
Most high-resolution image generative models (e.g., diffusion, consistency models) rely on VAE-based latent representations to enable efficient training and high quality. Pure pixel-space generative modeling (operating directly on raw pixels, without a latent bottleneck) is much more challenging due to higher variance and complexity, and thus usually underperforms latent-space approaches.
This paper proposes a two-stage framework to significantly improve pixel-space generative models:
-
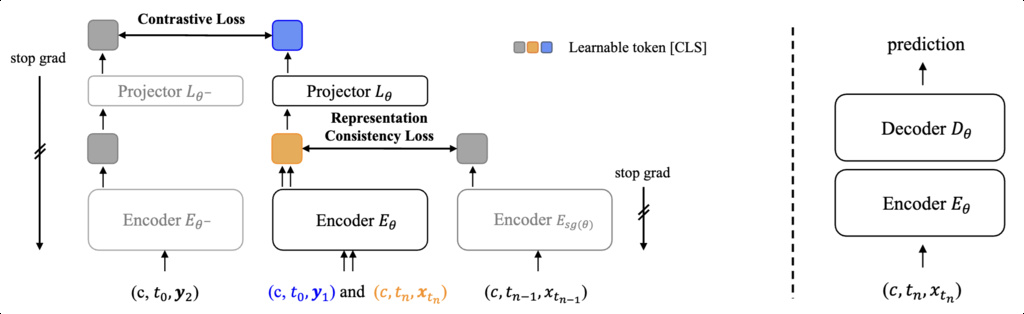
Self-supervised Pre-training:
- An encoder is trained via contrastive and representation consistency losses, ensuring that features are robust to noise and sampling trajectory. This step aligns the semantic representations between noisy inputs and their clean counterparts in pixel space.
-
End-to-End Fine-tuning:
- The projection head is removed, and the pre-trained encoder is paired with a randomly initialized decoder to jointly optimize for image generation via diffusion or consistency objectives.
- Proposed adaptive temperature scheduling stabilizes contrastive training and prevents early-stage training collapse.
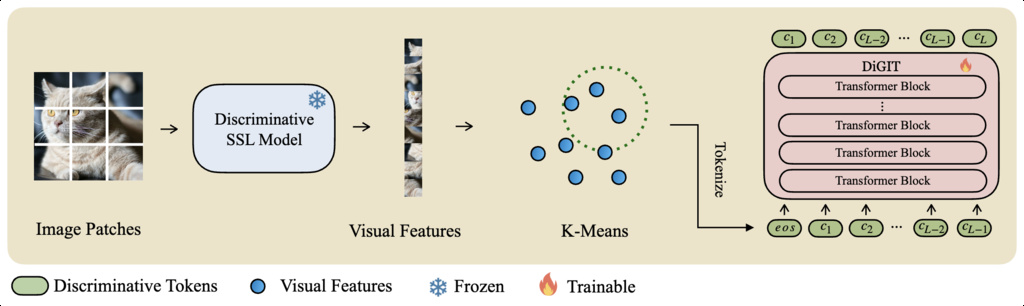
14. Discriminative Generative Image Transformer (DiGIT)
This paper introduces a new perspective on image generative modeling, highlighting that an optimal latent space for autoregressive generation should not be solely optimized for pixel reconstruction, but should also emphasize stability—meaning robustness to perturbations and resistance to error accumulation. The authors observe that autoregressive models perform worse than diffusion or iterative models (despite sharing the same latent spaces induced by standard autoencoders like VQGAN) because their generation process amplifies instability in the latent space.
To address this, the paper proposes a simple but effective method:
- The encoder and decoder are trained separately. The encoder is realized as a discriminative self-supervised model (such as DINOv2), which extracts robust, semantically meaningful features from image patches without training for reconstruction.
- These patch-level features are then discretized into tokens via K-Means clustering, forming a discrete and more stable latent codebook (tokenizer).
- An autoregressive Transformer is trained to generate these discrete tokens, following the standard causal next-token prediction setup (like GPT). The pixel decoder is trained separately to reconstruct images from the sequence of tokens.
Key findings:
- The discriminatively-induced latent space is much more stable under input noise and less sensitive to token prediction errors, making it more suitable for autoregressive image generation.
