KL Divergence and its variants
1. KL Divergence and its variants
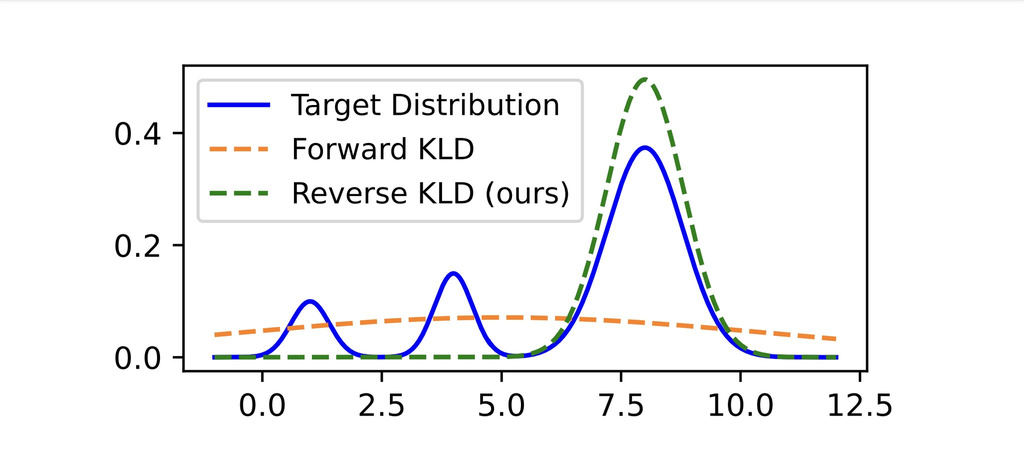
Forward (inclusive) KL: where is the true distribution and is the approximating distribution.
- Mode covering: Since we sample from and penalize when is small, tends to cover all modes of (even if it means being over-dispersed). If but , the penalty is large.
- Typical use: Maximize likelihood, VAE (ensures decoder explains all data)
Reverse (exclusive) KL:
- Mode seeking: Since we sample from and penalize when is small, tends to concentrate on a single mode of (under-dispersed but sharper). If but , the penalty is large.
- Reduces exposure bias 1
- Typical use: Variational inference, policy optimization in RL
1.1. Jensen-Shannon Divergence
JSD measures divergence relative to the mixture distribution , which makes it:
- Symmetric: (unlike KL)
- Bounded: (log 2 when distributions have disjoint support)
- Nearly a metric: satisfies triangle inequality
- Balances between mode-covering and mode-seeking behavior of KL variants
1.2. Wasserstein Distance
The distribution of is called the push-forward of , denoted by
The Monge version of the optimal transport distance is where the infimum is over all such that . Intuitively, this measures how far you have to move the mass of to turn it into . A minimizer , if one exists, is called the optimal transport map.
Let denote all joint distributions for that have marginals and . In other words, and where and . Then the Wasserstein distance is
where . When , this is also called the Earth Mover's Distance.
It can be shown from Kantorovich Rubinstein Duality that
where . When , we have
where means .
When to use Wasserstein Distance instead of KL:
- Non-overlapping distributions: KL divergence becomes infinite (or undefined) when distributions have non-overlapping support, while WD remains finite and meaningful. This is critical in high-dimensional spaces where distributions rarely overlap perfectly.
- Meaningful gradients: Even when distributions barely overlap, WD provides useful gradients for optimization. This is why Wasserstein GAN (WGAN)) works better than vanilla GAN - it can still learn when the generator distribution is far from the real data distribution.
- True metric: WD is a proper distance metric (satisfies triangle inequality), making it more suitable for geometric interpretations and certain theoretical analyses.
- Weak topology: WD convergence is weaker than KL convergence, meaning implies convergence in distribution, which is often more natural for generative modeling.
1.3. Fisher Divergence
Unlike KL divergence which compares probability values, Fisher divergence compares the score functions (gradients of log probabilities). This makes it particularly useful when:
- Dealing with unnormalized distributions (only need score functions, not normalization constants)
- Training score-based generative models
- The score function is more well-behaved than the density itself
1.4. Applications
- Variational Inference: Reverse KL (mode-seeking behavior prevents over-dispersed approximations)
- GAN: JSD (symmetric, bounded measure between real and generated distributions)
- WGAN: Wasserstein Distance (stable training with meaningful gradients)
- VAE: Forward KL (mode-covering ensures all data modes are explained)
- RL (e.g., PPO, TRPO): Reverse KL (prevents policy from assigning probability to bad actions)
- Score-based models (diffusion): Fisher Divergence (training without normalized densities)