Consistency Models
1. Consistency Models
While diffusion models achieve remarkable sample quality, they require hundreds or thousands of function evaluations during generation, making them computationally expensive for real-time applications.
The key insight behind Consistency Models is to learn a direct mapping from noise to data, enabling single-step generation while preserving the high-quality outputs characteristic of diffusion models.
1.1. The Core Intuition
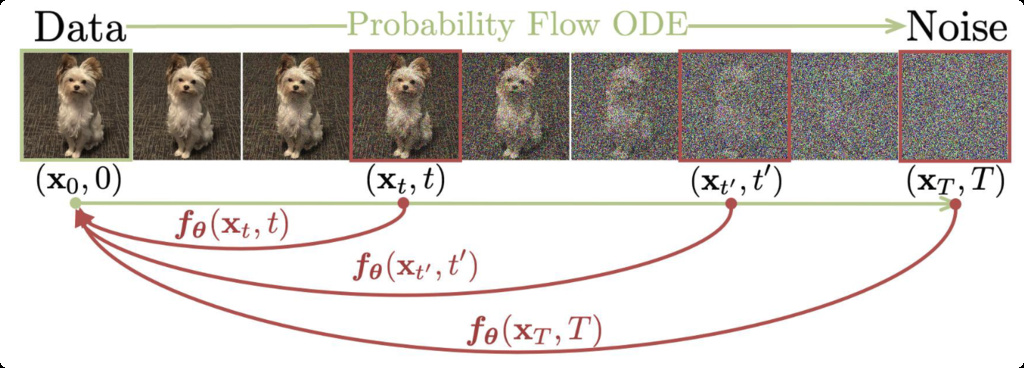
The fundamental idea of Consistency Models stems from a simple yet powerful observation: if we can learn to map any point on a diffusion trajectory directly to its corresponding clean data point, we can bypass the iterative denoising process entirely.
Consider the probability flow ODE that underlies diffusion models:
This ODE defines a deterministic trajectory from noise to data . A Consistency Model learns a function that maps any point on this trajectory to the trajectory's origin .
1.1.1. Self-Consistency Property
The defining characteristic of Consistency Models is the self-consistency property:
Definition: A function satisfies the self-consistency property if:
In other words, for any two points on the same trajectory, the consistency function should map both to the same endpoint. This ensures that:
- (identity mapping at the boundary)
- for all (consistent prediction)
1.2. Mathematical Framework
1.2.1. Parameterization
To ensure the boundary condition , Consistency Models use a specific parameterization:
where is a deep neural network. In practice, this is implemented as:
with , , ensuring the boundary condition is satisfied.
1.2.2. Discretized Training
For computational tractability, the continuous time interval is discretized into timesteps:
The consistency function is trained to satisfy:
for consecutive timesteps on the same trajectory.
1.3. Training Methods
There are two primary approaches to training Consistency Models, each with distinct advantages and trade-offs.
1.3.1. Consistency Distillation (CD)
Consistency Distillation leverages a pre-trained diffusion model (teacher) to generate training pairs for the consistency model (student).
Algorithm:
- Sample and
- Generate noisy sample: where
- Use the pre-trained score model to estimate:
- Minimize the consistency loss:
where:
- represents the pre-trained score model parameters
- is an exponential moving average of :
- is a positive weighting function, typically
- is a distance metric (e.g., or LPIPS (learned perceptual image patch similarity))
1.3.2. Consistency Training (CT)
Consistency Training learns consistency models from scratch without relying on pre-trained diffusion models.
Algorithm:
- Sample , , and
-
Define adjacent points on trajectory:
- Minimize the consistency loss:
According to the experiments in the paper, they found,
- Heun ODE solver works better than Euler's first-order solver, since higher order ODE solvers have smaller estimation errors with the same .
- Among different options of the distance metric function , the LPIPS metric works better than and distance.
- Smaller leads to faster convergence but worse samples, whereas larger leads to slower convergence but better samples upon convergence.
