Elucidating the Design Space of Diffusion-Based Generative Models
1. Elucidating the Design Space of Diffusion-Based Generative Models
Elucidating the Design Space of Diffusion-Based Generative Models (EDM) provides the first comprehensive theoretical and empirical analysis of the design choices that define these powerful generative systems.
1.1. Unified Mathematical Framework
1.1.1. The Central Insight: Denoising Score Matching
The fundamental insight of EDM is that diffusion models can be understood through the lens of denoising score matching. Given a data distribution , we consider the family of mollified distributions:
This represents the data distribution corrupted by Gaussian noise with standard deviation . The key mathematical insight is that the score function can be learned through denoising:
where is the optimal denoiser that minimizes:
1.1.2. Probability Flow ODE
EDM reformulates the diffusion process as a deterministic probability flow ODE. The evolution of samples is governed by:
where is a noise schedule and is its time derivative. Substituting the denoising connection:
Intuition: The ODE continuously moves samples toward the denoised estimate. At each time step, the network predicts what the clean image should be, and the ODE moves the current sample in that direction.
1.1.3. The Choice of
EDM demonstrates that setting leads to particularly well-behaved trajectories. With this choice, the ODE simplifies to:
Key insight: A single Euler step from any point to yields exactly the denoiser output . This means the ODE tangent always points toward the denoised image, creating nearly linear solution trajectories that are numerically stable.
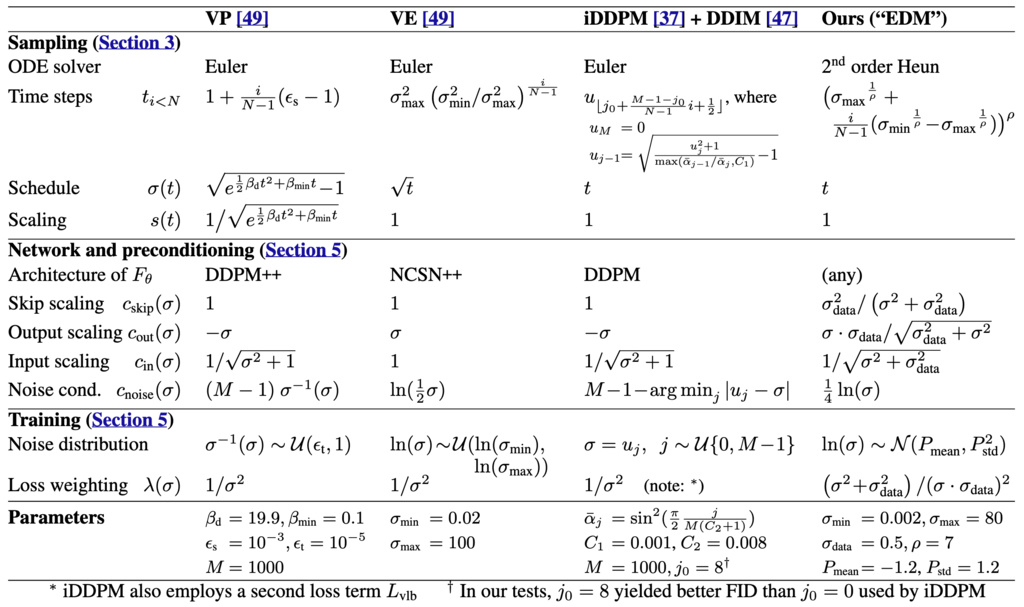
1.2. Preconditioning: The Heart of EDM
1.2.1. The Problem with Naive Training
Training a network to directly predict is problematic because:
- Input magnitude varies dramatically with noise level
- Output targets range from noisy images (high ) to clean images (low )
- Gradient magnitudes vary wildly across different values
1.2.2. EDM's Preconditioning Solution
Instead of learning directly, EDM proposes learning a preconditioned network:
where is the actual neural network and the functions are deterministic preconditioning functions.
1.2.3. Deriving the Preconditioning Functions
EDM derives these functions from first principles:
Input scaling : Normalizes input to unit variance
Output scaling : Balances signal and noise components
Skip connection : Preserves input information optimally
Intuition: At low noise (), the skip connection dominates and the network only needs to remove small perturbations. At high noise (), the network output dominates and learns to extract signal from pure noise.
1.3. Improvements to the Sampling Process
EDM argues that the sampling process is largely independent of the network's training and can be optimized as a standalone component. The key improvements are:
1.3.1. Deterministic Sampling
-
2nd-Order ODE Solver: By replacing the standard 1st-order Euler solver with a 2nd-order Heun method, the sampler can take larger, more accurate steps along the solution trajectory.
Intuition: A 1st-order solver assumes the direction (dx/dt) is constant over a step. A 2nd-order solver looks ahead, corrects for the changing direction, and thus follows the curved path more faithfully. This drastically reduces the number of steps (NFE) needed for high quality.
-
Time Step Discretization: The paper shows that concentrating sampling steps in the low-noise regime is critical for perceptual quality. A polynomial schedule with is chosen empirically to focus the sampler's "effort" where it matters most.
Intuition: Errors made at high noise levels (blurry, abstract shapes) are less visually damaging than errors made at low noise levels (fine details, textures). Therefore, we should take careful, small steps when the image is almost finished.
1.3.2. Stochastic Sampling
While deterministic sampling is efficient, stochastic sampling can correct errors and often yields better FID scores.
EDM introduces a custom sampler that first adds a controlled amount of noise (a "churn" step) and then takes a 2nd-order deterministic step to denoise. This process is carefully controlled with heuristics to prevent image degradation, such as limiting stochasticity to a specific noise range .
1.4. Training Objective and Loss Weighting
1.4.1. The Effective Training Target
With preconditioning, the effective training target for becomes:
This simplifies to learning the normalized noise residual rather than the absolute denoised image.
1.4.2. Optimal Loss Weighting
EDM derives the loss weighting that equalizes training emphasis across noise levels:
Mathematical insight: This weighting ensures that errors in are amplified equally regardless of noise level, preventing the training from being dominated by any particular range.
1.4.3. Log-Normal Noise Distribution
Instead of uniform sampling of , EDM uses a log-normal distribution:
Rationale: Training loss is only reducible in intermediate noise ranges. At very low noise, the signal is nearly clean (nothing to learn). At very high noise, the target approaches the dataset mean (little structure to capture).
1.4.4. Non-leaky Augmentation
To combat overfitting, especially on smaller datasets, EDM employs a conditional augmentation pipeline. Geometric transformations are applied to training images, and the transformation parameters are fed to the network as a condition.