Flow map matching
1. Flow map matching (FMM)
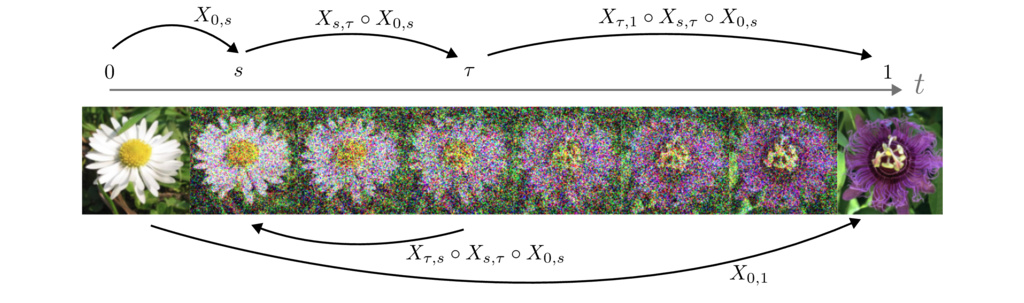
The central object in our method is the flow map, which maps points along trajectories of solutions to an ordinary differential equation (ODE)
1.1. Stochastic interpolants and probability flows
Stochastic interpolant: , where , and .
Probability flow: The probability density of is the solution to
where . The drift can be learned efficiently in practice by solving a square loss regression problem
1.2. Flow map: definition and characterizations
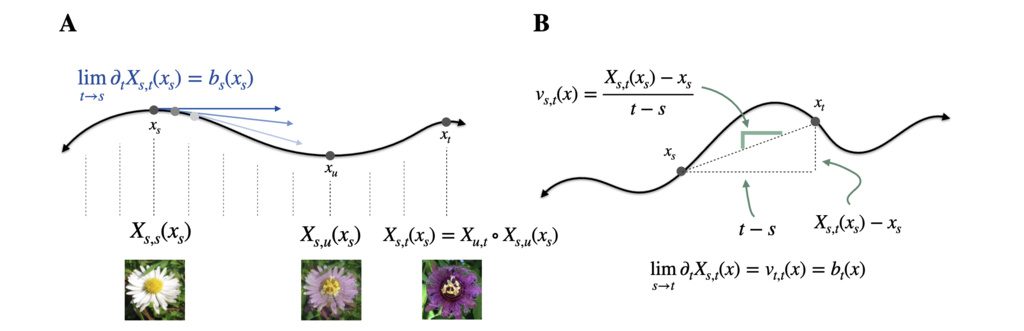
Flow map: The flow map is the unique map such that
where is any solution to the ODE.
Tangent condition: Let denote the flow map. Then
We define as the exact remainder obtained by truncating a Taylor expansion in of at first order
Geometrically, describes the “slope” of the line drawn between and on a single ODE trajectory.
Some of its useful properties: The flow map is the unique solution to the Lagrangian equation
for all . In addition, it satisfies
for all . In particular, for all , i.e., the flow map is invertible.
The flow map is the unique solution of the Eulerian equation,
for all .
1.3. Flow map training
1.3.1. Distillation of a known velocity field
Lagrangian map distillation: Let be a weight function satisfying and let be the stochastic interpolant. Then the flow map is the global minimizer over of the loss
subject to the boundary condition that for all and . denotes an expectation over the coupling and .

Eulerian map distillation: The flow map is the global minimizer over of the loss

1.3.1.1. From Distillation to Direct Training: The stopgrad Necessity
The distillation losses and assume that we have access to the true, smooth drift field . A natural question arises: what if is unknown and we only have access to samples from the stochastic interpolant, including the noisy velocity ?
A naive approach might be to simply replace the true drift with its single-sample, noisy estimate in the loss function. For example, the Eulerian loss would become:
However, this naive objective is flawed and will not converge to the correct flow map .
The issue lies in the relationship . The term is a random variable, while is its conditional mean. Due to the property , the naive loss implicitly contains an extra variance term:
This extra variance term acts as a penalty that depends on . To minimize the total loss, the optimizer is incentivized to find a solution with an artificially small gradient , leading to a biased and incorrect result.
To counteract this, a common technique is to use a stop-gradient operator. The operator, stopgrad(z), allows z to pass through during the forward pass but blocks gradients from flowing back through it during optimization. A corrected Eulerian loss would look like:
By blocking the gradient from the noisy term, we can ensure that the expected gradient of the loss is zero at the true solution, making it a valid objective.
This challenge of handling noisy velocities directly is a primary motivation for developing more sophisticated objectives like Flow Map Matching (FMM), which we introduce next. FMM provides an alternative, well-posed loss function for direct training.
1.3.2. Direct training with flow map matching (FMM)
Flow map matching: The flow map is the global minimizer over of the loss

1.3.3. Progressive distillation
Progressive flow map matching: Let be a two-time flow map. Given , let for . Then the objective
produces the same output in one step as the -step iterated map .

1.3.4. Self-distillation
Self-distillation: The flow map is given for all by where the unique minimizer over of
where is given by
and where is any linear combination of the following three objectives:
(i) The Lagrangian self-distillation (LSD) objective,
(ii) The Eulerian self-distillation (ESD) objective,
(iii) The progressive self-distillation (PSD) objective,
Above, and denotes an expectation over the random draw of .

1.3.5. Align your flow (AYF)
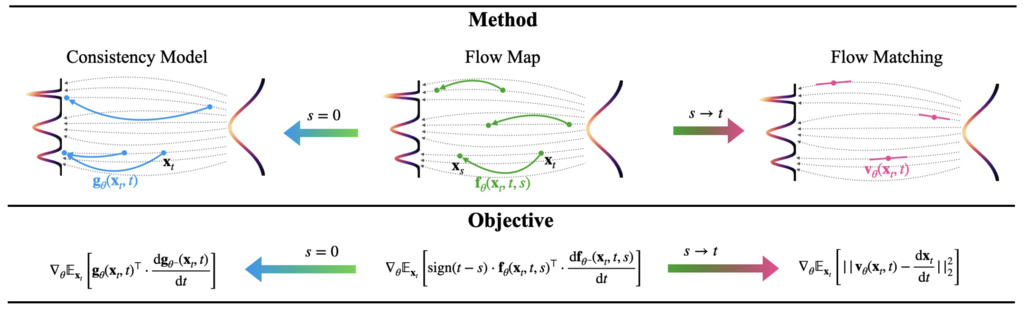
The first training objective aims to ensure that for a fixed , the output of the flow map remains constant as we move along the PF-ODE.
AYF-Eulerian Map Distillation (AYF-EMD): Let be the flow map. Consider the loss function defined between two adjacent starting time steps and for a small ,
where is obtained by applying a 1-step Euler solver to the PF-ODE from to . In the limit as , the gradient of this loss function with respect to gives
where . The AYF-EMD loss naturally generalizes the loss used to train continuous-time consistency models, as it reduces to the same objective when .
The second approach ensures consistency at timestep instead. This method tries to ensure that for a fixed , the trajectory is aligned with that points' PF-ODE.
AYF-Lagrangian Map Distillation (AYF-LMD): Let be the flow map. Consider the loss function defined between two adjacent ending timesteps and for a small ,
where refers to running a 1-step Euler solver on the PF-ODE starting from at timestep to timestep . In the limit as , the gradient of this objective with respect to converges to:
where .