1.3.3. Target Network Updates
Both training methods employ a target network to stabilize training. The target parameters are updated via exponential moving average:
where is the decay rate. This prevents the consistency loss from becoming degenerate (where the model simply outputs the same value for all inputs).
1.4. Sampling and Inference
1.4.1. Single-Step Sampling
The most straightforward sampling approach is single-step generation:
The key insight is that has learned to map any point on the diffusion trajectory back to the clean data, so we can start from pure noise and get the final result immediately.
1.4.2. Multi-Step Sampling
While single-step sampling is fast, multi-step sampling can improve quality by alternating denoising and noise injection steps:
This process allows trading computational cost for sample quality, similar to how diffusion models work but with far fewer steps.
1.5. Improved Consistency Training (iCT)
- Removing EMA for the Teacher Network: The authors identified a theoretical flaw where using Exponential Moving Average (EMA) for the teacher network provides no useful training signal for the data distribution. By setting the EMA decay rate to zero (), they ensure the teacher and student parameters are correctly aligned, which significantly boosts performance.
- Pseudo-Huber Loss: To replace the biased and computationally expensive LPIPS metric, the authors adopt the Pseudo-Huber loss, defined as . This simple metric is robust to outliers, reduces training variance, and ultimately surpasses the performance of LPIPS-based training.
- Improved Discretization Curriculum: The paper demonstrates that model performance scales with the number of discretization steps () according to a power law. Based on this, they propose a new exponential curriculum for —doubling at fixed intervals—which empirically yields the best sample quality.
- Lognormal Noise Schedule: The default training procedure over-emphasizes high noise levels. The authors introduce a lognormal noise schedule to focus training on more critical low-to-mid noise ranges, leading to a notable improvement in sample quality.
- Optimized Hyperparameters: The work also introduces an improved weighting function (), increased dropout rates, and fine-tuned noise embeddings to further enhance performance.
1.6. Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models (sCM)
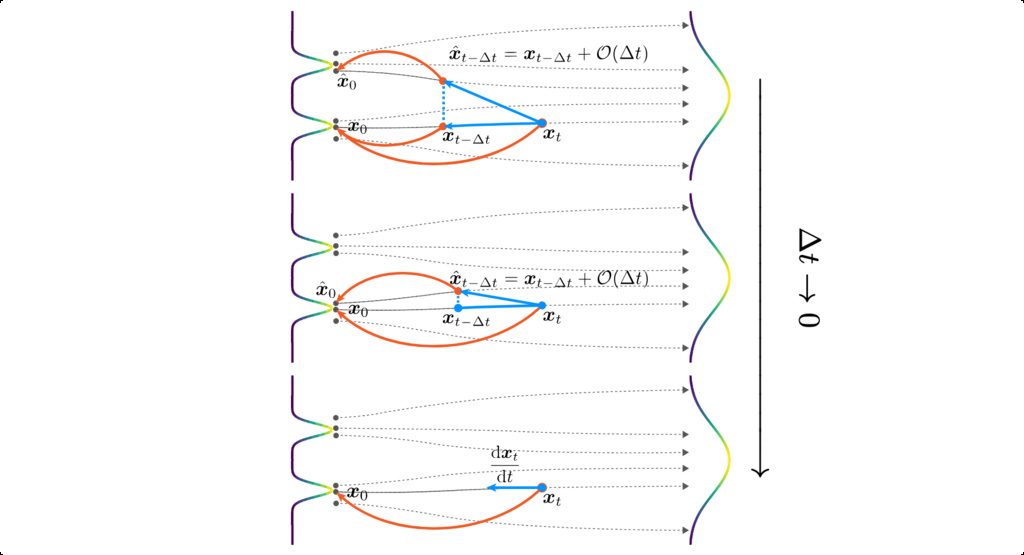
-
Discrete-time CMs The training objective is defined at two adjacent time steps with finite distance:
where denotes , is the weighting function, is the distance between two adjacent time steps, and is the distance metric.
