Language Diffusion Model
1. Large Language Diffusion with mAsking (LLaDA)
The core process involves two stages:
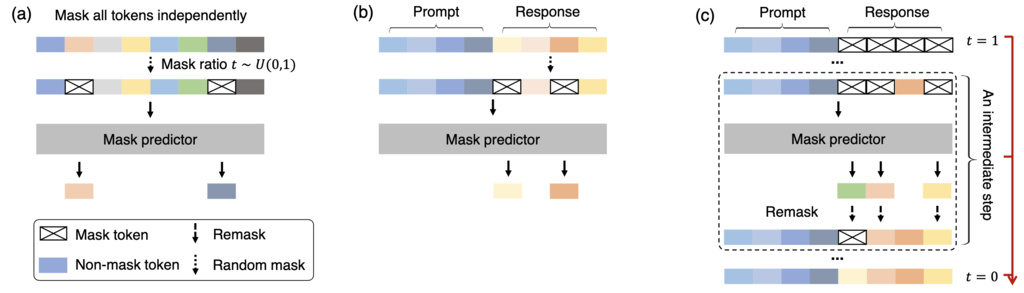
- Forward Masking Process: It takes a clean text sequence and progressively corrupts it by independently masking tokens with a probability . This masking ratio is randomly sampled from 0 to 1 for each training sample, meaning the model sees everything from slightly masked to fully masked text.
- Reverse Prediction Process: A Transformer model1 is trained to predict all the masked tokens simultaneously given the corrupted text. This process is optimized as a principled generative modeling objective, which allows LLaDA to learn the underlying data distribution.
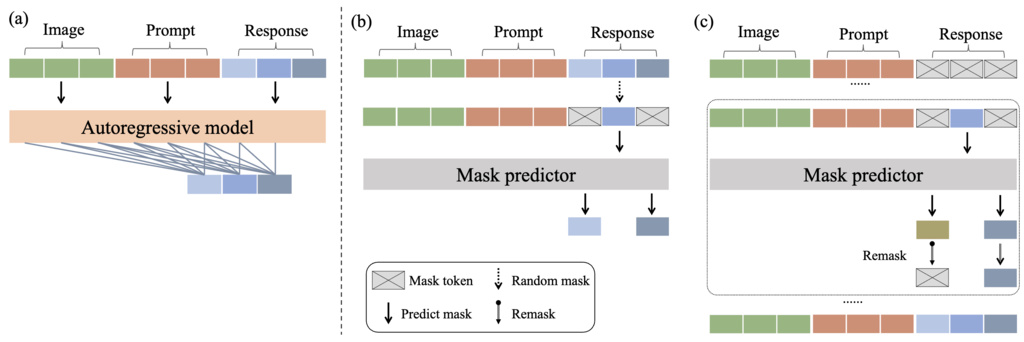
1.1. Remasking?
At each step of the generation process, the model predicts all the masked tokens simultaneously. However, instead of keeping all of these newly predicted words, the model intentionally "remasks" some of them, turning them back into mask tokens for the next step. The number of tokens that are remasked is gradually reduced at each step until no masks are left.
Remasking Strategies in LLaDA:
- Random Remasking: In principle, the tokens to be remasked can be chosen randomly.
- Low-Confidence Remasking: A more advanced strategy is to remask the tokens that the model predicted with the lowest confidence. This allows the model to "re-think" the parts of the sentence it is least sure about in the next step.
- Semi-Autoregressive Remasking: For the instruction-following version of LLaDA, we can divide the sequence into several blocks and generate them from left to right. Within each block, a remasking strategy (like low-confidence remasking) is applied. This approach was found to be particularly effective for the instruction-tuned model.
2. LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning