Direct Modeling
1. Directly model
1.1. Hopfield Network
Associative memories networks try to associate an input with its most similar pattern. The purpose is to store and retrieve patterns.
The Energy of Hopfield Network is .
At each time each neuron receives a "field" . If , then is preferred; if , then is preferred. If everything is preferred, the is maximized. If not, we have to flip some neurons to make it preferred.
Any flip that changes to increases by . Since , we know it converges with a finite number of flips.
Training: If we want to store patterns, we use Hebbian Learning Rule to set to get lowest possible energy. But this may cause spurious local optima.
How to prevent spurious local optima? We have to modify the energy landscape. We can use negative samples to do contrastive learning, which means we also maximize for all non-desired patterns. , we can use SGD to optimize : . Since only those shallow valleys may misdirect model, we try to broaden desired patterns valleys and narrow non-desired patterns valleys. So we update by . We initialize by all the desired patterns and run evolution for with small random noise to get the valley that is close to the desired valley since those are most misleading.
But there's another problem: Naively forcing a valley to raise may hurt the learned representation. Thus we only run evolution for for a few timesteps.
1.2. Boltzmann Machine
Given an energy function , if we follow a proper physical evolution process, the system state will converge to the Boltzmann distribution . We can generate patterns by sampling from , which makes a deterministic process to a probabilistic one.
. Thus the network revolution becomes . Retrieval a stored pattern can be done by taking the average of final samples: (We can take for simplicity).
Training: , log likelihood . To maximize , we can use SGD:
We use Restricted Boltzmann Machine (RBM) for faster Gibbs sampling mixing. We have hidden neurons and visible neurons and there's no intra-layer connection. Previously we sample from every neurons and Gibbs sampling gurantees the convergence, but now we can sample from hidden neurons and visible neurons alternatively. Since there are no connections within the same layer, all neurons in the same layer can be sampled in parallel.
1.2.1. Sampling
Sampling from :
- Inverse Transform Sampling:
If a random variable has a Cumulative Distribution Function (CDF) . We can sample a value from and set . This only works if we can compute CDF and its inverse.
- Box-Muller Transform:
This is a specialized and highly efficient method for sampling from a standard normal (Gaussian) distribution. First draw and from the standard uniform distribution . Transform them into two independent standard normal samples: , . Then Both and are independent random variables sampled from the standard normal distribution .
- Importance Sampling:
We can sample from by sampling from proposal distribution and then weighting the samples by the ratio .
-
MCMC:
- Irreducibility: A Markov chain is irreducible if, for any two states , there exists an integer such that: . This means it is possible to reach any state from any other state in a finite number of steps.
- Aperiodicity: A Markov chain is aperiodic if, for every state , the greatest common divisor of the set is 1: . This ensures the chain does not get trapped in cycles.
- Existence of Stationary Distribution: There exists a distribution such that: or in vector notation, . This is called the stationary or invariant distribution.
- Detailed Balance (Reversibility): A stronger condition than stationarity, detailed balance requires that for all states : . If this holds, then is a stationary distribution for .
- Metropolis-Hastings (M-H) Algorithm:
For :
- Draw a candidate from a proposal distribution .
- Compute the acceptance ratio , the formula simplifies to if .
-
Draw a uniform random number from .
- If , then .
- Otherwise, .
- Gibbs Sampling:
A special case of the M-H algorithm that is particularly efficient for multidimensional distributions, especially when the conditional distribution of each dimension is easy to sample from.
- Randomly initialize .
-
For :
-
For :
- Sample from .
-
1.3. Normalizing Flows
Simplify the generation process.
Change of Variables rule:
,
1.3.1. Planar Flow
where are free parameters and is a smooth element-wise non-linearity (e.g. tanh, ReLU, etc.).
The flow defined by the transformation modifies the initial density by applying a series of contractions and expansions in the direction perpendicular to the hyperplane , hence we refer to these maps as planar flows.
However, does not admit an analytical expression, and one must resort to iterative algorithms such as Newton's method to approximate it.
1.3.2. NICE (Non-linear Independent Component Estimation)
We denote and call the encoder and its inverse the decoder. With given, we can generate from by ancestral sampling.
We want "easy determinant of the Jacobian" and "easy inverse".
General Coupling Layer: Partition into two disjoint subsets and . We can define , where , is a function (e.g. MLP) and is the coupling law. We consider and , then
For simplicity, we choose additive coupling law . Thus . Each transformation is simple, so we stack multiple layers to get a complex transformation. .
Combining coupling layers: Since a coupling layer leaves part of its input unchanged, we need to exchange the role of the two subsets in the partition in alternating layers, so that the composition of two coupling layers modifies every dimension.
Re-Scaling Layer: we include a diagonal scaling matrix as the top layer to ensure non-unit volume transformation, which multiplies the i-th ouput value by : . This allows the learner to give more weight (i.e. model more variation) on some dimensions and less in others. In the limit where goes to for some , the effective dimensionality of the data has been reduced by 1. We can relate these scaling factors to the eigenspectrum of a PCA, showing how much variation is present in each of the latent dimensions (the larger is, the less important the dimension is).
Inpainting: For inpainting we clamp the observed dimensions () to their values and maximize loglikelihood with respect to the hidden dimensions () using projected gradient ascent (to keep the input in its original interval of values) with gaussian noise with step size , where i is the iteration, following the stochastic gradient update:
1.3.3. Real NVP
Real-valued non-volume preserving (Real NVP) transformations.
Affine Coupling Layer: , where and stand for scale and translation. The Jacobian of this transformation is
And the inverse transformation is .
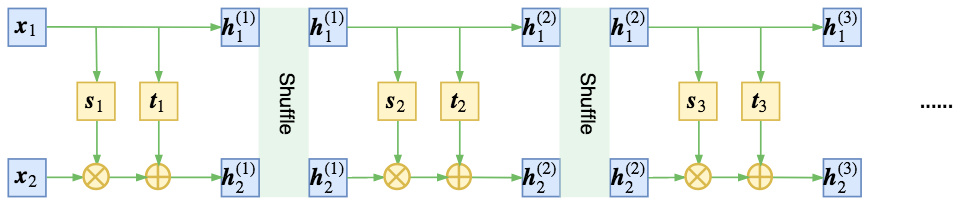
1.3.4. GLOW
NICE exchanges partitions, Real NVP shuffles, GLOW uses learnable and invertible 1x1 convolutions as mixing layers. . The cost of computing or differentiating is . We use LU decomposition to reduce to . , where is a permutation matrix, is a lower triangular matrix with ones on the diagonal, is a diagonal matrix with zeros on the diagonal, and is a vector. .