-
Continuous-time CMs We use and take , we can show that
where is the tangent of at along the trajectory of the PF-ODE .
Notably, continuous-time CMs do not rely on ODE solvers, which avoids discretization errors and offers more accurate supervision signals during training. However, previous work found that training continuous-time CMs, or even discrete-time CMs with an extremely small , suffers from severe instability in optimization. This greatly limits the empirical performance and adoption of continuous-time CMs.
To address the stability issues of continuous-time consistency models, researchers introduced TrigFlow - a simplified theoretical framework that unifies EDM (Elucidated Diffusion Models) and Flow Matching while significantly simplifying the mathematical formulation.
TrigFlow uses trigonometric functions to parameterize the diffusion process, making the mathematical expressions much cleaner and more stable. The key insight is to replace the complex EDM coefficients with simple trigonometric functions:
Diffusion Process:
where and .
Diffusion Models and PF-ODE:
where is a neural network with parameters , and is a transformation of to facilitate time conditioning. The corresponding PF-ODE is given by
Training Target:
Consistency Model Parameterization:
1.6.1. Stabilization Techniques
The TrigFlow framework incorporates several key stabilization techniques:
- Identity Time Transformation: Using instead of the complex logarithmic transformation from EDM prevents numerical blow-up as .
- Positional Time Embeddings: Avoiding high-frequency Fourier embeddings in favor of positional embeddings reduces gradient instability.
- Adaptive Double Normalization: Modifying the AdaGN layers to use pixel normalization for both scale and bias terms improves training stability.
- Tangent Normalization: Explicitly normalizing the tangent function to control gradient variance.
1.6.2. Training Objective
To make the training objective more stable, we modify the training objective to:
where is an adaptive weighting function that balances the loss across different time steps.
1.7. Consistency Trajectory Models
where is the probability distribution of the solution of the reverse-time stochastic process from time to zero, initiated from . Here, is the denoiser function (Tweedie's Formula), an alternative expression for the score function . In practice, the denoiser is approximated using a neural network , obtained by minimizing the DSM loss .
Sampling from DM involves solving the PF ODE, equivalent to computing the integral
where is sampled from a prior distribution approximating . Decoding strategies of DM primarily fall into two categories: score-based sampling with time-discretized numerical integral solvers, and distillation sampling where a neural network directly estimates the integral.
- Score-based Sampling: Despite recent advancements in numerical solvers, further improvements may be challenging due to the inherent discretization error present in all solvers, ultimately limiting the sample quality obtained with few NFEs.
- Distillation Sampling: Distillation models' multistep sampling approach exhibits degrading sample quality with increasing NFE, lacking a clear trade-off between computational budget (NFE) and sample fidelity. Furthermore, multistep sampling is not deterministic, leading to uncontrollable sample variance.
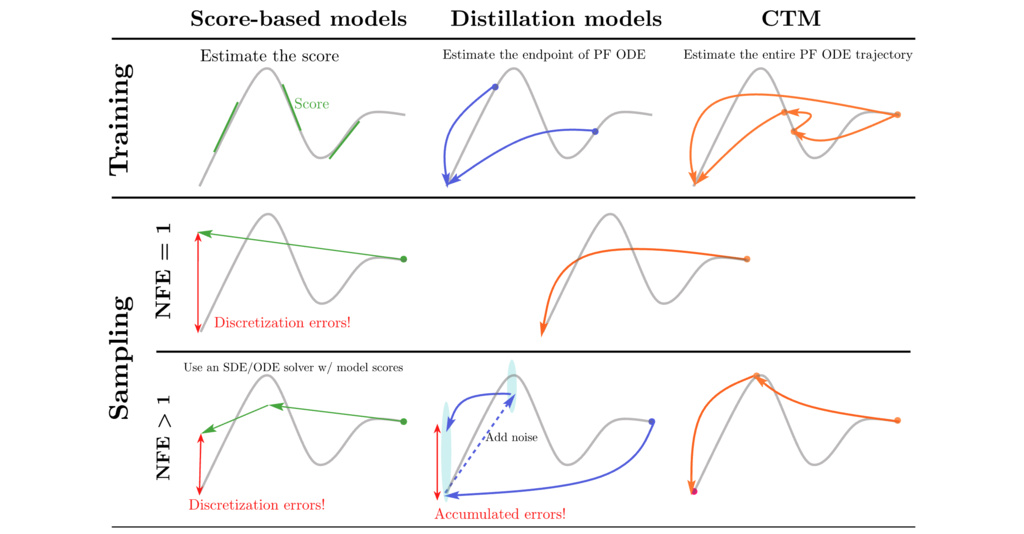
1.7.1. Trajectory Mapping Function
CTM learns a trajectory mapping function that maps a point at time to the corresponding point at time along the same ODE trajectory.
Key properties:
- Consistency: (identity mapping)
- Transitivity: for any intermediate time
- Boundary condition: where follows the forward process
For stable training, we express as a mixture of and a function (inspired from the Euler solver):
where and we approximate using with a neural network. A critical insight is that this parameterization also allows access to the score function. By taking the limit as approaches , we find:
This means that CTM not only learns to make long jumps along the trajectory but also learns the infinitesimal jumps, i.e., the denoiser/score function. This property unifies score-based and distillation approaches within a single model.
1.7.2. CTM Training
CTM training combines a distillation loss with powerful auxiliary losses that provide direct training signals from the data, allowing the student (CTM) to surpass the teacher (diffusion model).
-
Soft Consistency Loss: The primary loss is a distillation loss where the CTM's jump prediction is matched against a target generated by a pre-trained teacher model. To make this efficient and effective, CTM uses soft consistency matching. The model is trained to enforce , where is a random time between and . This serves as a flexible interpolation between local consistency (, distilling a single step) and global consistency (, distilling the entire interval).
-
Auxiliary Losses:
- Denoising Score Matching (DSM) Loss: Since CTM can estimate the denoiser via , it is explicitly trained with a DSM loss: . This regularizes the model to accurately learn the score function, which is vital for precision and for enabling score-based sampling methods.
- Adversarial (GAN) Loss: To further enhance sample quality and refine details, an adversarial loss is added, similar to VQGAN.
The final loss is a weighted sum: .
1.7.3. -Sampling
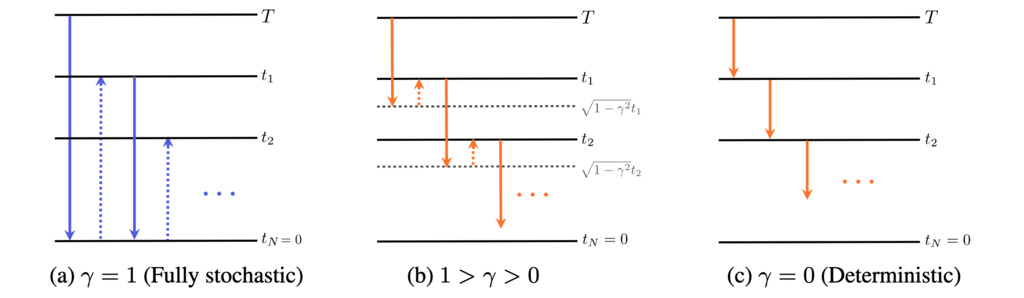
CTM's ability to travel between any two points in time enables a novel and flexible sampling scheme called -sampling, controlled by a parameter . A sampling step from to involves:
- Denoise: Jump from to an intermediate time using the learned function .
- Noisify: Add a controlled amount of noise to reach the noise level corresponding to time .
This process offers a spectrum of sampling behaviors:
- (Deterministic): The process is fully deterministic. It follows the PF ODE path directly, avoiding the discretization errors of traditional ODE solvers and the error accumulation of CM's multistep method. Sample quality consistently improves with more NFEs.
- (Fully Stochastic): This recovers the multistep sampling method used in Consistency Models. However, this approach suffers from error accumulation, and sample quality can degrade as NFE increases.
- (Hybrid): This provides a tuneable level of stochasticity, generalizing the stochastic samplers found in models like EDM.
1.8. Flow-Anchored Consistency Model (FACM)
Continuous-time Consistency Models (CMs) promise efficient few-step generation but face significant challenges with training instability. We argue this instability stems from a fundamental conflict: by training a network to learn only a shortcut across a probability flow, the model loses its grasp on the instantaneous velocity field that defines the flow.
1.8.1. The Source of Instability: Losing the Flow Anchor
The practical implementation of the continuous-time CM objective via the training target is notoriously unstable. The core of this instability lies in the target's self-referential nature, creating two fundamental, intertwined problems:
-
Missing Instantaneous Velocity Field Supervision: The target explicitly depends on the ground-truth instantaneous velocity . The CM objective, however, only enforces a loss on the final prediction (the average velocity). There is no explicit mechanism to ensure that the model's learned dynamics remains faithful to the underlying instantaneous velocity field .
-
Self-Referential Derivative Estimation: The network is required to estimate its own derivative. Even if the network is pre-trained and initially provides a good approximation of the instantaneous velocity, the CM objective alone provides no continuous supervision to maintain this alignment.
1.8.2. Flow-Anchoring Principle
Stability can be achieved by explicitly anchoring the model in the very flow it is shortcutting. The most direct way to achieve this Flow-Anchoring is to re-introduce the explicit training of the instantaneous velocity field that defines the flow.
1.8.3. FACM Training Strategy
FACM employs a simple yet effective training strategy that mixes two complementary objectives:
1.8.3.1. Flow Matching Loss (The Anchor)
This loss component anchors the model by regressing its output towards the instantaneous velocity :
where
1.8.3.2. Consistency Model Loss (The Accelerator)
This component acts as an accelerator, training the model to learn the generative shortcut. We interpret the consistency condition as a fixed-point problem:
First, we compute the consistency residual of the stop-gradient model :
Then form a perturbed target:
This formulation provides a stable, interpolated learning target between the current model's output and the ideal consistency target. The final CM loss component uses a norm L2 loss, , and is modulated by weighting functions and :
It is important to note that our specific choices for weighting and loss functions are designed to accelerate convergence, not as prerequisites for stability, which is guaranteed by the Flow-Anchoring principle.
1.8.4. Implementation of the Mixed Objective
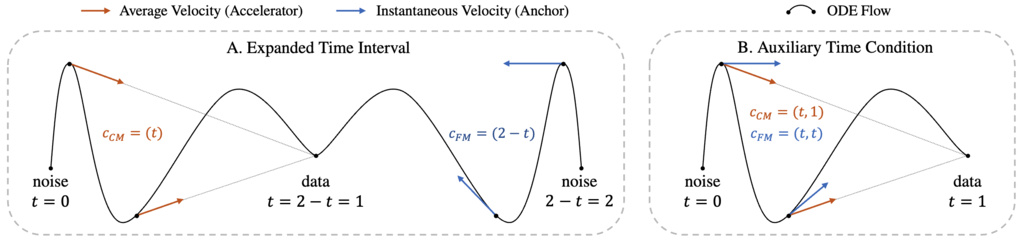
1.8.4.1. Expanded Time Interval Strategy
We innovatively propose leveraging an expanded time domain to distinguish between the two tasks:
- CM Task: Operates on the interval , using
- FM Task: Maps to the alternate interval by setting
This mapping ensures continuity at the boundary :
1.8.4.2. Auxiliary Condition Strategy
Alternatively, we can introduce a second time variable , making the model's full conditioning a tuple of :
- : Model learns CM task (average velocity from to )
- : Model learns FM task (instantaneous velocity at )