- The resulting model, called DiGIT, achieves state-of-the-art results on image understanding and image generation tasks. It even surpasses diffusion models and scales well with increased model size (mirroring the scaling success of GPT in text).
- Ablation studies show that a larger token vocabulary improves performance; the stability of the latent space is empirically and theoretically analyzed, drawing parallels between self-supervised discriminative encoders (LDA) and reconstructive autoencoders (PCA).
- This approach challenges the conventional view that reconstruction-optimized latent spaces are ideal for generative modeling, advocating for stability-targeted designs instead.
15. UniFlow
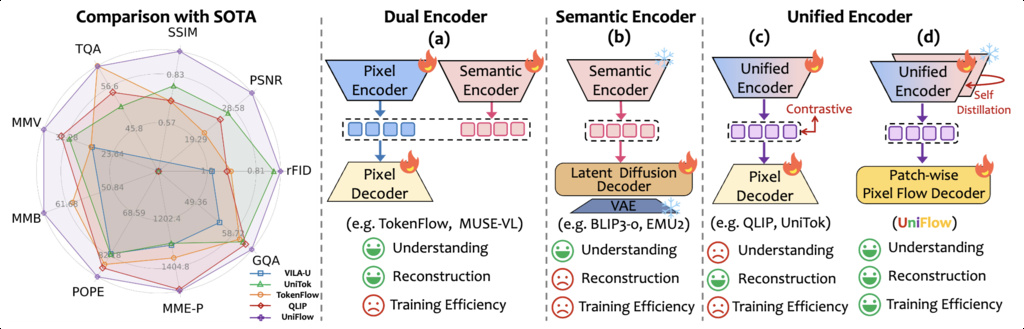
,caption: [Comparison of different training paradigms for unified tokenizers.])
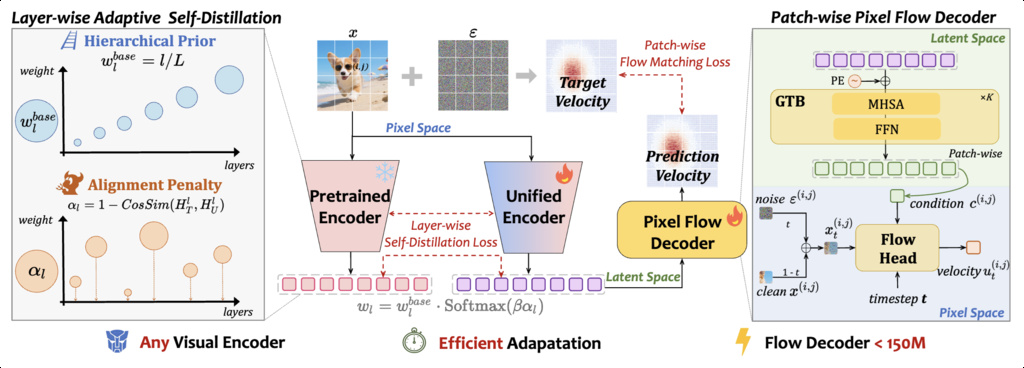
UniFlow proposes a new unified vision tokenizer designed for both visual understanding and generation tasks, overcoming trade-offs faced by existing approaches.
Method Design: UniFlow flexibly adapts pretrained vision encoders and introduces a lightweight pixel flow decoder for high-fidelity pixel reconstruction. Its core innovation is a hierarchical adaptive self-distillation mechanism, letting the unified encoder inherit strong semantic capability while preserving fine visual details and improving training efficiency.
References
- Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
- No Other Representation Component Is Needed: Diffusion Transformers Can Provide Representation Guidance by Themselves
- Deeply Supervised Flow-Based Generative Models
- Decoupled Diffusion Transformer
- Representation Entanglement for Generation: Training Diffusion Transformers Is Much Easier Than You Think
- Boosting Generative Image Modeling via Joint Image-Feature Synthesis
- REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers
- U-REPA: Aligning Diffusion U-Nets to ViTs
- Aligning Text to Image in Diffusion Models is Easier Than You Think
- LayerSync: Self-aligning Intermediate Layers
- Diffusion Transformers with Representation Autoencoders
- Advancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
- Latent Diffusion Model without Variational Autoencoder
- Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective
- UniFlow: A Unified Pixel Flow Tokenizer for Visual Understanding and Generation