Latent Diffusion Models
1. Latent Diffusion Models
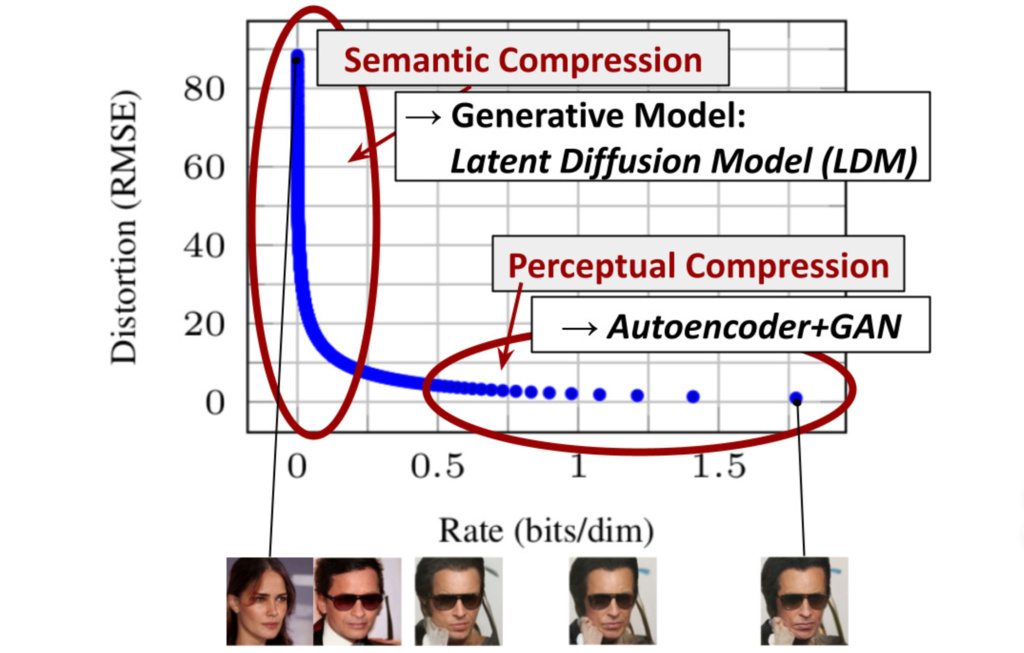
Latent diffusion model (LDM) runs the diffusion process in the latent space instead of pixel space, making training cost lower and inference speed faster. It is motivated by the observation that most bits of an image contribute to perceptual details and the semantic and conceptual composition still remains after aggressive compression. LDM loosely decomposes the perceptual compression and semantic compression with generative modeling learning by first trimming off pixel-level redundancy with autoencoder and then manipulating / generating semantic concepts with diffusion process on learned latent.
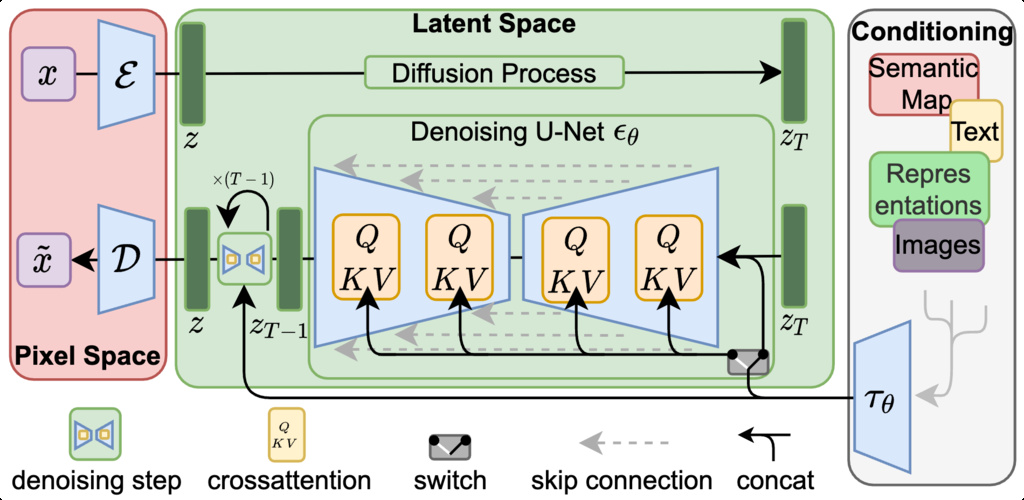
LDMs separate the image generation process into two distinct phases:
- Perceptual Compression: An autoencoder is trained to map images into a lower-dimensional latent space that is perceptually equivalent to the original image space. This process removes high-frequency, imperceptible details. The model consists of an encoder () and a decoder ().
- Semantic Compression: A diffusion model is then trained on this computationally efficient latent space to learn the semantic and conceptual composition of the data.
The paper explored two types of regularization in autoencoder training to avoid arbitrarily high-variance in the latent spaces.
- KL-reg: A small KL penalty towards a standard normal distribution over the learned latent, similar to VAE.
- VQ-reg: Uses a vector quantization layer within the decoder, like VQVAE but the quantization layer is absorbed by the decoder.
The diffusion and denoising processes happen on the latent vector . The denoising model is a time-conditioned U-Net, augmented with the cross-attention mechanism to handle flexible conditioning information for image generation (e.g. class labels, semantic maps, blurred variants of an image). The design is equivalent to fuse representation of different modality into the model with a cross-attention mechanism.