Diffusion Transformers (DiTs) and Scalable Interpolant Transformers (SiT)
1. Diffusion Transformers (DiTs)
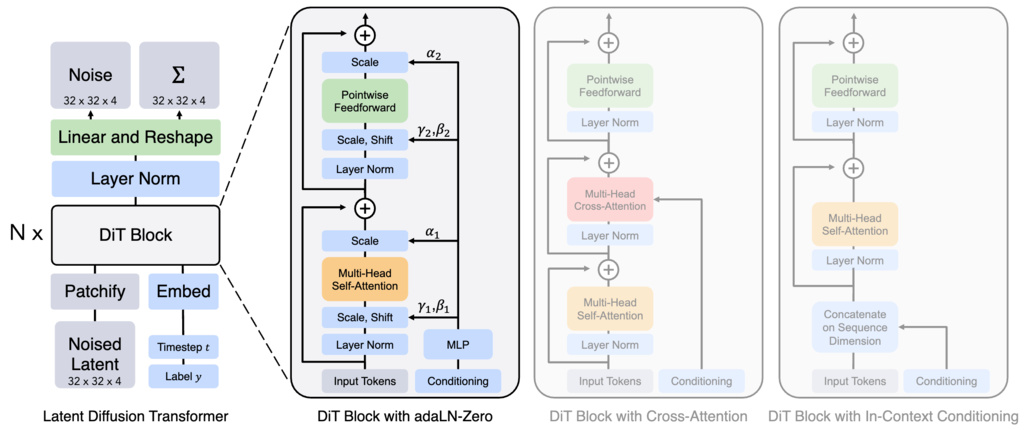
- An image is first compressed into a smaller spatial representation (a "latent") using a pre-trained VAE
- Take the latent representation of an input as input to DiT. "Patchify" the noise latent of size into patches of size and convert it into a sequence of patches of size
- Then this sequence of tokens go through Transformer blocks. They explore three different designs for how to do generation conditioned on contextual information. Among three designs, adaLN (Adaptive layer norm)-Zero works out the best, better than in-context conditioning and cross-attention block. The scale and shift parameters, and , are regressed from the sum of the embedding vectors of and . The dimension-wise scaling parameters is also regressed and applied immediately prior to any residual connections within the DiT block
- The transformer decoder outputs noise predictions and an output diagonal covariance prediction
2. Scalable Interpolant Transformers (SiT)
SiT design space:
-
Time discretization: Discrete-time or continuous-time?
- Adopting a continuous-time training framework provides significant flexibility. It decouples the model's training process from the number of steps used during sampling, which allows one to trade off inference speed and sample quality after the model is already trained.
-
Model prediction: Score or velocity field?
- The choice of what the model predicts is critical. Training the model to predict the velocity field () using a velocity loss (), or using an equivalent weighted score loss (), leads to substantially better performance than predicting the standard score. This is because the velocity parameterization effectively compensates for the vanishing gradients that the standard score objective suffers from when the noise level is low (as ).
-
Interpolant: SBDM-VP, linear or GVP (Generalized VP)?
- Linear () and GVP () outperform the standard SBDM-VP path used in many diffusion models. These superior paths are more direct and have a lower "transport cost," which simplifies the learning problem by reducing the curvature of the generation trajectories.
-
Sampler: ODE or SDE? Choose which diffusion coefficient?
- First, using a stochastic sampler (SDE) generally produces higher-quality final samples (lower FID scores) compared to a deterministic one (ODE), as it offers better theoretical control over the KL divergence.
- Second, the diffusion coefficient () in the SDE sampler is a highly effective and tunable parameter. A major finding is that can be chosen and optimized after the model has been trained, without any retraining cost. By selecting a theoretically motivated that minimizes an upper bound on the KL divergence, the model's performance can be further improved.
3. MaskDiT
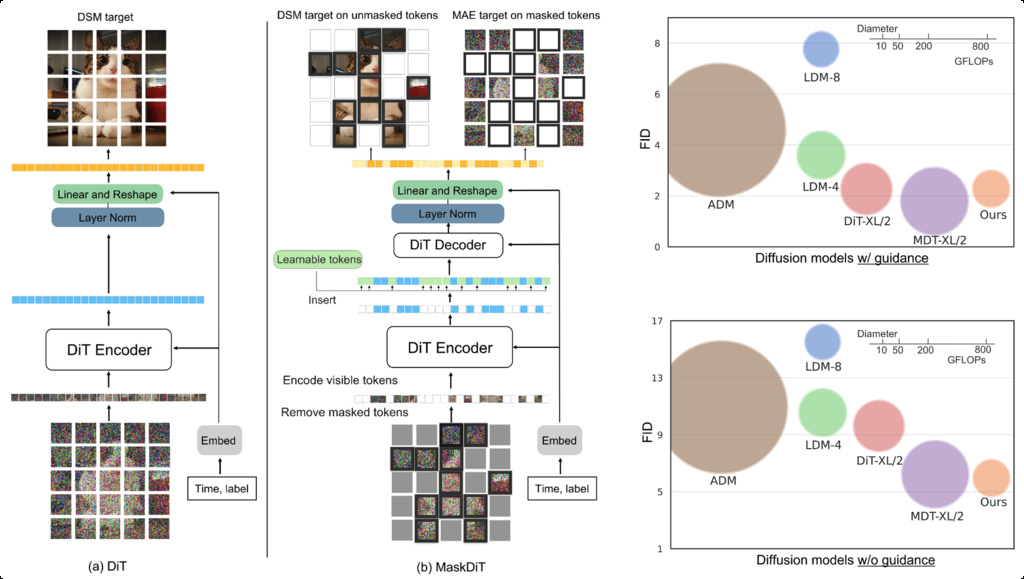
MaskDiT introduces a masked autoencoder (MAE) approach specifically designed for diffusion transformers. The key innovation lies in decomposing the traditional diffusion training objective into two complementary subtasks:
- Score estimation on unmasked patches: The model learns to predict noise/velocity on visible image patches
- MAE reconstruction on masked patches: The model reconstructs missing patches based on visible context
The training objective combines both tasks:
where the denoising score matching loss is:
and the MAE reconstruction loss is:
Here represents the binary masking pattern, denotes element-wise multiplication, and is the diffusion transformer model.
4. SD-DiT
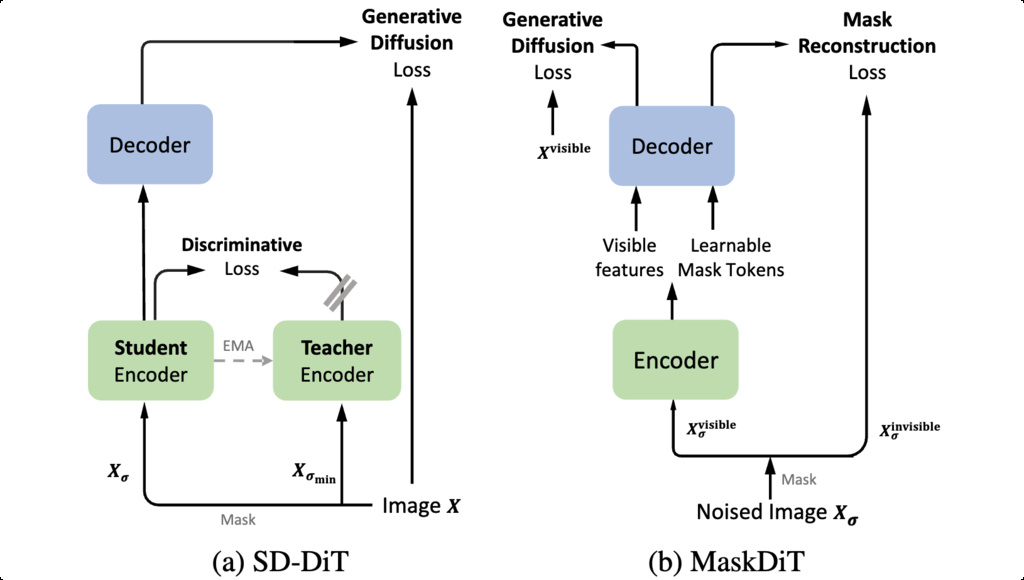
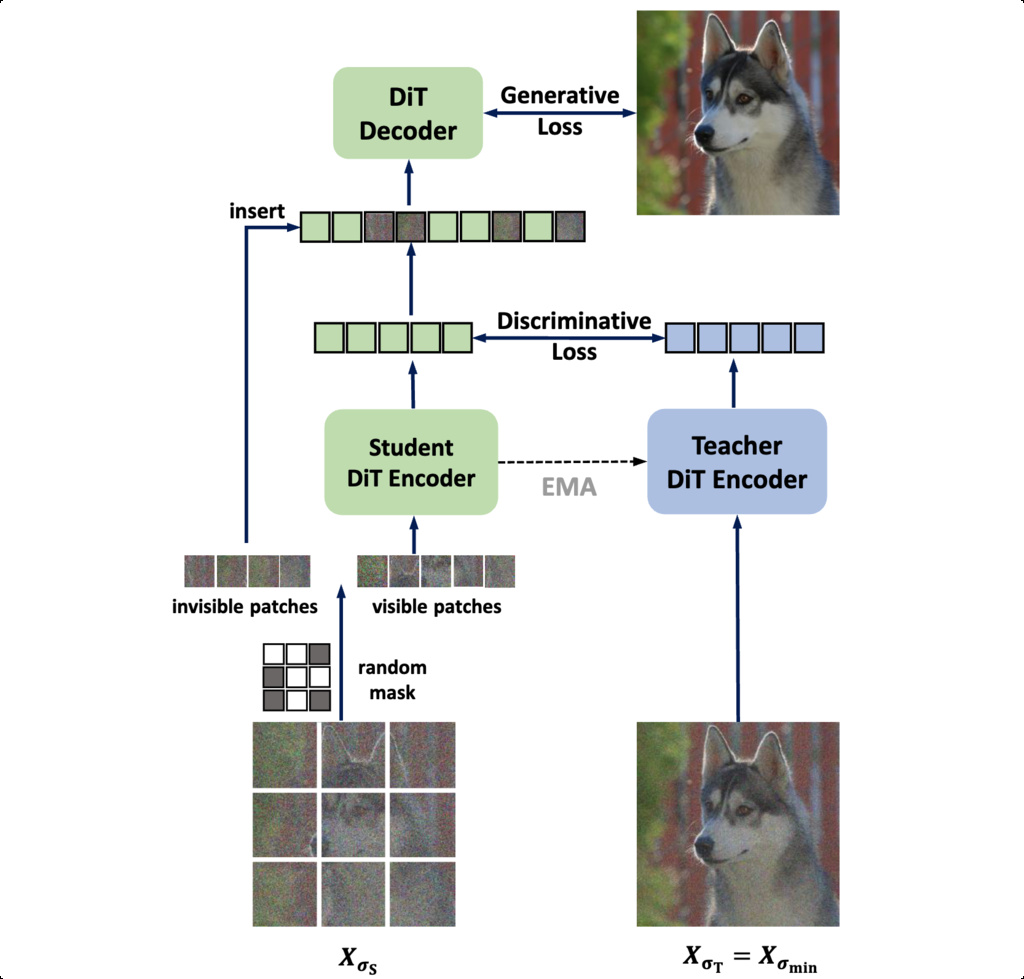
SD-DiT's architecture is built upon a decoupled encoder-decoder structure within a teacher-student scheme. This design separates the discriminative and generative learning processes. The model comprises a student encoder, a student decoder, and a teacher encoder whose weights are an exponential moving average (EMA) of the student encoder's weights.
The model is trained using two distinct objectives: a Generative Loss and a Discriminative Loss.
4.1. Generative Objective
The generative task is handled by the student branch (encoder and decoder). The student encoder processes only the visible patches of a noised and masked input image. To avoid the training-inference discrepancy, the decoder is fed the processed visible tokens along with the original, unmodified invisible patches, rather than learnable mask tokens. The objective is to denoise the full image using the standard EDM loss formulation.
The generative loss is defined as:
Here, represents the student branch, is the variable noise level for the student view, and is the binary mask.
4.2. Discriminative Objective
The discriminative task aims to enforce inter-image alignment between the student and teacher encoder outputs in a shared embedding space. This is achieved by minimizing the cross-entropy loss between the softmax probability distributions of the student's visible tokens and the teacher's corresponding tokens.
The teacher view, , is created using a fixed, minimal noise level () to serve as a high-quality, stable reference, a concept inspired by Consistency Models. For each visible token , the loss is:
The total discriminative loss is averaged over all visible tokens and the [CLS] token:
The final training objective for the student network is the sum of both losses:
References
- What are Diffusion Models?
- Scalable Diffusion Models with Transformers
- SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers
- Fast Training of Diffusion Models with Masked Transformers
- SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer