Contrastive Flow Matching
1. Contrastive Flow Matching

In conditional flow, the model may collapse multiple diverse outputs into a single trajectory, yielding samples that lack the expected specificity and diversity for each condition.
Contrastive Flow Matching (CFM) applies a pairwise loss term between samples in a training batch: for each positive sample from the batch, we randomly sample a negative counterpart.
2. Dispersive Loss
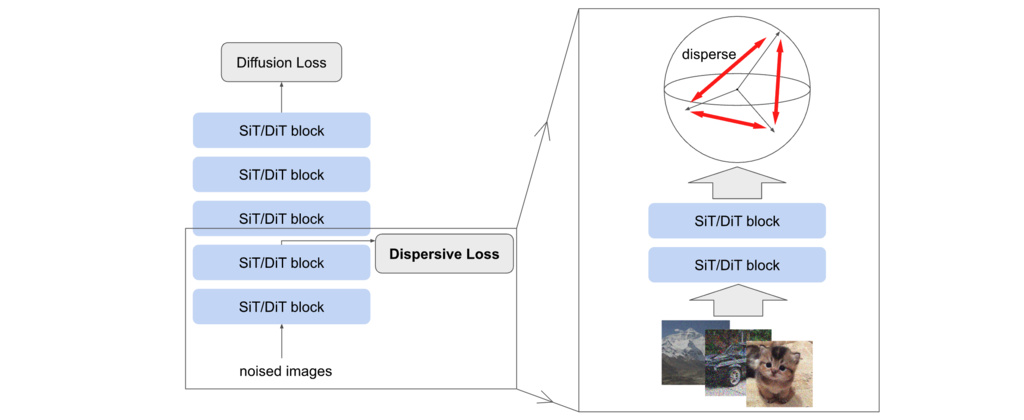
Intuitively, Dispersive Loss encourages internal representations to spread out in the hidden space, analogous to the repulsive effect in contrastive learning. Meanwhile, the original regression loss (e.g., denoising) naturally serves as an alignment mechanism, eliminating the need to manually define positive pairs as in contrastive learning.
This method is self-contained and minimalist. Conceptually, Dispersive Loss can be derived from any existing contrastive loss by appropriately removing the positive terms. In this regard, the term “Dispersive Loss” does not refer to a specific implementation, but rather to a general class of objectives that encourage dispersion. We introduce several variants of Dispersive Loss functions in the following.
| Variant | Contrastive | Dispersive |
|---|---|---|
| InfoNCE | ||
| Hinge | ||
| Covariance |
Dispersive vs. Contrastive. We compare different variants of Dispersive Loss with their contrastive counterparts. To apply a contrastive loss, two views are sampled for each training example to form a positive pair. We study two strategies for adding noise to both views: (i) sampling noise independently for each view, following the generative model’s noising policy; or (ii) sampling noise for the first view according to the same policy, and then restricting the second view’s noise level to differ by at most 0.005. Moreover, to avoid doubling training epochs due to two-view sampling, we only apply the denoising loss to the first view, for fair comparisons with both the baseline and our method.
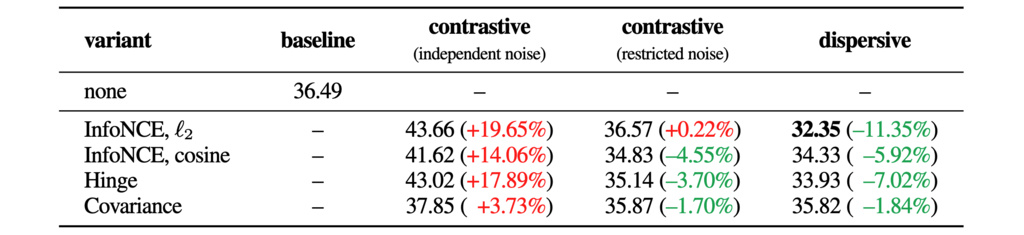
Table shows that when using independent noise, the contrastive loss fails to improve generation quality in all cases studied. We hypothesize that aligning two views with substantially different noise levels impairs learning. As evidence, Table shows that contrastive loss with restricted noise leads to improvements over the baseline in three of the four evaluated variants. These experiments suggest that contrastive learning is sensitive to the choice of data augmentation. Noising, which serves as a built-in form of augmentation in diffusion models, further complicates the problem. While contrastive learning can be mildly beneficial, the design of the additional view and the coupling of two views may limit its application.